「見える」からわかる!システム障害の原因をあぶり出すテク 第2回
迅速な障害原因の切り分けを行い、効率的な対応を実現するためのツール
ネットワーク?サーバー?QoEダッシュボードで障害原因が見える
2015年07月14日 14時00分更新

ユーザーからの問い合せはいつも「あいまい」
●今月のトラブル発生!
「原因はわからないんだけど、さっきからFTPサーバーへのファイル転送がいつもより遅いんだよね。そういえば業務アプリも重いような気がするし、何かトラブルが起きてるんじゃないの?」
このように、ユーザーからIT管理者への問い合わせはいつも「あいまい」だ。ユーザーとしてはアプリケーションが快適に使えさえすればそれでいいのだが、管理者がトラブルの原因を調査し、突き止め、解決するためには、こうしたあいまいさが“大敵”となる。
たとえば上述の例の場合、原因はネットワークかもしれないし、サーバーかもしれない。あるいはアプリケーションやデータベースの不具合かもしれない。FTPと業務アプリという2つの障害の原因が1つなのか、別々なのかもわからない。いわゆる「障害原因の切り分け」がまったくできていない状態だ。
原因の切り分けは、さまざまな手がかりを基に段階的に進めることになるが、まずはネットワーク担当者、サーバー担当者、データベース担当者……と全員が総掛かりであらゆるログやステータスを調べ、「(何かは不明だが)何らかの異常」が起きていないかどうかを確認していくことになる。いかにも“暗中模索”という感じで、まったく効率的ではないし、原因を突き止めるまでには時間がかかるだろう。たとえシステムの構成要素ごとにリカバリー手順が用意されていたとしても、原因がわからなければ復旧はおぼつかない。
ソーラーウインズのQoEダッシュボードで「見える」
ソーラーウインズの「Network Performance Monitor(NPM)」は「QoEダッシュボード」という機能を搭載している。QoEは「Quality of Experience」、つまり「ユーザー体験品質」という意味で、文字どおり「何がユーザーの快適なシステム利用を妨げているのか」をわかりやすく示してくれるツールだ。
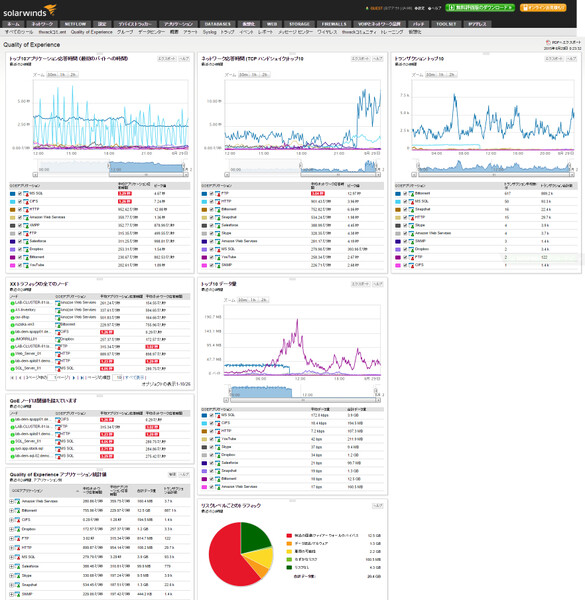
ソーラーウインズのNPMが備える「QoEダッシュボード」の画面。ブラウザから監視できる
QoEダッシュボードの特徴はまず、ネットワーク機器、物理/仮想サーバー、アプリケーションといった幅広いシステム構成要素のパフォーマンスやトラフィックの状態を、一画面上でまとめて可視化できることだ。これにより、ネットワーク/システムで何が起きているのかの全体像が一目で把握できるため、トラブルの原因がどこにあるのかが見つけやすい。
また、ネットワーク機器や物理/仮想サーバーから収集したデータだけでなく、ネットワークを流れるパケットを解析(DPI:ディープパケットインスペクション)することでアプリケーションを識別し、アプリケーションごとにパフォーマンスやトラフィックを可視化できる点も特徴だ。



QoEダッシュボードは、ネットワーク/サーバー/アプリケーションのさまざまな状態を示す「ウィジェット」(画面パーツ)により構成される
なお、ネットワーク機器や物理/仮想サーバーからの情報収集にはSNMPや各ベンダー独自のプロトコルを用いており、エージェントレスで実行できる。またアプリケーション情報の収集は、スイッチやルーターのミラーポートに解析サーバーを接続することでDPIが実行できるほか、サーバー/アプリケーション側にエージェントをインストールすることもできる。解析サーバー/エージェントとも同じデータが取得できるので、管理者やシステムの都合により使い分けることができる。
(→次ページ、実際にアプリケーション/ネットワークの状態を「見て」みよう)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第7回
デジタル
「QoEダッシュボード」と「AppStack」でトラブル解決してみる -
第6回
デジタル
アプリ障害の原因はインフラのどこに?「AppStack」が簡単解決 -
第5回
デジタル
適切なNW増強計画のために「NTA」でトラフィック量を可視化 -
第4回
デジタル
「UDT」で持ち込みデバイスのネットワーク接続を監視する -
第3回
デジタル
何十台ものネットワーク機器設定、その悩みを「NCM」が解消する -
第1回
デジタル
なぜ、いま運用管理の“バージョンアップ”が必要なのか - この連載の一覧へ
")





の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")












