




FLUX.1の再現性が高いのは”潜在空間”が広いから
なぜFLUX.1でLoRAを使うと、少ない学習データ、短い学習時間でもかなり高い再現性が実現できるのか。その一因はFLUX.1のパラメーター数が多いためです。
FLUX.1のパラメーター数は120億とアナウンスされています。1年前の「Stable Diffusion XL」のパラメーターは35億。2年前の「Stable Diffusion v1.4」は、公開されていませんが数億程度だと推測されています。
一般的に、パラメーター数が多いほど、ウェイトモデルが持つ潜在空間(Latent space)の幅が広いことになります。FLUX.1は現状公開されているオープンモデルのなかでは段違いに広く、深いことがわかります。
この潜在空間が広ければ広いほど、出力できる画像の幅も広いと言えるのです。
月須和・那々さんが開発した「コピー機LoRA」という手法があります。20枚の画像からもっと多くの画像を学習させてLoRAを作るのではなく、雰囲気の異なる、たった2枚の画像を1000回にわたって過剰に学習させ(過学習)、そのLoRAを結合(マージ)させることで、特定の画風の出力を可能にするという手法です。
公開されている「とりにく絵LoRAの作り方」という手法によると、まずコピー機LoRAを使い、安定的に決まった画風を出せるLoRAを作り、それを使って他の表情やポーズのバリエーションを作り、素材となるデータを100枚以上作ります。そしてそれらを学習させることで、自分の画風LoRAを作っていくというものです。
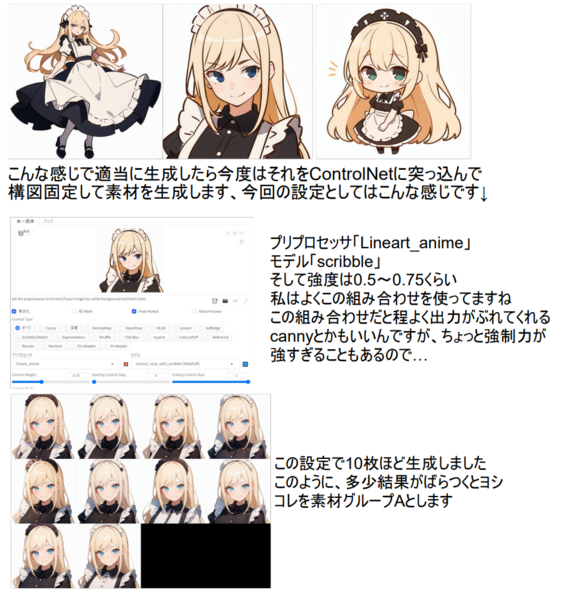
「とりにく絵LoRAの作り方」の解説より。1枚の元画像からLoRA学習をするためのバリエーション素材の作り方を紹介しているページから
この方法論はかなり有効で、筆者の経験でも、一定の画風LoRAを構築するのは、数回かつ数時間にわたるLoRA学習を繰り返すことで実現できました。この手法によって、それなりに特定の画風を作れてしまうのは、Stable Diffusion XLの潜在空間にそれだけの広さがあるからこそのものでした。
そのとき、Stable Diffusion XLよりさらに潜在空間が広いFLUX.1 devであれば、より少ない学習であっても、こうした画風などの生成結果を確立できるLoRAを短時間できる可能性が垣間見えているというわけです。
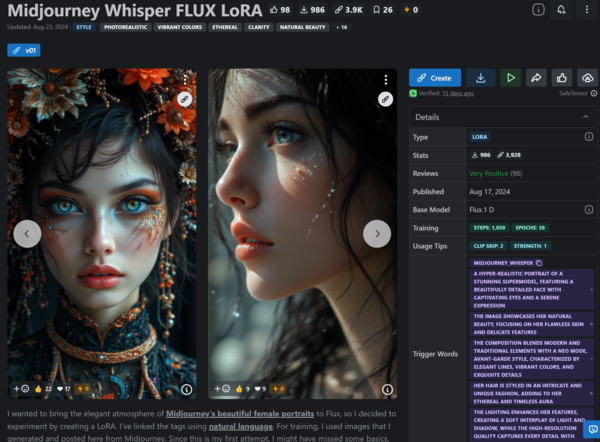
たとえば、8月に登場したFLUX.1 Dev用の画風LoRAに、aihonobono2023さんが公開した「Midjourney Whisper FLUX LoRA」というものがあります。これはMidjouneyで生成した画像を使ってトレーニングしたFLUX.1 Dev LoRAのようなのですが、このLoRAを適応すると、画像の雰囲気がハイパーリアルな写真風に雰囲気が変わり、同じプロンプトでも劇的に情報量が増えるという効果があります。
このLoRAを使うと、同じ「ラーメンを食べる」という画像でも、劇的に変化します。

FLUX.1 Devでラーメンチャレンジをしたときの画像(右)。「日本」という条件を入れるとアニメ風で出たりする傾向がある。同じプロンプトの同じシード値(ランダム値)に、Midjourney Whisper FLUX LoRAを適応したもの(左)。写実的な画像に変わっている
LoRAが何をしているかと言えば、結局は、学習データを通じて獲得された、特徴点の情報を利用することで、画像全体をその方向に引きずっているだけなんですよね。なので、潜在空間が広いほど絵柄を引きずりやすい。
FLUX LoRAを作っていて感じるのは、まだまだ発見されていない潜在的な表現能力は相当潜んでいるということです。今後、その幅の広さは、様々な方法で発見されてくると考えられます。FLUX.1でも「コピー機LoRA」手法から、画風を確立する方法が有効かどうかは今後検証されていくことでしょう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第163回
AI
無料の画像生成AI「Krea 2」が話題 実写もアニメもこなす新勢力 -
第162回
AI
ローカルAIで“しゃべる推理ゲーム”を作ったら、思ったよりちゃんとゲームになってきた -
第161回
AI
わずか3日で停止された新AI「Claude Fable 5」は何がすごかったのか -
第160回
AI
寝不足になるほど面白い ローカルAIと音声合成をつないだら、キャラが普通にしゃべり始めた -
第159回
AI
AIを使える人と使えない人で、とんでもない差が出ると実感した理由 -
第158回
AI
SDXLの次はこれ? アニメ特化のローカル画像生成AI、驚きの実力 -
第157回
AI
AIだけでゲームは作れるのか? Codexに7本作らせて見えた実力と限界 -
第156回
AI
ChatGPTの画像生成AIは本当に最強か Nano Bananaと比べて見えた“弱点” -
第155回
AI
非エンジニアが数百万円級のツールを開発 画像&動画生成AIツールがゼロから作れた話 -
第154回
AI
ChatGPTの画像生成AIが強すぎる AI画像が世界中に氾濫する時代へ -
第153回
AI
ChatGPTの画像生成AIが「Nano Banana」超え? 漫画や動画風カットが実用レベルに - この連載の一覧へ









































ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")
