




いまだ立ち上がりの遅いPCI Express 3.0
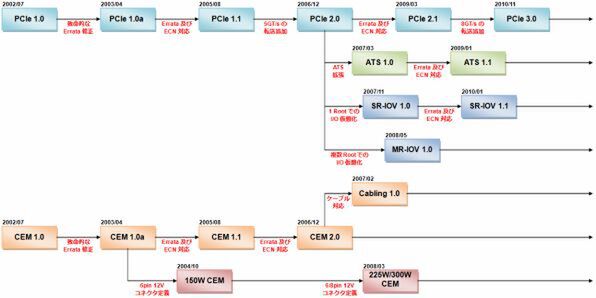
PCI Expressと関連規格のロードマップ
ロードマップに話を戻そう。Revision 1.0は2002年7月にリリースされたが、これにはいくつか致命的な問題があり、「準拠して作るとそもそも通信ができない」という代物だった。これを修正したのが、翌2003年4月に登場した「Revision 1.0a」である。2005年には、いくつかのECN(Engineering Change Notice、技術変更通知)を含めた「Revision 1.1」が登場した。
2006年3月には大きなアップデートとして、2.5GT/秒と5GT/秒の転送速度に対応した「Revision 2.0」が登場した。続く2009年3月に登場した「Revision 2.1」は、ECNとしてグラフィックスカードをGPGPU的に利用するといった「アクセラレーター」を利用する際の、性能向上につながるメカニズムをオプション扱いで追加するという大きな仕様拡張が行なわれている。当初この仕様拡張は、後述する仮想化関係のように別仕様になるという話だったが、最終的にBase Specificationに含まれることになった。
PCI Express最新のBase Specificationは、2010年11月にリリースされた「Revision 3.0」である。ここではついに信号速度が8GT/秒まで引き上げられている。しかしRevision 3.0では当初、10GT/秒を狙っていた。5GT/秒の2倍という単純な発想だが、実際に10GT/秒を狙おうとすると信号補正や基板実装の際にかなり困難をともなう(実現は可能だが高くつく)と判断された。そこで信号速度を1.6倍の8GT/秒に落としたわけだ。
それだけでは性能が1.6倍にしかならないので、Revision 1.x~2.xで利用されてきた8b/10bエンコードを放棄して、代わりに128b/130bエンコードを採用した。こちらの場合、8GT/秒での実際の転送速度は8×(128÷130)≒7.88Gbpsとなり、実質4GbpsだったRevision 2.xのほぼ2倍の帯域を利用できる計算になる。
もっともこの8GT/秒のPHYは、エンコード方法を変えたことためそのままではRevision 1.x/2.xとの互換性が保てなくなった。そのためRevision 3.0準拠のデバイスは、図5のように8GT/秒対応の物理層と2.5、5GT/秒対応の物理層の両方を内蔵し、実際の通信に応じて切り替えることが必須とされている。

図5 Revision 3.0の互換性確保の仕組み。8GT/秒と2.5・5GT/秒を切り替えて通信する
ところがこのRevision 3.0は、採用製品の立ち上がりがかつてないほど遅い。Revision 1.0/2.0の時は、仕様策定のだいぶ前からインテルが検証用プラットフォームをメンバー企業に提供していた。またグラフィックスカードベンダーも、試作品ながら早いタイミングでPCI Express対応GPUをリリースするなどしてフィールドテストを進めたために、仕様策定とほぼ同じタイミングで製品投入が始まっていた。
しかしRevision 3.0については、製品をそのまま検証用に使うという方針をインテルが打ち出した。その結果、次世代CPU「IvyBridge」のサンプルが出回るまでは、検証用プラットフォームが充実しないという状況になってしまい、現時点では最短でも2012年以降の普及になりそうだ。
面白いのは、むしろPCI Expressスイッチを製造しているベンダーの方が、Revision 3.0に熱心なことだ。そのためこれらの製品が先行して市場投入されつつあるのだが、スイッチだけあってもホスト側(チップセット)やデバイスが対応しないと意味がない。このホストやデバイスの対応が最短で2012年なので、本格普及はヘタをすると2013年になりそうである。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























