




スーパーコンピューターの系譜では、主にアメリカのシステムを取り上げており、そこに時々イギリスが混じる(前回のMeikoなど)といった具合だが、この時期米英だけがスパコンに取り組んでいたわけではなく、日本もまた積極的に参加していた。
このあたりの話、概略はWikipediaなどを見ていただければわかるかと思う。この話を真面目に書くとそれだけで連載何本分かになるので、とりあえず今回は触れないでおく。
もちろん他の国がなかったわけではなく、ヨーロッパでもいくつかの試みがなされていた。今回ご紹介するのはそのうちの1つ、ドイツのSUPRENUMである。

SUPRENUM-1
SUPRENUM、ドイツ語での正式名称はSUPerREchner fur NUMerische Anwendungen、英語ではSuper-Computer for Numerical Applicationsだが、ドイツ語表記の短縮形がSUPRENUMになり、これで一般的に通用する。これはドイツの産学協同プロジェクトとして1986年にスタートした。ちなみに参加団体は以下のとおり。
| 研究機関 |
|---|
| GMD(ドイツ国立情報処理研究所 現フラウンホーファー研究機構)傘下の2つの研究施設 KfA(ユーリッヒ原子力研究所 現ユーリッヒ研究センター) KfK(カールスルーエ原子力研究所 現カールスルーエ研究センター) DLR(ドイツ航空宇宙センター) |
| 大学 |
| ダルムシュタット工科大学 ライン・フリードリヒ・ヴィルヘルム大学ボン(ボン大学) ブラウンシュヴァイク工科大学 ハインリッヒ・ハイネ大学 フリードリヒ・アレクサンダー大学エアランゲン=ニュルンベルク |
| 企業 |
| シーメンス社KWU ドルニエ航空機製造(現フェアチャイルド) Krupp Atlas Elektronik GmbH(現Atlas Elektronik GmbH) Stollmann GmbH(現Stollmann Entwicklungs- und Vertriebs GmbH) |
これにSuprenum GmbHが加わった。SUPRENUM GmbHは名前の通り、SUPRENUMを製造・販売する目的で設立された会社であり、まずはPhase-1としてSUPRENUM-1の製造に取りかかった。
MIMDのプロセッサーにSIMDのベクトル処理能力を加えた
SUPRENUM-1
SUPRENUM-1はMIMDベースの超並列構成のシステムを目指して構築されることになった。もっとも単純なMIMDというよりもMIMD+ベクトルという、おそろしく重厚なシステムである。
SUPRENUM GmbHのKarl Solchenbach氏が1990年に発表した“SUPRENUM: Architecture and Applications”という論文によれば、コスト性能比を高めるためにSUPRENUMはMIMDの分散メモリー方式のプロセッサーにSIMDのベクトル処理能力を加えたもの、という説明がなされている。
論文は以下のとおり。「100MFLOPSの演算性能を実現する、もっともコスト効率の良いメカニズムはベクトルである。一方スーパーコンピューターをターゲットとしたMIMDのマルチプロセッサーは、単純なFPUユニットを利用してベクトルと同じ性能を得ようとしている」
「それゆえ、パラレリズムを2つのレベルに分け、ローカルではベクトルプロセシング、グローバルでは細粒度のMIMDを構成するSIMD/MIMDのミックスなマルチプロセッサーが一番パワフルなアーキテクチャーとなる」という。いや、それはそうなんだけど……という話である。
その話は後にして、SUPRENUM-1の中身はどんな感じかというと、下の画像がシステム全景である。16個のコンピューティングクラスターが2次元トーラスで総合接続され、次いでにUnixゲートウェイと接続される仕組みだ。各々のトーラスリング(SUPRENUM-busという名称だそうだ)は200Mbpsの速度となっている。
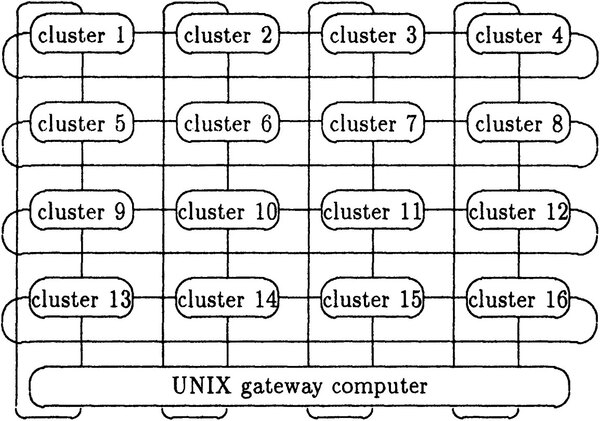
SUPRENUM-1のシステム概要。OSそのものはUnixゲートウェイの外側で動作するので、SUPERNUMのクラスター/ノードは完全なアクセラレーターとしての動作になる
画像の出典はKarl Solchenbach氏の“SUPRENUM: Architecture and Applications”より。
コンピューティングクラスターの中身は、下の画像のように、320MB/秒のクラスターバスという、おそらく共有バスの上に16個のノード+αが接続された形である。
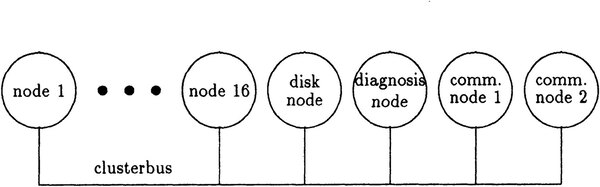
disk nodeには最大で4台、4.8GBのHDDが接続されたそうだ。comm.nodeはSUPERNUM busのI/Fで、縦方向と横方向のそれぞれに1つづつ用意された
画像の出典はKarl Solchenbach氏の“SUPRENUM: Architecture and Applications”より。
このクラスターバスの実体がなにかはよくわからないのだが、時期や速度を考えると、VMEないしFutureBusの独自拡張版だったのではないかという気がする。
時期的にはVME320はもとよりFutureBus+ですら間に合わないが、VMEのままでは性能はピークで40MB/秒程度でしかない。ただ、後述するようにカードとコネクターは明らかにVMEのようなので、おそらく信号線の増強などで独自にバス幅や信号速度を増やして対応したものと思われる。
(→次ページヘ続く 「20本のキャビネットが並ぶ巨大なシステム」)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第886回
PC
CFETの足を引っ張るPMOSを救え! imecが提案する新絶縁層と、あえて精度を緩める「Notch Alignment」の妙手 -
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 - この連載の一覧へ













ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")








ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












