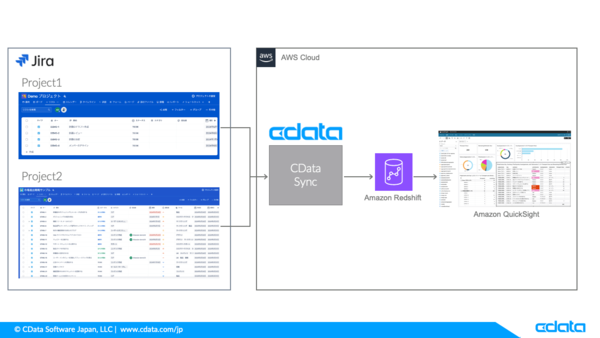
JiraのデータをRedshiftにレプリケーションしてプロジェクト横断のパフォーマンス分析を実施

本記事はCDataが提供する「CData Software Blog」に掲載された「Jira のデータをRedshift にレプリケーションしてプロジェクト横断のパフォーマンス分析を実施」を再編集したものです。
Jira はAtlassian が提供しているプロジェクト管理ツールで、数千のアプリと連携可能な拡張性と、規模を問わず様々なプロジェクトに対応可能な柔軟性で、2002 年に提供開始されて以来、世界中の 30 万社を超える企業に採用されています。
Jira のデータを有効活用
Jira に蓄積されたデータはプロジェクト状況の把握やデータ・ドリブンな意思決定の判断材料として活用可能です。
今回の例ではプロジェクトの状況把握やパフォーマンス分析ができるよう、CData が開発・提供しているデータパイプラインツール「CData Sync」を使ってJira のデータをAmazon Redshift にレプリケーションし、Amazon QuickSight で可視化してみたいと思います。
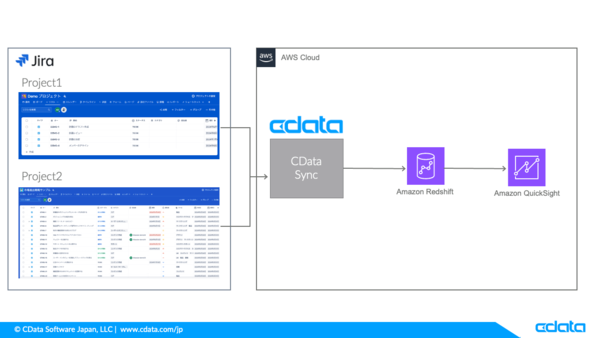
QuickSight で可視化するまでの流れ
Jira のデータをRedshift にレプリケーションし、QuickSight で可視化するまでの手順は以下です。
1.Jira とCData Sync の接続設定を行う
2.Redshift とCData Sync の接続設定を行う
3.CData Sync で JiraのデータをRedshift にレプリケーションする
4.Redshift に保存されたJira のデータを QuickSight で可視化
なお、プロジェクトのデータにはJira が提供しているサンプルプロジェクト「市場進出戦略サンプル」と新規に追加したシンプルなプロジェクトに稼働時間や完了までの予測時間を追加して使用しています。
1 Jira とCData Sync の接続設定を行う
1-1 CData Sync 環境の準備
CData Sync はフルマネージドなクラウド版では14日間、オンプレミスサーバーまたは自社のAWS インスタンスにホスティング可能な オンプレミス・セルフホスティング版では30日間の無料トライアルが可能です。
また、AWS Marketplace から入手可能なAmazon AMI 版についても14日間の無料トライアル (AWS利用料は別途必要) が可能ですので、まだCData Sync の環境をお持ちでない場合はお好みのエディションを入手しておきましょう。
なお今回はレプリケーション先のRedshift と同じネットワーク内にあるWindows Server に、セルフホスティング版のCData Sync をインストールして使用しています。
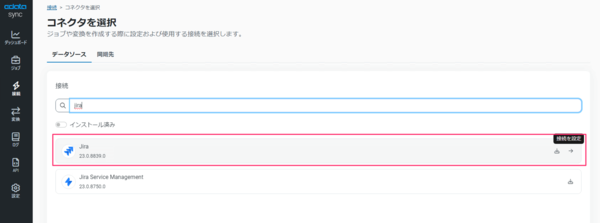
1-2 CData Sync にJira の接続設定を追加
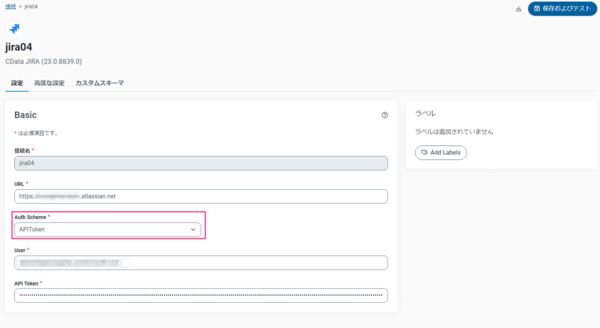
CData Sync の「接続」メニューにて「接続を追加」から「Jira」を選択します。
「Auth Scheme」の項目では「APIToken」を選択します。
Jira に接続するための「API Token」については公式ドキュメントにわかりやすい説明がありますのでぜひご参照ください。
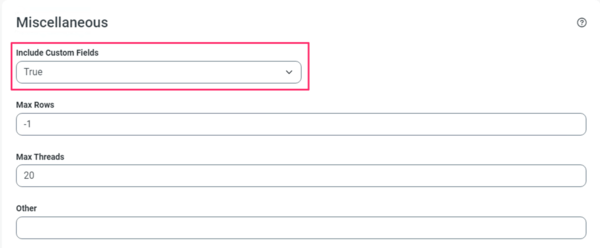
カスタムフィールドのデータも含めてレプリケーションする場合はCData Sync の接続設定画面の「高度な設定」タブ内、「Miscellaneous」セクションにある「Include Custom Fields」の項目を「True」に設定します。
2 Redshift とCData Sync の接続設定を行う
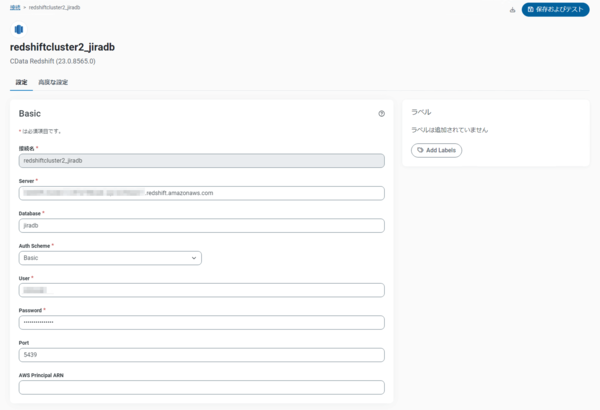
Jira の接続設定と同様にRedshift の接続設定を追加します。
こちらの「Auth Scheme」には「Basic」を選択しました。
3 CData Sync で JiraのデータをRedshift にレプリケーションする
CData Sync からJira とRedshift にアクセスが可能になりましたので、CData Sync 上でレプリケーションのタスクを追加していきます。
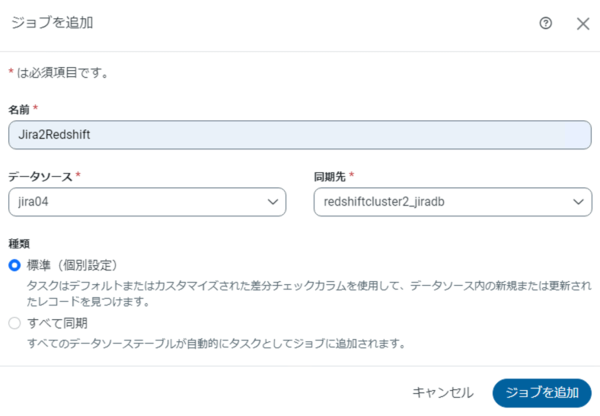
3-1 ジョブの追加
ジョブの設定では、データソース側にJira、連携先にRedshift を指定します。
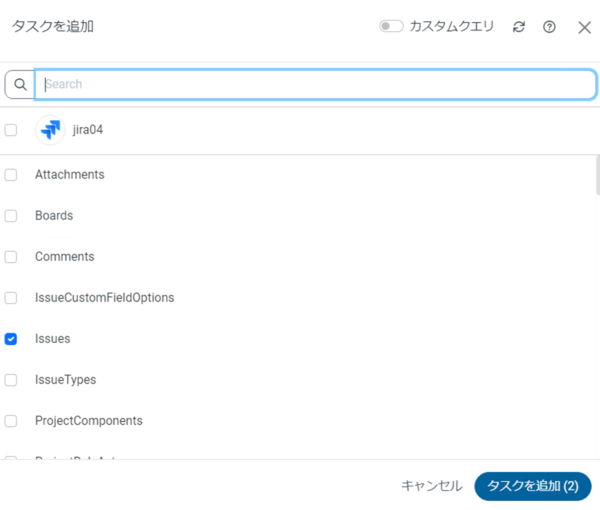
3-2 レプリケーションタスクの追加
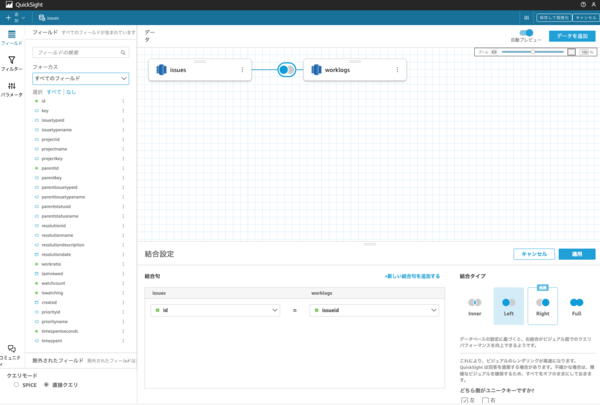
今回はタスク関連の基本的なデータを保持している「issues」と、タスクの対応時間や残りの予測時間などを保持している「worklogs」をレプリケーションしてみます。
3-3 レプリケーションタスクの実行
タスクを実行してみると、「SubtasksAggregate」と「IssueLinksAggregate」のカラムサイズが不足しているとのエラー「value too long for type character varying(2000)」が発生しましたので、「Redshift クエリエディタ v2」で以下のようにカラムサイズを変更しました。
ALTER TABLE public.issues ALTER COLUMN SubtasksAggregate TYPE VARCHAR(10000);
ALTER TABLE public.issues ALTER COLUMN IssueLinksAggregate TYPE VARCHAR(10000);
再度タスクを実行して、レプリケーションが正常に実行できることが確認できました。
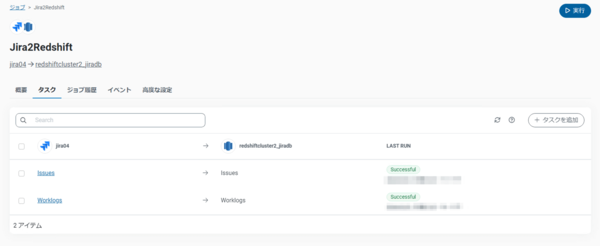
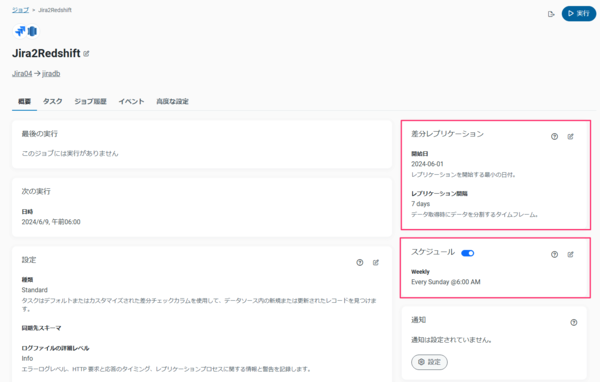
実際に本番環境で使用する場合は差分レプリケーションとスケジュール実行の設定をお勧めいたします。
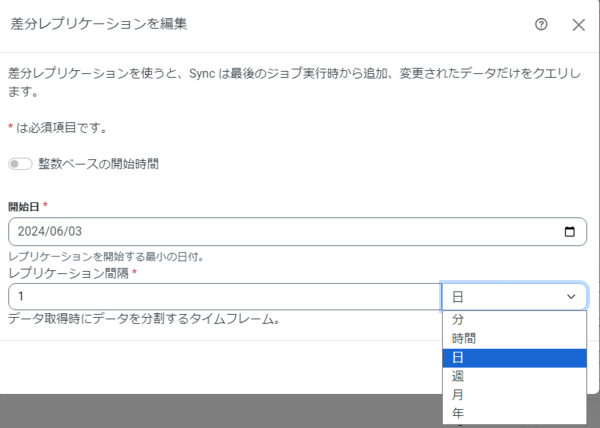
差分レプリケーションの設定例は以下です。
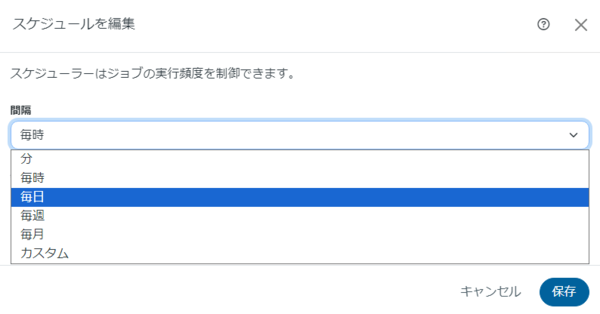
スケジュール実行の設定例は以下です。
差分レプリケーションとスケジュール実行の設定はジョブの「概要」タブで確認できます。
4 Redshift に保存されたJira のデータを QuickSight で可視化
最後にQuickSight でRedshift をデータソースとして追加し、ダッシュボードを作成していきます。
今回はタスクのカテゴリーや優先度、実施時間と残り時間のように、プロジェクトを横断したパフォーマンス分析が可能なダッシュボードを作成してみました。
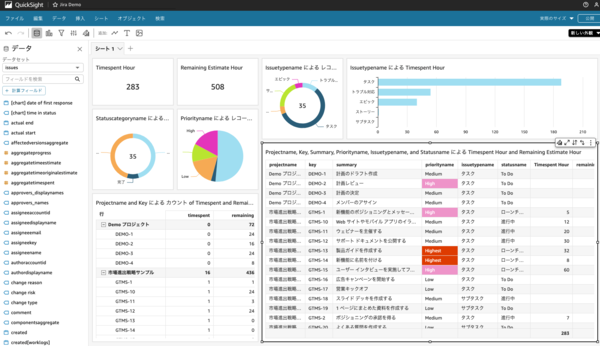
QuickSight は円グラフや表形式などのビジュアルを選択して計測対象のカラムを選ぶシンプルな操作でダッシュボードの作成ができます。
関連するテーブルの紐づけも可能ですので、Salesforce やSAP のデータと連携したコスト分析など、様々な観点での分析も可能です。
Jira に蓄積されたデータを活用すれば、社内のリアルな稼働状況や改善点の把握も容易にできそうです。
ぜひ皆さんのプロジェクトでもお試しください!