



AI活用成功にはデータ基盤整備が不可欠。新たなコンセプトを掲げ、その浸透を図る
“鶏が先か、卵が先か”の議論をやめ、AIを事業成果につなげる年へ ―ネットアップ・斉藤社長
2026年01月09日 08時00分更新

AI向けデータ処理もストレージ内で、「AI Data Engine+AFX」をリリース
――ネットアップでは「インテリジェント・データ・インフラストラクチャー(以下、IDI)」というコンセプトを掲げており、今年度はその現場導入を進める「展開の年」にしたいと方針を述べられていました。このIDIというのは、ネットアップが従来アピールしていた「データファブリック」が進化したものと考えてよいですか。
斉藤氏:「進化」というよりは、IDIの中にデータファブリックも包含されていると考えてください。IDIの根本的な考え方は、「お客さまが持つあらゆるデータを“AI Ready”なものにする」というものです。そのベースとなるレイヤーに、データファブリックが組み込まれている。そんなイメージです。
AIの価値を最大化するデータ基盤を構築するためには、オンプレミスからクラウドまでシームレスなデータアクセス、データ管理を実現することが必要です。ここで、ネットアップのデータファブリックの優位性が生きてきます。
――それでは、IDIで新たに加わった部分、つまりデータファブリックとの“差分”は、技術的にはどんなものでしょうか。
チーフ テクノロジー エバンジェリスト 神原豊彦氏:お客さまのデータをAI Readyなものにするために、新たに「NetApp AI Data Engine」が組み込まれています。AIモデルが読み込めるデータにするためにはさまざまな事前処理が必要ですから、それをわれわれのデータ基盤側でやってしまおうと。たとえばデータのベクトル化や、メタデータの管理といったものですね。

インテリジェント・データ・インフラストラクチャー(IDI)の全体像。AIワークロード向けのデータ処理を行う「AI Data Engine」も組み込まれている
――今回、ネットアップが単なるデータストレージにとどまらず、そうしたデータ処理まで踏み込んだのが興味深いところです。それはなぜですか。
神原氏:従来のAIモデルのトレーニングでは、この図(図A)のようなプロセスが必要でした。左にある各種ストレージからデータをデータレイクに集め直し、ラベリングやベクトル化をしてGPUクラスタにつないで……と、準備作業の間に何度もデータのコピーや移動が発生し、多数のツールを使うことになります。この中間処理の部分をAI Data Engineが引き受けることで、ネットアップのデータ基盤内で一括管理することができます(図B)。
もちろん、すでにAIモデル開発を手がけられているお客さまは、こうした(図Aのような)システムを構築されているケースもあるので、それを丸ごとAI Data Engineに変えていただく必要はありません。ただし、こうしたデータ処理にまつわる部分は「NVIDIA NeMo」フレームワークなどで徐々に標準化が進んでいますから、部分的にご採用いただいたり、必要なタイミングで丸ごと入れ替えたりということも考えられるでしょう。
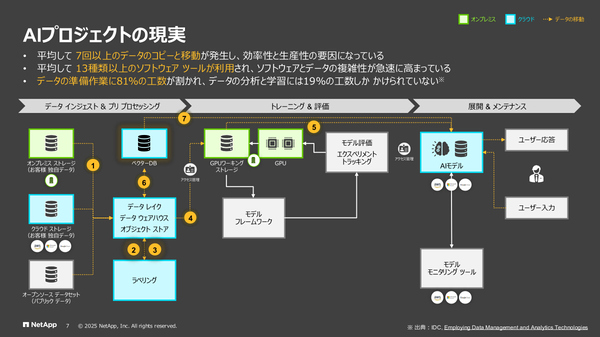
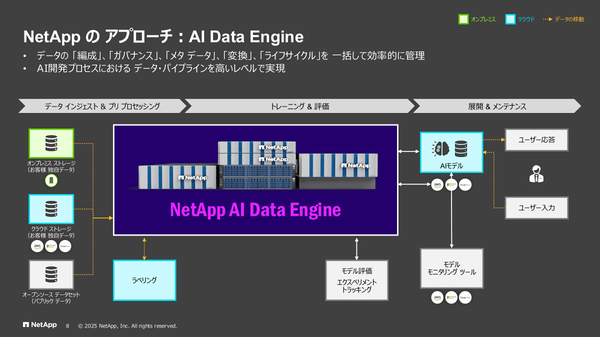
(図A)現在のAIプロジェクトにおけるデータの流れ (図B)データ基盤にAI Data Engineを組み込みデータパイプラインの効率化を図る
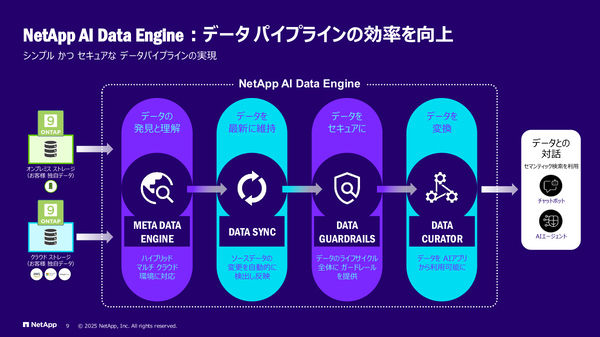
「NetApp AI Data Engine」が提供する機能の概要
――話は戻りますが、IDIのベースとなるストレージ部分の要件は、従来のエンタープライズストレージと変わらないのでしょうか。何か特別な要件はありますか。
神原氏:ストレージアクセスのプロトコルを含め、基本的には変わりません。ただし、これまでせいぜい数百台規模だったサーバークラスタが、数千台、数万台というオーダーになってくるので、われわれもスケールアップさせる必要がありました。
そこで今回リリースしたのが「NetApp AFX」という新しいモデルのストレージです。エンタープライズAIワークロード向けストレージとして、たとえばI/Oスループットは4TB/秒、扱えるデータセットの容量は1EB(エクサバイト)以上と、徹底的にAI向けのチューニングが施されています。分散アーキテクチャを採用しており、構成可能なノード数も最大128ノードまで拡大しています。

AIワークロード向けに設計されたハードウェア「NetApp AFX」も追加された
加えて、本格的にAIモデル開発に取り組んでいるお客さまからの要望が強かったのが「データセキュリティの強化策」です。
AIに対する攻撃手法のひとつとして、トレーニング用データに不正なデータをまぎれ込ませて、誤った判断や回答をするAIモデルを開発させる「データポイズニング」というものがあります。トレーニングデータが10万個あるうち、わずか2個を改竄するだけで実行できるという調査結果もあり、人間がそれを監視し検出するのは困難です。ネットアップでは、以前からランサムウェアの自動検出に取り組んできましたから、その技術を適用して攻撃を検出できるようにしています。
――先ほどのAI Data Engineは、このAFX上で動作するのですか。
神原氏:そうですね。細かく言えば、AFXのストレージ部分はコントローラーノードとSSDディスクシェルフで構成されますが、そこにAI Data Engine用の「データコンピュートノード」が新たに追加され、この全体がAFXとして機能する仕組みです。
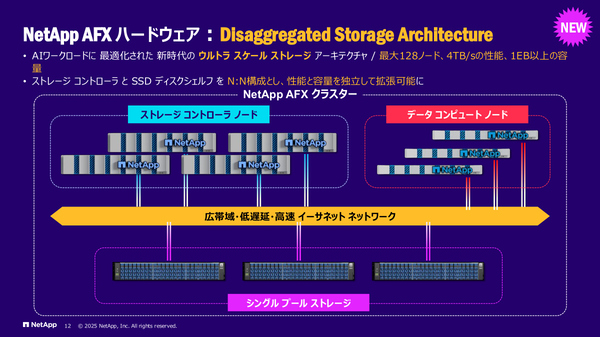
AFXにはAI Data Engine向けのコンピュートノードも統合されている
本記事はアフィリエイトプログラムによる収益を得ている場合があります



