





Stability AI Japanは8月17日、入力した画像の説明や画像についての質問を日本語で回答できる画像言語モデル「Japanese InstructBLIP Alpha」を公開した。
研究目的なら自由に利用可能
日本語向け画像言語モデル「Japanese InstructBLIP Alpha」公開しました!
— Stability AI 日本公式 (@StabilityAI_JP) August 17, 2023
入力した画像に対して文字で説明を生成できる画像キャプション機能や、画像についての質問に回答することもできます!
詳しくはこちら💁https://t.co/kA5zvmq9C3pic.twitter.com/6jZmTtUuq4
本モデルは、8月10日に公開された日本語向け指示応答言語モデル「Japanese StableLM Instruct Alpha 7B」を拡張し、画像を元にしたテキストを生成するモデル。ベースモデルの発表からわずか1週間というハイペースのリリースとなった。
高いパフォーマンスが報告されている画像言語モデル「InstructBLIP」のモデル構造を用い、モデルの一部を大規模な英語のデータセットで事前学習されたInstructBLIPによって初期化し、限られた日本語データセットを用いてチューニングしたという。
商業利用はできないが、研究目的であればHugging Face Hubにおいて他のモデルと同様に推論や追加学習を試すことができる。
状況説明だけでなく質問に回答も可能
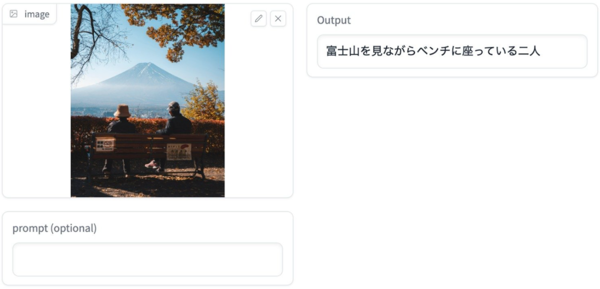
たとえば上記の例では、入力された画像を元に「富士山を見ながらベンチに座っている二人」という状況説明テキストを生成している。
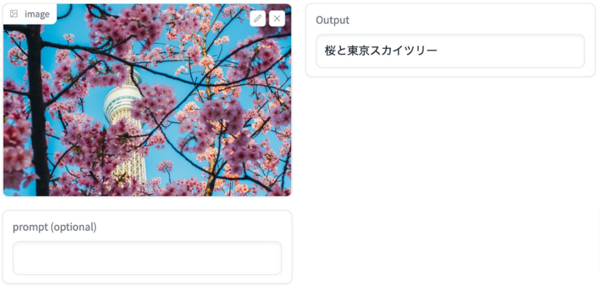
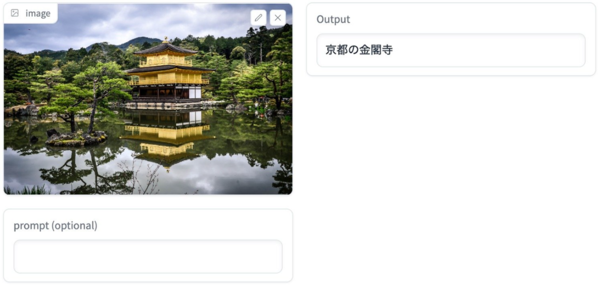
海外製モデルでは間違うことも多かった「桜と東京スカイツリー」「京都の金閣寺」といった日本特有の建造物を正しく認識できていることがわかる。
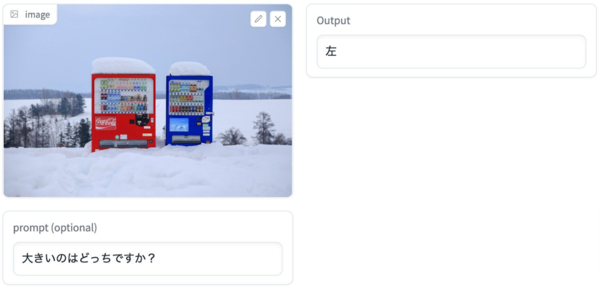
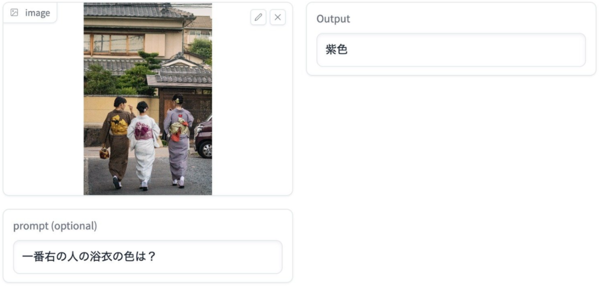
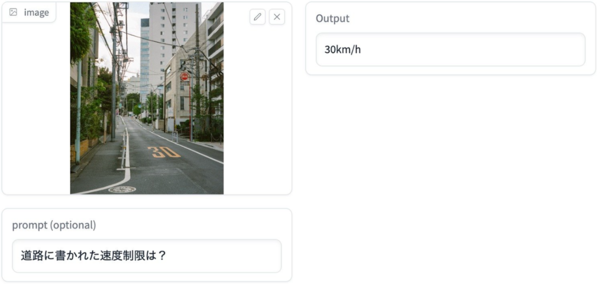
さらに、画像以外に質問などのテキストも入力可能。例えば2台の自動販売機が並んでいる画像を入力し、「大きいのはどっちですか?」というプロンプトに対して「左」と正解を日本語で出力できる。
Stability AI Japanは「英語圏と比べ、日本語のデータセットは限られており、マルチモーダル(複数のデータ形式)なデータセットはさらに限られている」と指摘。「今後も研究開発を積極的に行い、日本向けの生成基盤モデルを構築・公開することで、日本のAIコミュニティのさらなる活性化に貢献していく」としている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります















の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")




