





東大発ベンチャーのNABLASは8月13日、グーグルが開発した音声生成モデル「SoundStorm」の構造をベースに、数秒のデータを用いて瞬時に日本語の音声生成が可能な「日本語対応音声生成モデル」を開発したことを発表した。
グーグルの音声合成AI「SoundStorm」

グーグルが開発した最先端の音声生成モデルSoundStormは、わずか3秒程度のオリジナル音声データを元に、テキストプロンプトやサンプル音声データを渡すことで本物のような音声を短時間で生成できるモデルだが、日本語には対応していなかった。
SoundStormをベースに日本語データセットで学習
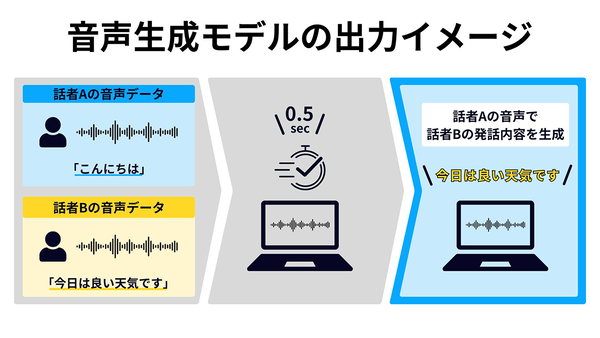
上記のSondStormをベースにNABLASが今回開発した日本語対応音声生成モデルは、サンプルとなる数秒の話者Aの日本語音声データと、発話させたい内容を含む話者Bの日本語音声データを基に、話者Aの声質で話者Bの発話内容をわずか0.5秒で生成する「Speech to Speech」型の音声生成が可能となっている。
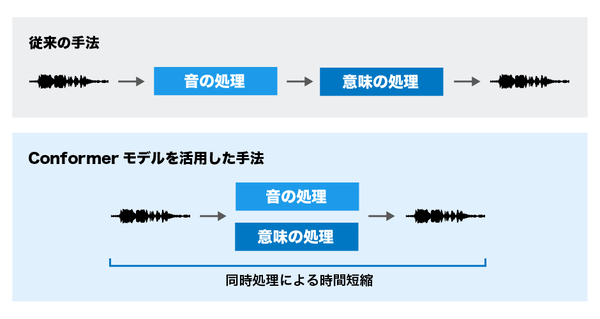
同モデルの特徴としては、日本語の音韻体系や韻律パターンを正確に再現し、自然な日本語音声を生成できる点にある。開発にあたっては、SoundStorm内部に構築されているConformerモデルの構造をベースとしつつ、日本語特有の言語構造や音韻規則に対応するよう調整した。
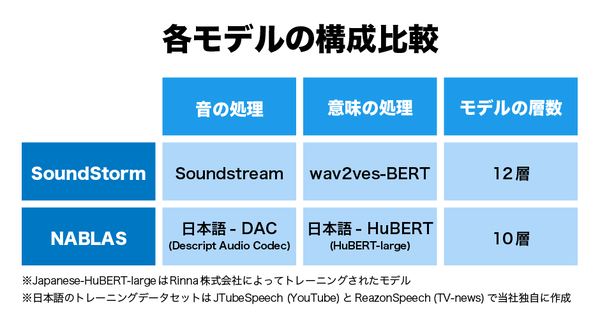
技術的には、日本語での音声生成に適したオーディオコーデックを用いてモデル開発をしている。その結果、日本語の音声品質や生成音声の類似度スコアにおいて、英語版SoundStormを上回る結果を得たという。
日本語に特化した音声生成モデルを作るため、学習には独自で処理を行った日本語音声データセットだけを使用されている。このデータセットには、背景の騒音や音を除去する処理を施し、よりクオリティの高い日本語音声の生成を実現しているという。
将来的にはアニメの自動吹き替えも
現時点での応用範囲としては、医療分野での発話困難者への支援、カスタマーサポートでの感情的な音声の変換、エンターテインメント分野での声質変換などが挙げられる。
将来的には、アニメやゲームの吹き替え音声などでも、多様な声質や感情表現を持つ日本語音声をリアルタイムに生成できる可能性がある。
NABLASは今後、SoundStormの他の機能も含め、日本語に特化した音声変換やテキストの読み上げ、リアルタイムでの対話翻訳など、さらなる技術開発を進め、同時に、これらの生成技術の悪用を防ぐための検出技術の開発にも取り組むとしている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")















