




Intel MICでの性能向上事例を披露
LTE基地局がSandy Bridge上で動く?
まずアプリケーションについてだが、ここでは欧州の研究機関「CERN」を例にとって説明された。CERNの実験では毎秒4000万回にも上る粒子の衝突を観測するために、結果として毎年15~25PB(ペタバイト、1万5000~2万TB)のデータを処理する必要性がある。そのために、CERNに現在25万コアのインテルCPUを集積したコンピューティング・グリッドがあるとラトナー氏は述べた。
問題は、この25万コアにどうやって仕事をさせるかである。ここで紹介されたのがインテルの並列化ソフトウェア開発ツール「Intel Parallel Studio XE」で提供される、新しいマルチコア対応のライブラリだ。これを使うことでXeonベースのマルチコアシステムのみならず、Intel MICアーキテクチャーを混在したメニーコアクラスター環境でも、性能が向上することが紹介された。
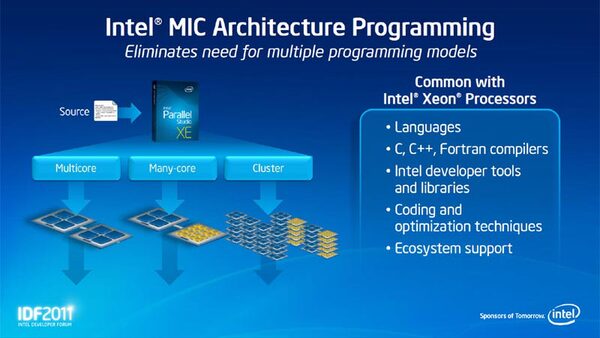
Intel MICでの並列化プログラミングは、「Cilk」と呼ばれるC言語の拡張が担っている。Cilkは1990年代からMITで開発されてきた、マルチスレッド環境での並列コンピューティング用の言語で。インテルはParallel Studio XEでCilkをサポートしており、Cilkを使うとさまざまなヘテロジニアス環境を意識することなくプログラミング可能である
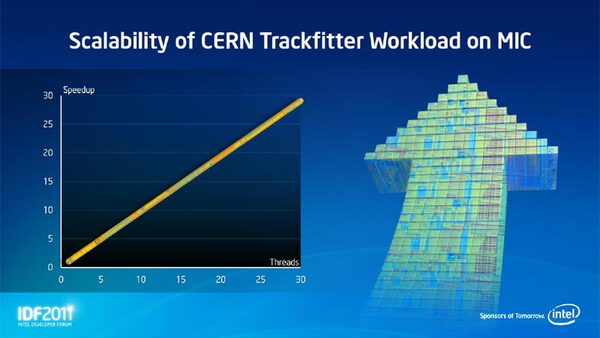
基調講演では、実際に物理シミュレーションをMICアーキテクチャー上で動かして、シングルコアと32コアで動作速度がまったく異なることを示した
重量級のシミュレーション以外にも、Intel MICは利用できるという説明では、 分散メモリキャッシュサーバー「memcached」を移植した例が示された。通常memcachedを使うと、最大で56万トランザクション/秒の処理が可能というレポートがある。一方MICアーキテクチャー上で48コアをフルに使った場合、80万トランザクション/秒を超える速度でキャッシュ要求を処理できるという。
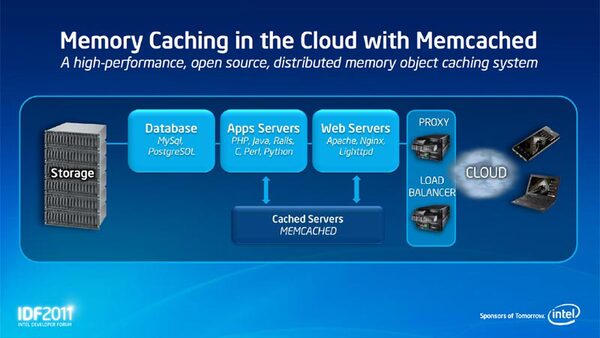
「memcached」はオープンソースベースの分散メモリキャッシュサーバー。国内でもはてなやmixiなど、さまざまなサイトで広く利用されている
ほかにも、JavaScriptがマルチコア環境で高速化されるデモなども披露され、HPC分野のみならず、広くマルチコアが効果的に使える環境が、普及しつつあることが示された。
また、マルチコアのもうひとつの例として示されたのが、「LTE」である。日本でもNTTドコモの「Xi」が始まるなど普及の兆しを見せているが、これの基地局をSandy Bridge上でソフトウェアで実装したというデモが披露された。

PHYなどは流石に無理だが、それ以外をすべてソフトウェアで実装したLTE基地局。利用しているのはSandy BridgeベースのXeonのようだが、細かいハードウェア構成は不明
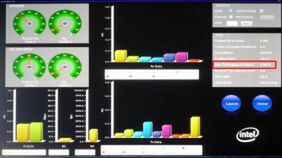
実際の転送例。最大スループットは約43Mbpsと示されている(赤枠内)

展示されていたLTEシステム。3つ並んだシャーシの一番左がLTEエミュレーターで、右2枚はそれぞれLTEの送受信を担っているのではないかと思うが、詳細は不明
実を言うとLTE基地局はずいぶん進化しており、以前のような「汎用CPU+DSP+FPGAの塊」から、「DSP内蔵のマルチコアCPU」に移行しつつある。だから、基地局をソフトウェアベースで構築することそのものは、それほど珍しくない。ただしスループットの観点では、専用アクセラレーターやDSPを内蔵しないと、十分なパフォーマンスは得にくいので(あるいは消費電力が過大)、全部をソフトウェアのみで処理というケースはほとんどない。
今回デモも最大で40Mbpsそこそこだから、決して高性能とは言えないし、これだけで基地局を構成するのは無理がある。だが、これまで実装されたことがなかったLTE基地局をx86ベースで実装して、実際に動いたという点では大きな前進である。今後Intel MICアーキテクチャーの性能が大きく上がると、こうした用途も実用的になるのかもしれない。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第3回
PC
IDFでインテルが明らかにした耐久性の高いSSD -
第2回
PC
2012年のノートPCは待機時間・消費電力がさらに減る -
第1回
PC
IDF初日の基調講演で注目はAndroidのAtomへの最適化 - この連載の一覧へ




















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")

































