




フィンの数ではなくナノシートの数を増減させる技術
NanoFlex
最適化の一助となるのが、NanoFlexと呼ばれる技術である。もともとTSMCはN3の時点でFinFlexと呼ばれる、特性を変えた3種類のトランジスタを用意、これを組み合わせることで望む特性を簡単に得やすくする技術を提供していた。
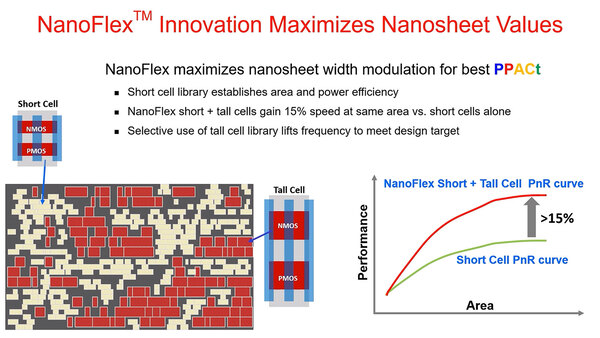
NanoFlexの概要。Short Cellはシートの数が少なく、高密度/省電力型、一方Tall Cellはシートの数が大きく、高速型となる。実際にはShortとTallだけでなく、複数の選択肢があると思われる
実際には複数のフィン数の組み合わせ(NMOS/PMOSでそれぞれ3/2枚、2/2枚、2/1枚となる構成)をあらかじめ用意し、これを利用して簡単に回路を構築できるようにするというものだが、NanoFlexはフィンの数ではなくナノシートの数を増減させて同じことが可能になるようにしている。
実際にN3EおよびN2プロセスを利用し、Cortex-A715コアを稼働させたときの性能/消費電力の比較も示された。下の画像は省電力同士、つまりN3Eなら2-1構成のもので、一方N2はShort Cellを利用したNanoFlex HDを利用したもので、ピークでは14%高速ないし35%の省電力、0.6V付近では15%高速ないし24%の省電力化が実現できたとする。
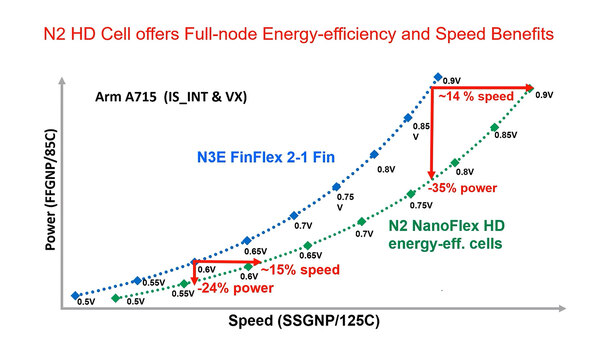
省電力ということもあり、電圧の範囲は0.5V~0.9Vまでとなっている
一方高速同士、つまりN3EがFinFlex 3-2、N2がTall Cellを使ったNanoFlex HPの場合の比較が下の画像だ。動作周波数の向上は12%ないし12.5%とやや小さめだが、その代わり38%ないし30%と省電力同士の場合よりも電力削減効果が大きいものとなっているとする。
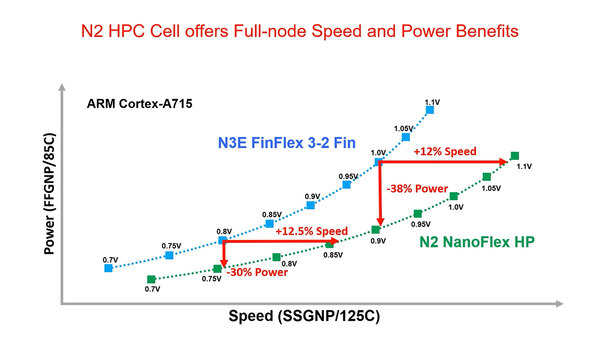
こちらは高速型なので0.7V~1.1Vとやや電圧が高めになっている。省電力効果が大きいのは、この電圧が高めな部分も関係しているのだろう
ちなみにNanoFlexはHD Short Cell/HD cell/HPC cellの大きく3種類に向けたソリューションとなっている。
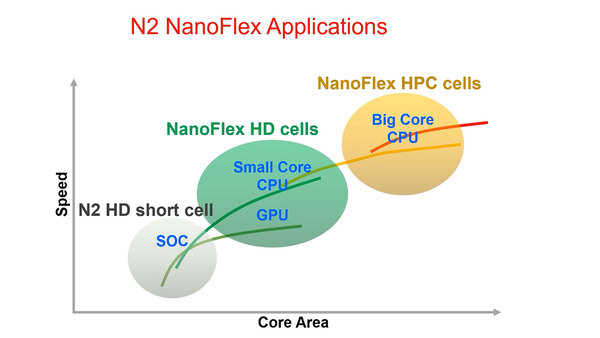
NanoFlex HDの中には、実際には2~3種類のシート構成が用意され、これを使い分けるかたちになっているものと思われる。これはHD short cell/HPC cellでも同じことだ
そのN2世代のトランジスタの基本的な特性が下にある4つの画像となる。細かくは説明しないが、既存のN3Eと比較しても十分性能改善がなされていることが、実際のシリコンでのデータを元に示されたことは大きい。

DIBLはPMOSで30mV/V、NMOSで24mV/Vとかなり低めなのだが、ゲート長で正規化しての結果となっている。ゲート長そのものは公開されていない
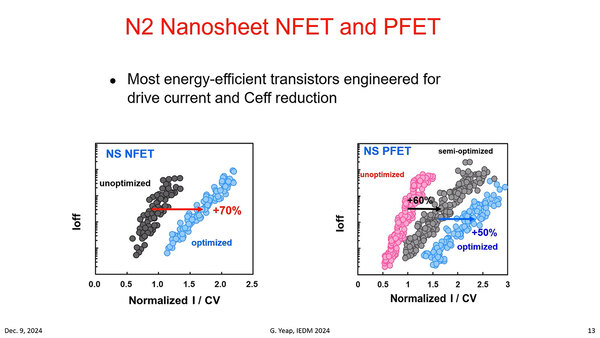
Ioff(トランジスタオフ時のリーク電流)の比較。縦軸がリーク電流、横軸がレイテンシーの逆数である。傾向としてはグラフが右にずれればずれるほど、リークが少ないことになる。PMOSのSemi-optimizedというのがどういう状況なのが気になるところ
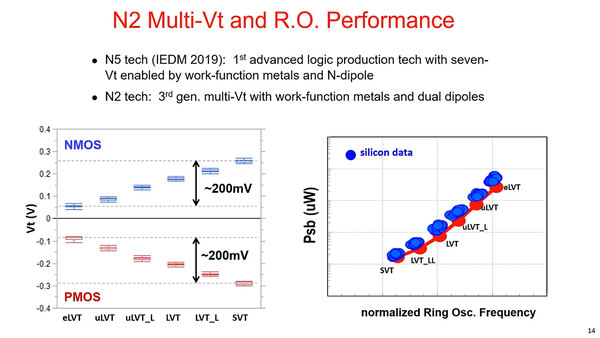
複数電圧での動作。右グラフはRing Oscillatorを構成して、動作周波数(横軸)と消費電力(縦軸)をプロットしたもの。赤がシミュレーション、青が実際のデータとのこと
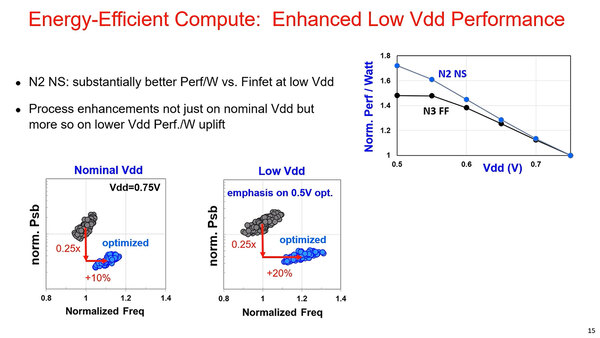
低電圧時の振る舞い。N3と比較して、0.5V付近ではさらに効率が改善するとしている
興味深いのSRAMである。何度か書いたが、トランジスタの微細化が進んでもSRAMの密度が上がらない、というのが目下の問題である。これはトランジスタそのものの大きさより配線の方がむしろ阻害要因になっているからだが、それでも2nmでは38.1Mbit/mm2まで密度を上げられたとしている。
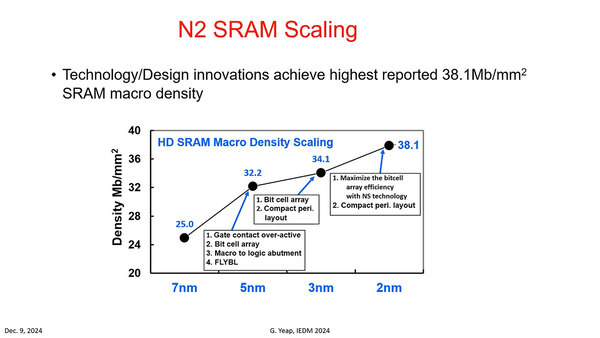
とはいえN3からでは34.1Mb→38.1Mbで11%程の増加でしかないのだが。トランジスタ数そのものは15%増なので、やはり配線がネックではある
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ














&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")

















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












