「見える」からわかる!システム障害の原因をあぶり出すテク 第2回
迅速な障害原因の切り分けを行い、効率的な対応を実現するためのツール
ネットワーク?サーバー?QoEダッシュボードで障害原因が見える
2015年07月14日 14時00分更新

実際にアプリケーション/ネットワークの状態を「見て」みよう
では実際に、QoEダッシュボードを使って冒頭に挙げたトラブルの原因を探ってみることにしよう。ここでは「アプリケーション応答時間」と「ネットワーク応答時間」という2つのウィジェットに注目する。
アプリケーション応答時間(ART:Application Response Time)は、クライアントとサーバーが3Wayハンドシェイクを実行したあと、サーバーがクライアントに最初のデータを送信するまでの平均時間を示すウィジェットだ。一方、ネットワーク応答時間(NRT:Network Response Time)のほうは、3Wayハンドシェイクそのものの平均応答時間を表している。簡単に言えば、この2つを見比べることでレスポンスの遅い原因がアプリケーションなのか、ネットワークなのかがわかる。
まず「ファイル転送が遅くなった」というFTPについて見てみると、ネットワーク応答時間のウィジェット下部の一覧に赤く警告が出ている。グラフに目をやると、この数時間で急激に応答時間が遅くなったようだ。
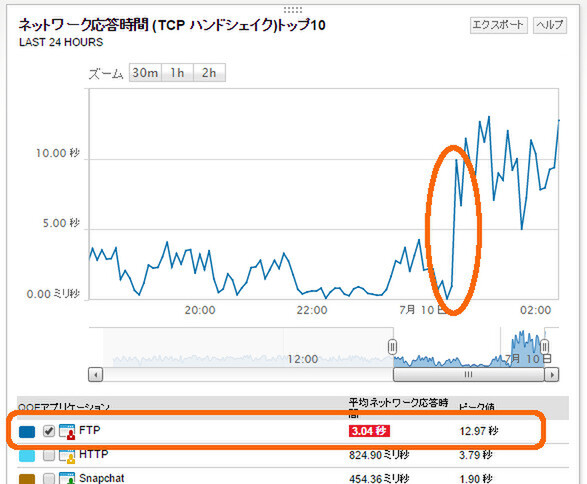
「ネットワーク応答時間(TCP ハンドシェイク)」のウィジェットでは、FTPの応答時間が遅いという警告が出ている。グラフでもそれがはっきりとわかる
つまり、ダッシュボードを一目見るだけで、「原因はネットワーク側にあるらしい」ことが簡単にわかったわけだ。
さらに、ウィジェットの「FTP」の項目をクリックすると、ドリルダウンしてFTPだけの詳しい状況を調べることができる。下に示す画面では、あるFTPサーバーとの通信で大きなパケット損失が発生しており、やはり何らかのネットワークトラブルであることがわかる。あとはネットワーク担当者が、ルーターやスイッチの設定を確認し、修正してやればよさそうだ。
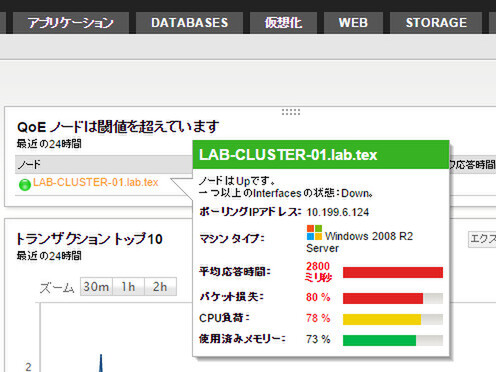
ドリルダウンしてFTPだけの状況を詳しく調査。大量のパケットロスが発生しているようだ
それでは、もう1つの「業務アプリケーションが重い」というトラブルも原因は同じなのだろうか。しかし、再度ネットワーク応答時間のウィジェットを見てみても、SQLの応答時間は300ミリ秒以下で安定しており、問題はなさそうだ。
一方で、アプリケーション応答時間のウィジェット下部では「MS SQL」に警告が出ている。グラフを見ると、一定ではあるものの常に3秒以上の応答時間がかかっている。つまり、FTPとは逆に、こちらは「データベースサーバー側に原因がある」ことがわかった。したがって、あとの対処作業はサーバー担当者やデータベース担当者が行うことになる。
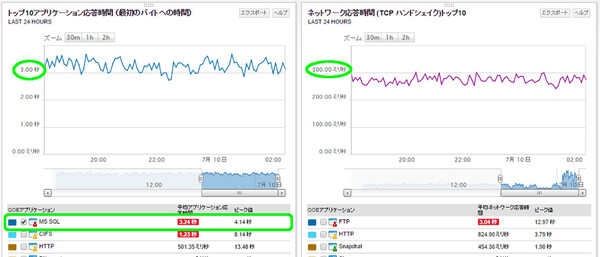
両グラフでSQLサーバー(MS SQL)の応答時間を見ると、ネットワークではなくアプリケーション(データベースサーバー)側に問題があることがわかる
まずは「可視化」が効率的な障害解決の第一歩
このように、ダッシュボードを見るだけで簡単に障害原因の切り分けができれば、そのあとの具体的な復旧作業へとスムーズに進むことができる。本来トラブルに関係のない担当者を巻き込むこともなく、障害復旧までの時間も短縮できるだろう。
そのためには、前回記事で指摘したとおり、運用管理の「サイロ化」を解消し、横の連携を実現する情報共有の仕組みが必要だ。統合的な監視ツールを使うメリットの1つがそこにある。
また、ふだんの状態(正常な状態)が常に記録され、可視化されているからこそ、異常が生じれば(あるいはその前兆が)すぐにわかる。「正常な反応」と「異常な反応」を繰り返すような障害では、ある特定の時点だけを見ても異常に気づかない可能性もある。
いずれにしても、ネットワークやシステムの状態が「可視化」されていることで、トラブルの早期解決が可能になることがおわかりいただけただろう。次回以降も引き続き、ある特定のトラブルが発生した際に、それがソーラーウインズの監視ツール上でどのように「見える」のかを検証していきたい。
※注:本記事中で使用しているグラフやデータはデモ環境のものであり、実際の通信環境とは異なります。
(提供:ソーラーウインズ)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第7回
デジタル
「QoEダッシュボード」と「AppStack」でトラブル解決してみる -
第6回
デジタル
アプリ障害の原因はインフラのどこに?「AppStack」が簡単解決 -
第5回
デジタル
適切なNW増強計画のために「NTA」でトラフィック量を可視化 -
第4回
デジタル
「UDT」で持ち込みデバイスのネットワーク接続を監視する -
第3回
デジタル
何十台ものネットワーク機器設定、その悩みを「NCM」が解消する -
第1回
デジタル
なぜ、いま運用管理の“バージョンアップ”が必要なのか - この連載の一覧へ
")





の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")












