




「ディファレンシャル伝送」は、第99回のメモリー編でも説明している高速化の技術である。PCIは共有バスということもあり、ディファレンシャル伝送にはしにくく、結果「シングルエンデッド伝送」で構成された。しかしシングルエンデッド方式は速度を上げにくいという欠点がある。
一方PCI ExpressはPoint to Pointの接続方式なので、ディファレンシャル伝送を採用しても問題はなく、当初から2.5GT/秒(Giga Transfer/秒)まで速度を引き上げることに成功した。PCIは標準で33MHz、PCI-X 2.0でも最高で533MHzだから、単純計算で5倍~75倍の高速化ということになる。
PCI Expressで導入されたEmbedded Clockとは?
「Embedded Clockによるシリアルバス」は、これまでで一番新しい点かもしれない。PCIのような従来型の共有バスは、図3のような構成になっている。データ信号とは別にクロック信号も出力され、データはこのクロック信号に同期する形で出力される。
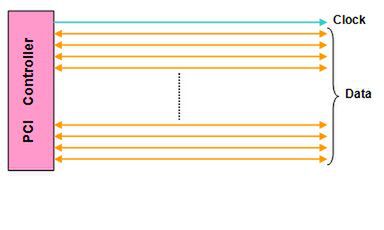
図3 PCIの配線構造
これらの信号は同じタイミングで送り出されて、同じタイミングで受け取れなくてはならない。そのため必然的に等長配線が必要になり、結果としてDDR2-SDRAMやDDR3-SDRAMの配線は大変なことになってしまう。そこでPCI Expressでは、「Embedded Clock」という方式を採用した。図4がその構造図である。
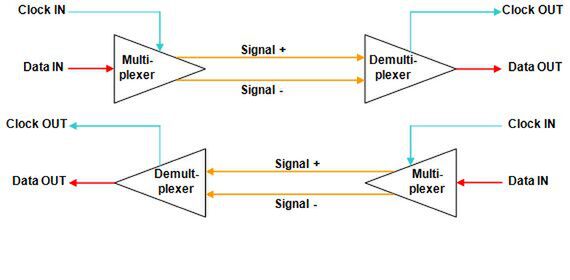
図4 PCI Expressの基本的な配線構造
まず送信したい元データを、Clock信号と一緒にマルチプレクサ(Multi-plexer)に入力して、元データとClock信号を混在させる。混在したデータはディファレンシャル伝送で送信される。受け取った側はそのデータをデマルチプレクサ(Demulti-plexer)で分解して、元データとClock信号を分離させてそれぞれ受け取る。
ちなみにこの信号の混在/分離には、「8b/10bエンコード」と呼ばれる方法が利用されている。これは8bit分の元データにClock信号を混在させて、10bitのデータを作るというものである。先にPCI Expressの信号速度に「GT/秒」という見慣れない表記を使ったのはそのためだ。
PCI Expressの場合、Gen1(1.x世代)では2.5GT/秒、Gen2では5GT/秒の速度で信号が伝送されるが、この信号とは「Clock信号を混在した10bit分のデータがどの位の速度で転送されるか」を示している。そのため2.5GT/秒の実際のデータの転送速度は、以下のようになる。
2.5×(8÷10)=2Gbps=250MB/秒
仮に2.5GT/秒で100%データを流せると、2.5Gbps=312.5MB/秒で転送できる計算になるので、この差がEmbedded Clockの分になる。ちなみにPCI-SIGが転送速度の表記について、GHzやGbps、MB/秒などを使わずにGT/秒の単位を使っているのは、2.5GHzと表記するとあたかも2.5Gbps=312.5MB/秒のデータ通信ができると誤解されやすいので、それを防ぐためにという話であった。
こうした仕組みにより、PCI Expressでは1レーンあたり4本の信号線(上り下り各2本)で、片側あたり250MB/秒の帯域を確保できるようになった。PCIが信号+アドレスだけで60本以上の信号線を必要としていたのに比べると、大幅な配線数削減と性能向上が実現できたわけだ。厳密に言えば、PCI Expressの場合はアドレスとデータ、さらにさまざまな制御信号も全部同じ2対の信号線を時間多重で送る形になるので、これによるオーバーヘッドを差し引いてやる必要がある。
その一方で、PCIでは送受信が同一バスを共有していたから、この分のオーバーヘッドを考えると、PCI Expressでは倍以上の帯域が利用できるようになる。もっとも、グラフィックスカードの用途では「250MB/秒の帯域でもまだ足りない」ということで、同時に4/8/16/32本の信号線を束ねた形の接続も同時に定義された。一般にこれをx4/x8/x16/x32と表記している。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























