



少量データから個人の発話と音声を再現 、NTT版LLM“tsuzumi”への適用を目指す
NTT、「デジタル分身」を低コストで生成するための技術を開発
2024年01月17日 15時00分更新

NTTは、2024年1月17日、少量データから個人の発話を再現する「個人性再現対話技術」および個人の声色を反映した音声を合成できる「Zero/Few-shot音声合成技術」を開発したことを発表した。
NTTは、現在、多様性を理解する情報処理技術の研究開発を進めており、その恩恵を自然に享受できる社会を目指す「IOWN構想」を基に、独自の大規模言語モデル(LLM)「tsuzumi」を発表。tsuzumiは、万能なLLMではなく専門性や個性をもった小さなLLMとして、AIの集合知により多様性を確保するという方針で、2024年3月の商用提供に向け研究が進められている。
それと並行して同社が注力するのが、人の個性を備えたデジタル分身である「Another Me」だ。現実の制約を超えたデジタル分身を作り、その分身が社会の中で自律的に活動することで、人の活躍や成長の機会を拡大させる取り組みとなる。「個性を持つAIであるAnother Meが協力して課題を解決し、人々の多様性が自然に世の中に浸透するという世界観」だと、NTT人間情報研究所 デジタルツインコンピューティング研究センタ アナザーミーグループの深山篤氏は説明する。

NTT人間情報研究所 デジタルツインコンピューティング研究センタ アナザーミーグループ グループリーダー 深山篤氏
Another Meのプロジェクトでは、2023年に、ペット型エージェントをメタバース上に実装する効果検証を実施。ドコモのメタバース空間であるMetaMe内で公開実証を行い、コミュニケーション活性化の効果を確認してきた。
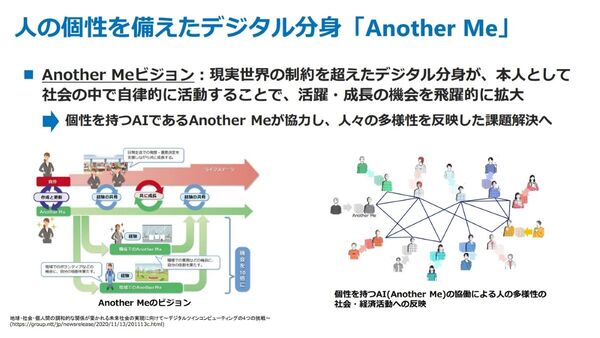
人の個性を備えたデジタル分身をつくる「Another Me」

ペット型エージェントをメタバース上に実装する効果検証
今回新たに発表するのは、「万人がデジタル分身を持てる世界」の実現に向けた研究成果だ。LLMを対話に適応させ、少量の学習データで本人らしい発話内容と音声を生成する技術となり、データの蓄積がない一般のユーザーでも、自身の代わりにコミュニケーションをするデジタル分身を持つことができる。「デジタル分身がメタバースの中で、時間の制約あるいは心理的障壁を超えて、さまざまな人々と交流することで、ユーザーの対人関係を飛躍的に拡大できる」と深山氏。
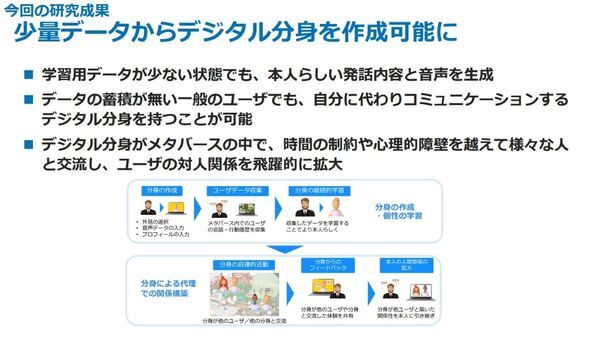
少量データでデジタル分身を作成する技術を開発
低コストでデジタル分身作成を実現する「個人性再現対話技術」と「Zero/Few-shot音声合成技術」
研究成果のひとつが、発話の内容を生成する個人性再現対話技術だ。
NTT版LLMのtsuzumiでも利用される、ベースモデルのパラメータを変えずに新たなデータで追加学習をする“アダプター技術”と、指定したペルソナに合った内容や口調での発話を生成する“ペルソナ対話技術”を組み合わせて実現している。
従来技術では、ベースとしてさまざまな人の対話データから学習するため、再現したい人の対話データが少ないと、その人らしい発話をしてくれないという問題を抱えていたという。
今回、ペルソナ対話技術により、さまざまな人の対話データにプロフィール情報をセットで学習させ、ベースとなるLLMをファインチューニング。対象のプロフィール情報をパラメータとして指定すると、ペルソナに合った発話を生成できるペルソナ付きのLLMを構築した。
このペルソナ付きのLLMを下敷きにし、再現する人に近い状態からアダプター技術で追加学習するため、より少ないデータでの効率的な学習が可能になる。
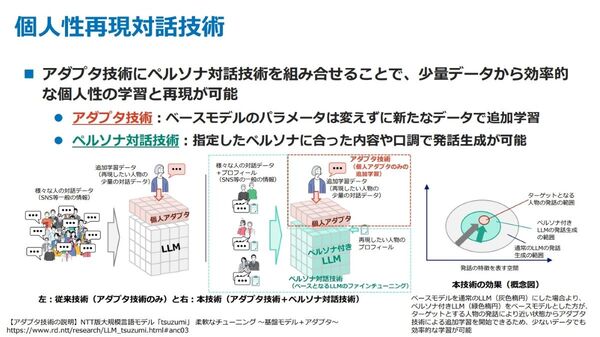
アダプター技術とペルソナ対話技術を組み合わせた個人性再現対話技術
もうひとつの技術が、音声合成を担うZero/Few-shot音声合成技術だ。
従来音声合成技術は、話者の声を生成するために大量の音声を収録し、人手でデータを整備するため多くのコストが発生していたという。そこで、幅広い用途で利用してもらうことを目的に開発されたのが「Zero-shot音声合成技術」だ。
数秒程度の話者の声を用意するだけで、音声合成モデルを学習させずに、話者の声色に類似した合成音声を生成可能となる技術である。話者の声から、声色の特徴の情報(話者ベクトル)を抜き出し、ベースとなる音声合成モデルと合わせることで声色を再現する。
加えて、著名人やキャラクターの声に関しては、数分~10分程度の音声から、再現度の高い声(声色・話し方)を合成する「Few-shot音声合成技術」も開発。こちらは、所望話者の音声から専用の音声合成モデルを構築し、高品質な音声を生成する。
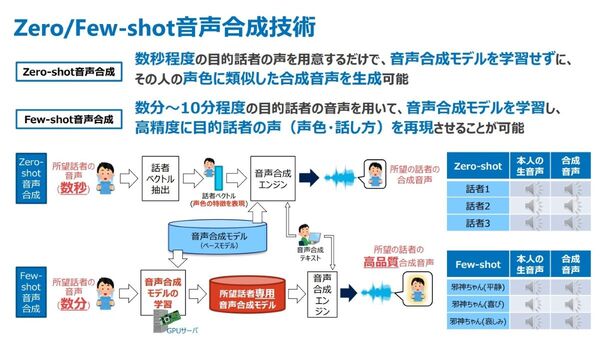
少ないデータで音声合成を可能にするZero/Few-shot音声合成技術
個人性再現機能をNTT版LLM“tsuzumi”に適用すべく精度向上に取り組む
これらの技術を採用したプロトタイプが、2024年1月17日から18日に東京国際フォーラムにて開催する「docomo Open House '24」にて展示される。
同展示のアニメキャラ(「邪神ちゃんドロップキック」の邪神ちゃん)の再現では、個人性再現対話技術およびFew-shot音声合成が用いられる。また、個人性再現対話技術とZero-shot音声合成を用いた、Another Meによるデジタル分身も体験可能だ。
NTTでは今後の展開として、デジタル分身を通じた人間関係の構築を、MetaMe上で実証実験していく予定だ。さらには、tsuzumiによる個人性再現機能の提供に向けた精度向上にも取り組んでいく。
なお、「なりすまし詐欺」など、個人を再現するこれらの技術の悪用を防ぐための対策(ガードレール)は、tsuzumiを研究していく中で、総合的に担保できるよう進めていくという。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



