Ryzen AI 300に搭載された「RDNA 3.5」「XDNA 2」がAI処理を高速化 AIが常時動く未来はそう遠くない! AMD Tech Dayレポート
2024年07月18日 13時00分更新

AIが常時動く時代に向けたXDNA 2
最後にAI処理の要となるNPU、つまりXDNA 2に眼を向けよう。現時点でのAI処理はCPUではなくGPUでの処理が主流だが、Copilot+ PCではAI専用のNPUでの処理が重要になる。NPUはCPUやGPUほど複雑な処理はできないし、使えるリソース(学習モデル)も限られるので万能とは言えない。
だが、NPUに最適化した処理を振ればワットパフォーマンスでCPUやGPUを圧倒する。例えばビデオ会議の音声を同時通訳するAIアプリがあったとすると、ビデオ会議の間ずっと推論処理がバックグラウンドで続くことになるが、こういう用途にはワットパフォーマンスが有利なNPUが必要になる。
しかしその一方で画像生成は強力なGPUで一気に終わらせてしまった方がQOLが高くなるので、AIの推論デバイスは使い分けも重要になるのだ。
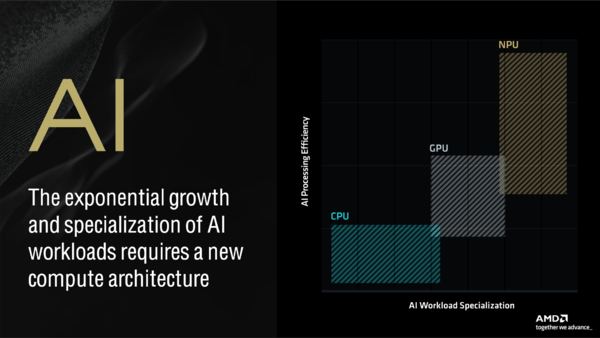
AIの処理が特化するほど、推論処理を行なうデバイスも新しいものが必要になる。横軸のSpecializationは特定用途への尖り方、縦軸はワットパフォーマンスと考えよう。NPUは特定用途に特化する(せざるを得ない)ぶん、ワットパフォーマンスが非常に高いのが特徴だ

LLMや画像生成(Stable Diffusion)では学習モデルが大きいが推論の頻度はそう多くない。一方でリアルタイムの音声や画像処理ではモデルは小さくとも延々と推論を繰り返す。常時AIを裏で動かすためにはNPUは必要だ、という主張
前置きはこのくらいにして、XDNA 2のアーキテクチャーを見てみよう。Ryzen 7040や8040(そしてRyzen 8000Gシリーズ)に搭載されているNPU(XDNA)の後継である。内部構造は主にAI Engine(AIE)タイルとメモリータイル(オンチップのメモリー)などで構成されているが、タイル同士の接続をプログラムで変更できる。つながれたタイルならデータは自由に流せるため、AIE間でデータのやりとりが効率良く行なえる。
また、プログラマブルなタイル構造をとることで複数のAI推論処理を1基のNPUで同時に実行できるのもXDNA 2の大きな特徴だ。軽い処理なら縦2列のAIE&メモリータイルだけを使うこともできるし、空いたタイルに別の処理を2列単位で割り当てることもできる。無論1つの処理ですべてのタイルを占有することも可能だ。使われてないタイルは電源を切ることもできる。
またXDNA 2ではXDNAよりもAIEタイルの数やオンチップのメモリーを1.6倍に増やしただけでなく、AIEタイル内の乗算器も2倍に増強するなど、50TOPSの性能を獲得するために数々の強化を盛り込んでいる。結果として計算能力は5倍(Ryzen 7040シリーズ基準で)、電力効率は2倍となっている。

古典的なプロセッサーデザイン(左)では、複数のコアとキャッシュが階層をなし、最終的にメモリー(DRAM)へつながる。これに対しXDNA 2(右)ではタイル状に配置されたAIEタイルを通じデータが東西南北に走るイメージだが、メモリーへ至る道が複数ある点に注目
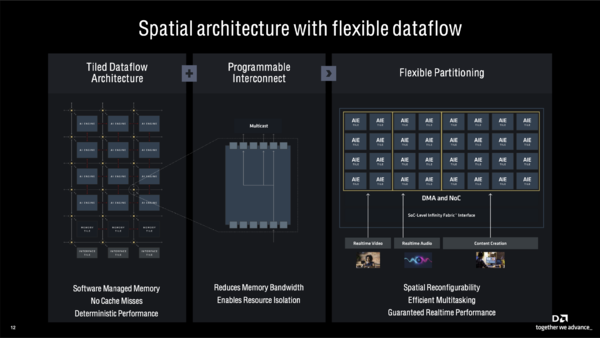
XDNA 2のタイルは隣接するタイルにどうつながるかをプログラムで随時変更できる。メモリー帯域の節約にもなるほか、複数のAI処理を同時に実行できるメリットもある

Ryzen AI 300シリーズのNPUはAIEを前世代の20基から32基に増量し、AIE内の乗算器(MAC)も2倍、オンチップのメモリーも1.6倍に増量した。すべては50TOPSの処理性能を確保するための施策である

XDNAとXDNA 2のNPUを比較した時、Ryzen 7040シリーズよりも性能は最大5倍、電力効率も最大2倍となった
XDNA 2では新たにBlock FP16のサポートが追加された。XDNAのNPUはINT8の演算を重視して設計されているが、精度を犠牲にして処理性能を稼ぐものだ。一方AI処理で多用されるFP16(BF16)は精度は高いが計算負荷は高い。
INT8の軽さとFP16の精度をバランスしようというのがBlock FP16だ。例えば8つの数値をFP16で表現する場合、データの大きさは合計で128bit長(16bit×8=128bit)となる。この各数値は必ず5bitの指数部と11bitの符合付き仮数部で構成されるが、仮に指数が同じなら5bit×8=40bitは無駄が多い。
そこでBlock FP16では、同時に扱う数値の指数部だけを括りだす。8つのBlock FP16のデータは8bitの共通指数部+8bitの符合付き仮数部×8となり、合計72bit(8bit×9=72bit)で済む。
AI処理でBlock FP16を利用すると、INT8と同じパフォーマンスが、“ほぼ”FP16の精度で実行できる。さらに学習モデルのサイズはINT8よりわずかに大きくなる(先の例でいうと8bit×8=64bitのデータが8bit×9=72bitで表現されるため)が、FP16に比べるとはるかに小さい。Block FP16あらゆる面で有利になるフォーマットなのだ。
ただAI処理でBlock FP16を使うようにプログラムの段階で手を加える必要があるし、NPUでBlock FP16をサポートしているのはXDNA 2を採用しているRyzen AI 300シリーズのみである、という事実から考えると、Block FP16がXDNA 2の覇権につながるとは安易に言うことはできない。
まず世の中のアプリがもっとAI処理を使うように進化し、そしてそのAI処理がNPUで動くようにチューニングされ、その上でBlock FP16を使うように調整されるという3つのステージを踏む必要があるのだ。
Block FP16をキッチリ使ってくれれば、Ryzen AI 300シリーズの推論処理はライバルを置き去りにするだろう。

XDNA 2ではINT8の軽やかさとFP16の精度を兼ね備えたBlock FP16がサポートされる。FP16で書かれた処理をINT8へ書き直す苦労に比べれば、Block FP16への移行は容易いという観測もある
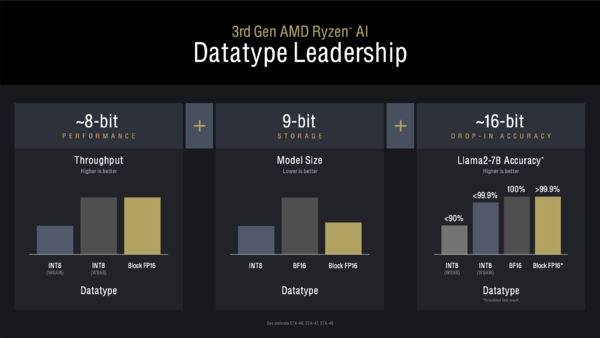
Block FP16を利用することで、パフォーマンスはINT8相当、精度はINT8よりも高くできる。さらに学習モデルのサイズはFP16よりずっと小さいとあれば、Block FP16は理想にして最強である、といえるだろう。プログラム側の対応が必要というハードルはあるが……

COMPUTEXにおけるAMDの講演の一幕。画像生成処理をINT8/ Block FP16/ FP16で実行すると、同じモデルを使っていても結果に大きな差が出る。INT8は精度が低いため質の低い画像になってしまったが、精度が確保できるBlock FP16はFP16とほぼ同じ結果が得られる
本記事はアフィリエイトプログラムによる収益を得ている場合があります













