



ロードマップでわかる!当世プロセッサー事情 第831回
Intel 18AはTSMCに対抗できるか? RibbonFET/PowerVIAの可能性と限界 インテル CPUロードマップ
2025年07月07日 12時00分更新

今回から数回に分けて、6月8日から6月12日まで京都で開催されたVLSIシンポジウム(Symposium on VLSI Technology and Circuits)における発表を説明していく。もっとも5日間といっても初日はワークショップ、2日目は短期講習に費やされており、実質3日間となる。
まず初回はTechnical Session T1-1として真っ先に開催された、Intel 18Aに関する発表(Intel 18A Platform Technology Featuring RibbonFET (GAA) and PowerVia for Advanced High-Performance Computing)について解説したい。
Intel 18AはRibbonを積み重ねてCell Libraryを小型化
配線密度はIntel 4/3世代と大きく変わらない
Intel 3に関してはその内部構造を含めて連載784回で説明した。一方Intel 18Aに関しては今年4月のIntel Foundry Direct Connect 2025で若干の性能プレビューが示された程度でしかなかったのだが、今回わりと細かく詳細が公開された。
まずIntel 18Aには複数の派生型があるという話は以前のロードマップでも出ていたが、基本となるのがIntel 18Aで、Intel 18A-Pはその性能改良型、そこにFoveros Direct 3D対応を追加したのがIntel 18A-PTという形になる。ちなみにRibbonFETとPowerVIAことBSPDNはIntel 18Aで標準搭載される技術となる。
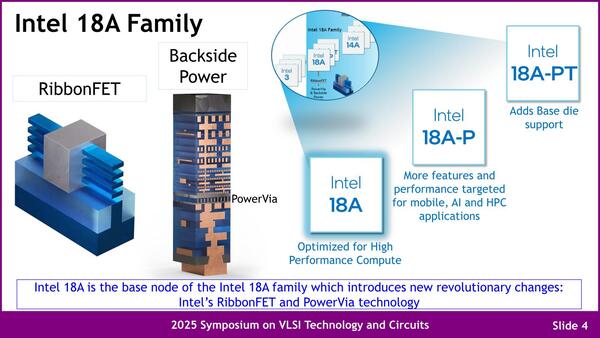
Intel 18A-Pが"mobileとAI、HPCをターゲット"と書いてある時点で、性能を優先して駆動電圧と動作周波数を引き上げたものではない(AI/HPCはともかくモバイル向けにこの方法は適さない)ことはわかる
そのIntel 18AをIntel 3と比較した動作周波数/消費電力の比較が下の画像である。
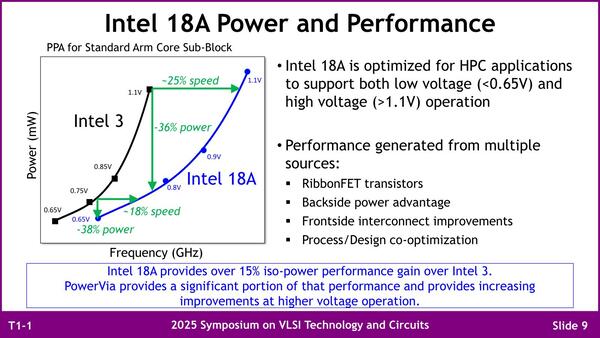
Intel 18AをIntel 3と比較した動作周波数/消費電力の比較。もっともこれはArmのCore(おそらくCortex-A715だろう)を使っての比較なので、x86で同じだけの効果が得られるかはまた別だ
4月における説明では、Perf/WがIntel 3と比較して15%以上向上するという話であったが、0.65V付近でも18%、1.1Vでは25%の動作周波数向上が期待でき、逆に動作周波数一定なら36~38%の消費電力削減が期待できるというなかなかの優れものであるとされる。
もう1つ、Chip Densityが1.3倍という数字も示されていたが、その根拠が下の画像だ。
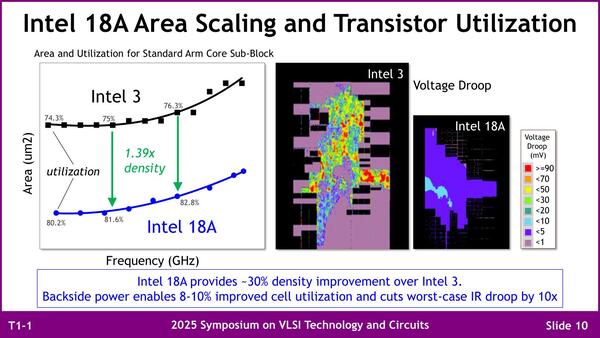
左側のグラフ、よく見るとIntel 3のArea Sizeは5つ、Intel 18Aの方は7つになっているのがわかる。つまり、PPA Optimizationといっても速度が低い時にはそこまで最適化された構造に違いが出ない。ただIntel 18Aの方はかなり細かくArea Sizeが変わるあたり、けっこうPPA Optimizationの影響がありそうだ
複数のターゲット周波数に向けて最適化した結果を比較すると、平均して39%ほどエリア面積が小さく、また利用効率も向上しているとする。加えて電圧降下(Voltage Droop)もずっと少なくなっていることが右側に示されているが、これはRibbonFETや微細化された配線よりもPowerVIAが効果的に作用しているとしている。利用効率も、PowerVIAを使うことで配線層にゆとりが生まれ、結果として8~10%の効率向上につながったそうだ。

Cell Libraryの比較。ちなみに左上のIntel 3の"240CH HD Library"は"240 HP Library"の間違いである
上の画像はCell Libraryの比較である。Intel 7→Intel 4の時がこれ、Intel 4→Intel 3の時がこれである。この中でCPP(Contacted Poly Pitch)は実はIntel 4/3/18Aが50nmと共通のままである。
一方のFin Pitchに関しては、Intel 7が34nm、Intel 4/3が30nmとなっているのだが、Intel 18AではそもそもFin Pitchがない(Finがないのだから数字を示しようがない)。ただM0 Pitchで比較するとIntel 7が40nm、Intel 4/3が30nm、Intel 18Aが32nmであることから考えて、おおむね同等と考えていい。
要するに1 FinのIntel 4/3とIntel 18Aはほぼ同等の実装密度を実現できていることになる。Cell Library全体で言えばIntel 7が408nm、Intel 4/3が240/210nmなので、180/160nmでけっこう大きな密度上昇となる。
なぜこれが可能かと言えば、Intel 4/3ではFinの数を増やして特性を変えている(上の画像でHPはFinが3つ、HCはFinが2つ)のに対し、Intel 18AではRibbonをZ軸方向に積み重ねて特性を変えている(ついでにRibbonの幅も変えている)から、結果としてFinFET世代よりCell Libraryを小型化できることに起因する。逆に言えば、配線密度そのものはIntel 4/3世代と大きく変わらないこともここから明らかになった格好だ。
この性能調整に関するスライドが下の画像だ。Ribbonの枚数、それとRibbonの幅を160Hと180H、両方のライブラリー向けに複数用意しており、必要とする特性によって選べる仕組みになっている。

左はRibbonの部分、右はそのRibbonの上に構築される接続部を示した図である。ちなみにRibbonの奥行きは一定と思われる
Ribbonの幅についてはそこまで自由に変えられるわけでもないだろうが、160Hなり180Hの中に収められる形で複数(おそらく2~3種類)用意されているものと思われる。あまり種類が多すぎても最適化に時間が掛かるだけだからだ。
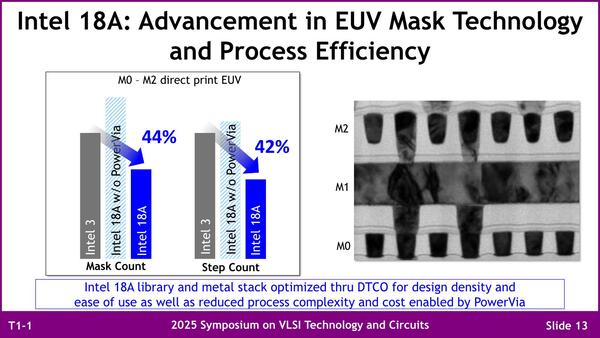
ちなみにdirect print EUVはM0~M4だが、ここまで減るのはM0~M2だけ……という意味に読めるのだが、次のスライドを見るとM3~M4も同程度に減りそうな気がする
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ














で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")










































