もしみなさんがまだSEOに着手していないなら、デジタルマーケティングプランにおいて優先すべきはオーガニック検索トラフィックです。インターネットのトラフィックの半分以上は検索エンジンから来ています(60%に達しているかもしれません)。オーガニック検索トラフィックはオンライン販売でも非常に重要です。SEOの重要性は当然分かっていても、実際にはどこから手をつければいいのでしょうか? SEOのすべては、検索エンジンロボットにWebサイトを見つけてもらい、クロール、インデックスしてもらうことから始まります。
記事では、SEOの技術的なことに加え、オンページSEOについて、またどうしたらGoogleやBing、その他の検索エンジンの注意を引けるのかを説明します。
Step 1:オンページSEO
検索エンジンに見つけてもらうための最初のステップは、検索エンジンにとって分かりやすい仕様でページを作成することです。
Webサイトのターゲット層を明確にし、どのキーワードを使って見込み客が自分のWebサイトを見つけるのか推測します。つまり、どのようなキーワードで検索順位を上げたいのか決めることです。もっともお勧めなのは、検索トラフィックで非常に多く説明に使われている長めのキーワードを狙うことです。競争率が低く(高順位になりやすい)、検索者が購買意向の強いユーザー層(in-market)であると考えられるからです。彼らはたくさんクリックしてくれるという嬉しい特徴があり、クリック率が高く、コンバージョン率も高いのです。
Webサイトで公開されている無料のキーワードリサーチツールがたくさんあります。
狙っているキーワードがあれば、こうしたツールを使ってページの土台を最適化します。キーワードをページ要素のツールの中に入れてみます。
titleタグ:titleタグはもっとも重要なページ要素の1つで、検索エンジンはこれを見て関連ページを決定します。titleタグのキーワードは検索エンジンにページを見てどのような情報が得られるのかを伝えます。titleタグは60字以下にし、最初に一番重要なキーワードを使います。titleタグの正しい使い方は以下のとおりです。
<title>Page Title</title>
meta description:meta description自身は、検索エンジンがページを見るときにそれほど影響を与えるものではありません。meta descriptionによって変わるのは、人間が検索結果に表示されたタイトル、URL、説明といった検索の紹介文を読むときです。最適なmeta descriptionだとユーザーがWebサイトに訪問してクリック率を上げるので、検索順位に大きな影響を及ぼします。meta descriptionでキーワードを使うと太字で紹介文に表示されるので、ここでもキーワードを入れます。
ページコンテンツ:当然ながら、ページのコンテンツにはキーワードを入れてください。とはいえ詰め込みすぎず、ページ内で3~5回使うようにします。同様に、同義語とLSI(Latent Semantic Indexing)キーワードもいくつか入れます。
ブログを追加:より典型的なコンテンツマーケティングのSEOのメリットとは別に、ブログはWebサイトがクロールされ、インデックスされるよう精力的に働いてくれます。ブログがあるサイトには以下の結果が表れています。
サイトにページやコンテンツの追加、更新をすると、検索エンジンがより頻繁にクロールされるようになります。
Step 2: テクニカルSEO
Robots.txt
ターゲットのキーワードに対するオンページのSEO要因を最適化したあとは、GoogleにWebページを訪問してもらえる技術面に取り掛かります。robots.txtファイルを使うと、検索エンジンのクローラはサイト内を進みやすくなります。robots.txtファイルはとても単純で、Webサイトのルートディレクトリの中にあるシンプルなテキストファイルです。利用者エージェントがどのファイルにアクセスしているかを示すコードが書いてあります。一般的には以下のような感じです。
User-agent:*
Disallow:
最初の行は、想像の通り単一のユーザーエージェントを定義します。この場合、「*」がすべてのロボットを意味します。Disallow(拒否)の行を空白のままにすれば、ロボットはサイト全体にアクセスします。単一のユーザーエージェントに複数のdisallow行を追加できますが、URLごとに別のdisallow行を作成しなければなりません。そのためGooglebotが複数ページにアクセスするのをブロックしたいときは、複数のdisallow行を追加する必要があります。
User-agent: Googlebot
Disallow: /tmp/
Disallow: /junk/
Disallow: /private/
各ロボットのページアクセスをブロックしたい場合にはdisallow行を追加してください。またrobots.txtファイルを使ってロボットがPowerPointやPDFなどのファイルにクロールしないようにすることもできます。
User-agent:*
Disallow: *.ppt$
Disallow: *.pdf$
サイト全体ですべてのロボットをブロックするには、スラッシュを追加します。
User-agent:*
Disallow: /
サイトの構築中やデザインの変更中は、すべてのロボットがサイト全体にアクセスしないようブロックするのがお勧めです。サイトの稼働中はクローラへのアクセスを復活させます。でないとインデックスされません。またSchema.org仕様のマークアップへのアクセスをブロックしていないことも確認ください。ブロックしているとGoogleのリッチ検索結果に表示されません。
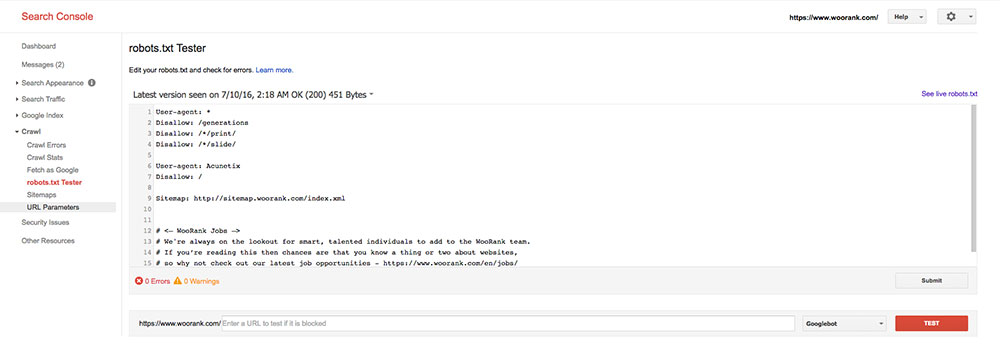
Google Search Consoleのアカウントがあれば、「クロール」の項目で「robots.txtテスター」にファイルを送信してテストできます。
XMLサイトマップ
XMLサイトマップはrobots.txtファイルと同様、サイトのディレクトリに格納されるテキストファイルです。このファイルには、サイトのURLすべてと、URLの重要性、最終更新日、更新頻度、外国語ページ版の有無といった、追加情報が少し含まれています。XMLサイトマップがあると検索エンジンはWebページをより効率的にクロールできます。サイトマップには次の要素が含まれています。
- <urlset>:サイトマップの最初と最後の行。現在の標準のプロトコル
- <url>:サイト内の各URL用の親タグ。</url>で閉じる
- <loc>:ページの場所を示す完全URL。一貫して完全な形式のURLを使うことが非常に重要(http vs. https., wwww.example.com または example.comなど)
- <lastmod>:最終更新日。YYYY(年)-MM(月)-DD(日)形式を使う
- <changefreq>:ファイル変更の頻度。ページを頻繁に更新すればするほど、クロールされる頻度も上がる。ここで設定した頻度ほど変更されていなければ、検索エンジンは嘘を見破って無視する
- <priority>:サイト内でのページの重要性。0.1から1.0までで示す
- <xhtml:link>:ページの代替バージョンの情報を提供
上にあげた要素を適切に記述すると、サイトマップは以下のようになるはずです。

大規模または複雑なWebサイトの場合や、自分でサイトマップを作成したくないときは、XMLサイトマップの生成に役立つたくさんのツールがあるので利用できます。
サイトマップは検索順位を上げるのに直接効果があるわけではありませんが、サイトマップがあると検索エンジンがWebサイトとすべてのURLを見つけやすくなるため、検索順位が上がりやすくなります。
Google Search Consoleから直接サイトマップを送信して、より迅速に実行します。「クロール」の下にある「サイトマップ」に行き、「サイトマップの追加/テスト」をクリックします。Bingのweb マスターツールでも同じことができます。こうしたツールを使って、Webサイトがインデックスされるのを妨げている可能性のあるサイトマップ内のエラーを確認します。
Step 3: オフページSEO
常に最短ルートでWebサイトのURLを検索エンジンに直接送信できます。WebサイトをGoogleに送信するのは簡単です。Google Search Consoleのページで、URLを入力、キャプチャを入力して人間であることを証明し、送信リクエストをクリックします。アカウントを持っていたらSearch Consoleからも送信できます。Bingの場合もアカウントが必要ですが、web マスターツールを使ってWebサイトを送信できます。クロールエラーを使って、クローラをブロックしている可能性がある問題を見つけます。
検索エンジンのクローラが、URLを取得して、Webサイトをより簡単に見つけられるようにします。ソーシャルメディアページにWebサイトのリンクを貼ります。これは検索結果の順位に直接影響しませんが、Googleはソーシャルメディアのページをクロールしてインデックスすると、リンク先も確認します。Google+のアカウントがあるとGoogleのリッチスニペットに表示する会社情報を取得するrel=”publisher” タグを使えるので非常に重要です。
YouTubeのアカウントがあれば、新しいWebサイトの特色を説明したショートビデオを投稿したり、ビデオの説明にリンクを追加します。Pinterestを利用していたら、URLと説明をつけて高解像度のスクリーンショットをピンします(説明にキーワードを使うのを忘れずに)。
オフページSEOの最後の決め手は少し手がこんでいますが、URLをWebディレクトリに送信します。WebディレクターはWebサイトに簡単な被リンクを増やすというかつて一般的だったSEO対策をしていました。しかし問題は、こうしたサイトの多くがたくさんのスパムとされるコンテンツを含み、ユーザーに有用性の低い情報を与えたことでした。そこで、URLを質の低いディレクトリに送信することは、有害無益になったのです。
ブログのディレクトリはちょっとだけ検討して、権威性の高いディレクトリを選びます。たとえばトップWebディレクトリの1つとされるDMOZや、RSSフィードや適切な分量のコンテンツがあればAlltopなどを検討します。加えて、信用度の高いディレクトリリストにするために、信用できるオンラインリソースを確認してください。
最後に
オンラインで見つけてもらうことがSEOの最終的な目標です。しかし、人間に見つけてもらう前に、検索エンジンに見つけてもらわなくてはなりません。サイトを公開し、なにもしないで、リラックスして、誰かが来るのを待つことはいつでもできますが、これでは最良の結果とはならないでしょう。記事で紹介したメソッドで、ページのクローリングとインデクシングを改善すれば、より速く検索順位を上げられ、見込み客を得られるでしょう。
※本記事はWooRankのSEOシリーズの1つです。SitePointでの記事公開に協力してくれたパートナーへのサポートに感謝します。
(原文:How to Get Your Site Indexed by Googl)
[翻訳:和田麻紀子]
[編集:Livit]
本記事はアフィリエイトプログラムによる収益を得ている場合があります