
3次キャッシュの形を変更
SRAMの実装密度を引き上げ、回路設計を工夫することで性能を向上
次に物理実装の話だ。プロセスノードを進めても、必ずしもすべてのものが連動して密度が向上するわけではない。ロジック、つまりトランジスタ1個の面積が一番アグレッシブに微細化が進むが、配線の微細化はもっとゆっくり進む。理由は連載809回のインテルのIEDMの発表のところでも述べたが、もう銅配線はこれ以上微細化を進めると配線抵抗が大きくなり、かつエレクトロマイグレーションの影響がシャレにならないほど大きくなるためである。
Intel 4ではエレクトロマイグレーション対策として、銅配線をコバルトのライナーで囲み、その外側を窒化タンタルで覆ったeCU(Enhanced Cu)という技術を採用したという説明を連載675回でしたが、ならばeCuを使えば配線の幅を半分に減らせるかといえばそんなわけもなく、Ru(ルテニウム)を使った配線を利用することを模索しているが、実現するのは早くて2030年代である。
その先として有望なのはカーボンナノチューブであるが、こちらはもっと実現までに時間がかかる。結果、当面はコバルトや窒化タンタルを組み合わせながら、少しずつ配線の微細化を進めるしかない。SRAMはフリップフロップ回路を利用して構成され、一番簡単なRSフリップフロップ回路なら4つのトランジスタで構築できるが、普通は6つないし8つのトランジスタを組み合わせて1bit分のSRAMを構築する。
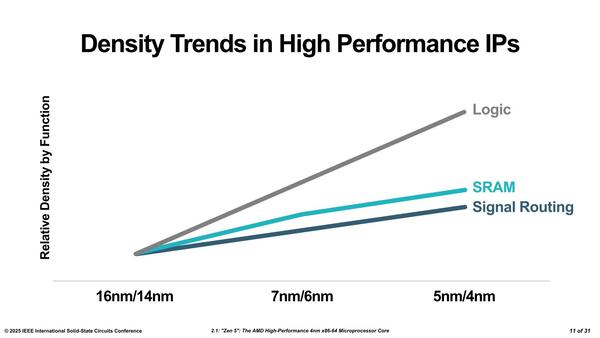
TSMCは自社のHD SRAMは結構微細化ができるなどと発表しているが、AMDはそもそも自社でSRAM回路を作って実装しており、TSMCの数字がそのまま使えるわけではないことに注意
ということはこの6つなり8つのトランジスタをつなぐ配線が必要であり、この配線を微細化しにくいためにSRAMの微細化が進まない、という問題がある。そこでZen 4→Zen 5では以下の工夫を凝らしたとしている。
- 8トランジスタ構成のSRAMを6トランジスタ構成に変更するなど、実装密度を引き上げることで回路規模拡大に伴う利用するトランジスタ増の影響を最小限にする
- 内部バスの拡大と効率改善の両立
- より効率的な回路設計を実施
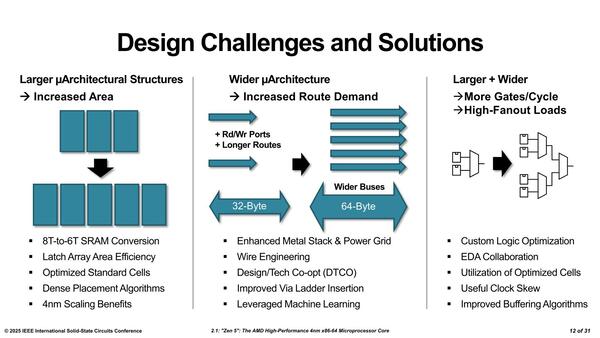
より高密度実装のための(CADの)アルゴリズム考案とか、配線の最適化にMLを利用する、など開発ツールのレベルでの改良もけっこうあったとする
結果として、Zen 4とZen 5を比較した場合、トランジスタの数はCCXあたり65億個から79億個まで増えたのに同じ面積に抑え込めた、としている。ただ配線層が17層に増えているあたりは、配線密度が上げられないので層数を増やしてなんとか対応できた、ということが見て取れる。
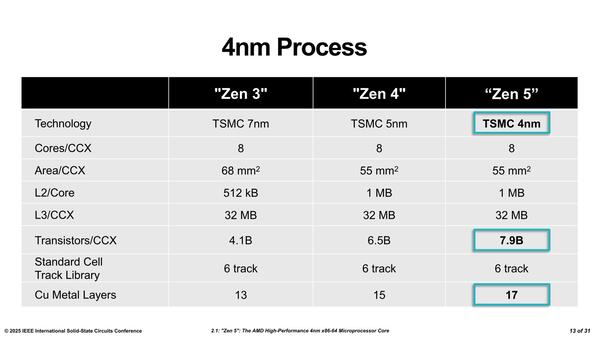
TSMCのN5とN4は基本的なパラメーターはほぼ同じであり、ここでのトランジスタ密度増加や配線密度増加の効果はほとんど期待できない。65億個→79億個では21.5%ものトランジスタ増加であり、これはN5→N3なら容易だが、N5→N4では普通無理である
この最適化の結果、Zen 4とZen 5ではずいぶん3次キャッシュの形が変わった。Zen 4ではCCDの面積の35%を占めていたのが、大幅に改善した模様だ。ラフに言えばZen 4時代の3次キャッシュは36mm2ほどの面積だったが、これが28mm2ほどに縮小されたようだ。

Zen 3/4世代では3D V-Cache用に結構な量のTSVのエリアが用意されていたが、これをだいぶ縮小できたらしい
Core Aspect Ratioは、CCD全体がZen 4までの横長からやや正方形に近い形になっている。その方が1枚のウェハーからとれるチップの数を増やせるわけで、歩留まり向上につながるわけだ。
ところでZen 5世代では3D V-Cacheの位置がZen 4世代までと逆になる、という話があったが、その模式図が下の画像だ。Zen 4世代は以下の形に改まった。

これはあくまでも模式図であって実際の断面写真ではない(なにしろ左右の写真が完全に同一である)
(1) CCDの裏面にTSVを構築する
(2) そこに3D V-Cacheの表面をSoICで積層する
という形になっていたが、Zen 5世代では
(1) 3D V-Cacheの裏面にTSVを構築する
(2) そこにCCDの表面をSoICで積層する
このメリットとしてAMDから挙げられたのは、「結果的にヒートスプレッダがCCDの真裏に位置することになるので、放熱効率が上がる」ということだった。Zen 4までの方式では、CCDとヒートスプレッダの間に3D V-Cache(とダミーのシリコンダイ)が挟まるので、そこで放熱効率が落ち、結果的に温度上昇に弱くなるためあまり動作周波数を上げられなかったが、Zen 5ではこうした問題が解決したとしている。
これは確かにメリットなのだがもう1つ大きなポイントとして、「CCDに3D V-Cache接続用のTSVを、ベースシリコンを貫通させる形で構築する必要がない」ことが挙げられる。ベースシリコンを貫通させるTSVを構築するのには相応のコストがかかる。ところがZen 4まででは、仮に3D V-Cacheが必要ない場合でもTSVを構築しておく必要があり、これがコスト増になった。
ところがZen 5ではTSVの構築は3D V-Cache側になるので、TSV構築のコストは3D V-Cache搭載による価格のプレミア分で吸収できる。3D V-Cacheを搭載しない場合には、そもそもTSVの構築が行なわれないから、原価が下がるわけだ。
メリットだけでなくデメリットもある。Zen 5世代の場合、TSVは配線側に構築されることになる。したがって構築そのもののコストは安いが、配線がTSVを避けるようにしなければならないので、若干窮屈になる。Zen 5で配線層が2層増えた理由の1つはこのあたりにあるかもしれない。それでも裏面にTSVを構築するよりは安価だと思うが。
そのZen 5のCCDのBreakdownが下の画像である。L3がスリムになった分、全体の横幅がやや小さくなった。おそらくこれは、Turinの16 CCD構成を取る際に、パッケージに乗りきらないという事態を起こさないためにどうしても必要だったのだろう。

全体で66mm2という数字も初出だったように思う。あとGMI3がTX(送信)×16、RX(受信)×20という非対称構成なのも初出だった。速度が36Gbpsなのは、Ryzenの方がZen 4と同じIoDを利用していることに関係しているのだろう
わりと細かい話ではあるが、Zen 4→Zen 5ではいろいろな隠れた工夫が凝らされていることがわかった発表であった。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ













