ロードマップでわかる!当世プロセッサー事情 第766回
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ
2024年04月08日 12時00分更新

シリコン・インターポーザーはInstinct MI250Xの時と異なる構造
さてそのXCD/CCDとIODの接続方法であるが、TSVのピッチは9μmで、これはRyzenの3D V-Cacheと同じ数値であるが、そもそも3D V-Cacheは3次キャッシュの上に3D Vキャッシュを積層する形だったので面積が小さかった。ところがMI300ではXCDを積層するために、5倍以上の面積でのボンディングが行なわれた。
またボンディングの方法も変わった。基本的にトップダイとボトムダイの間をファンデルワールス力で接続、つまり接続面を極めて平坦にした上で分子間力を利用して接続する方式で、半田ボールベースのマイクロバンプではないことそのものは3D Vキャッシュと同じであるが、その接続が変わった。
3D Vキャッシュの場合、配線層の一番下ではなく、その一つ手前(M13)からBPV(Bond Pad VIA)を使って配線を引っ張り出し、それをボトムダイの上面に構成されたBPM(Bond Pad Metal)に接続する形を取っていた。
この方式を使ったのは、おそらくだが3D Vキャッシュは32MBのSRAMのダイを2枚あらかじめ重ねた上で、それをZen 4の3次キャッシュの上に積層するという構造になっている。したがって2枚の32MB SRAMダイは上下にTSVが出るような構造になっている。でないと上側のSRAMダイからの配線を下側SRAMに伝えられないからだ。
この関係で必要な配線は内部からBPV経由で外に引き出す形になっていると思われるのだが、MI300の場合はトップダイがロジック(CCDなりXCD)であり、その上にはダイが載らない。
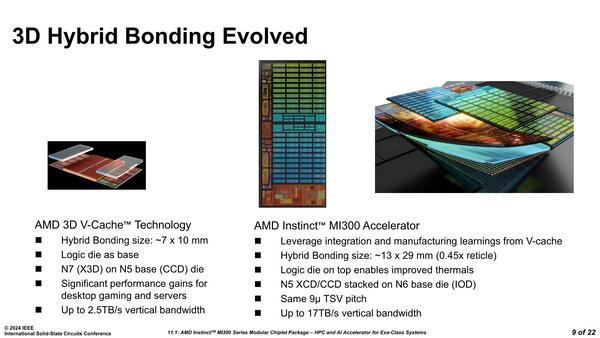
帯域そのものは17TB/秒で、意外に多くない。いやこれがXCD1つあたりだとすれば広帯域なのは間違いないが、2つで17TB/秒だとすると、案外少ないという気もする
またXCDはともかくCCDに関してはもともとはRyzenやEPYCなど、有機パッケージ上に直接バンプ経由で接続する構造になっており、M13の下(ダイ的に言えば上なのだろうが)にAlの配線が来る。そこに薄い銅ベースのBPVを挟み、これをBPMと接続するという形にしたのがMI300である。
想像だが、これはすでにあるZen 4のダイをIODの上に接続するための苦心の策なように思われる。そもそもZen 4のダイはバンプでパッケージと接続するのが前提の構造だったはずで、バンプの代わりにこのBPVをダイの底面(というか上面)に構築する形で対応したのだろうと想像される。
一方でIOD同士の接続は、シリコン・インターポーザーを経由しての接続であり、これはHBMに関しても同じである。少し意外だったのは、このシリコン・インターポーザーがInstinct MI250Xの時と異なる構造になっていることだ。
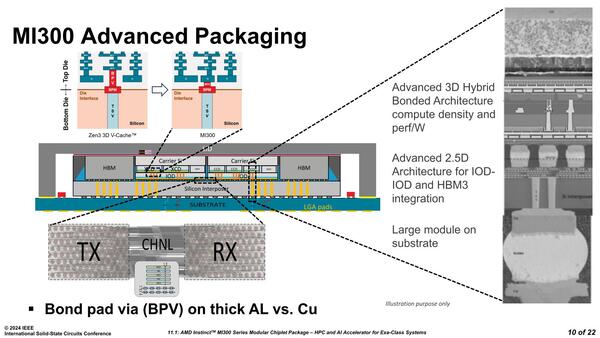
CoWoS-Lか? とも思ったが、この図を見る限りはシリコン・インターポーザーにIPD(Integrated Passive Device)やLSI(Local Silicon Interconnect)などは含まれておらず、普通(?)のCoWoSと思われる
Instinct MI250Xの際にはElevated Fanout Bridge 2.5Dが利用された。要するに実際に接続する部分(上の画像で言えば、IOD同士の接続と、IOD⇔HBM3の接続の配線部)のみにシリコン・インターポーザーを配し、後の部分(つまり2つ上の画像で言えばSubstrateと直接接続する部分)はCuの柱(Pillar)を立てるという方法だった。
これはASEの提供するFOCoS-Bridgeを利用していたものと思われる。なのだがInstinct MI300Xでは全体をカバーする巨大なシリコン・インターポーザーを利用する方式に変わった。こちらはおそらくTSMCのCoWoSベースである。
以前はCoWoSはReticle Limit(つまり1回の露光でパターンを生成できるサイズの限界)に縛られていたが、やっとここに来てTSMCが従来から主張していた「Reticle Limitの2倍≒1700mm2前後」のインターポーザーが実用になったようだ。
ただこれは「マスクとシリコンの距離を大きくする=パターンが大きく露光される」ことを利用しており、欠点として配線密度が低下する(単に2倍に拡大されるので、縦横等倍だとすると配線密度は1/√2≒0.7倍程になる)のだが、上の画像を見るとIOD同士の配線はかなり密であり、このあたりの欠点をなんらかの方法で克服したものと思われる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ













