





LINEは8月14日、36億および17億パラメータの日本語大規模言語モデル「japanese-large-lm(ジャパニーズ ラージ エルエム)」をオープンソースで公開したことを発表した。
約650GBからなる大規模日本語Webコーパスを使用
LINEが進めている複数の大規模言語モデル(LLM)の研究開発プロジェクトのうち、36億および17億パラメータの日本語言語モデルをOSSとして公開しました!
— LINE Developers (@LINE_DEV) August 14, 2023
LINE Engineering Blogにて本モデルの使い方や特徴、学習したモデルの性能などについて紹介しています。ぜひご覧ください。https://t.co/u7m1lwqZtC
LINEでは2020年11月から日本語に特化した大規模言語モデル「HyperCLOVA」の構築と応用に関わる研究開発に取り組んできたが、それと並行して複数の大規模言語モデルの研究開発プロジェクトを進行させていた。
今回公開されたモデルは36億パラメーターの「japanese-large-lm-3.6b(以下3.6Bモデル)」および17億パラメータの「japanese-large-lm-1.7b(以下1.7Bモデル)」。ライセンスは商用利用も可能なApache License 2.0となっている。
なお、本モデルの訓練にはLINE独自の約650GBからなる大規模日本語Webコーパスを利用しており、1.7Bモデルの学習にはA100 80GBで換算し、約4000GPU時間を費やしたという。
タスクによっては「Rinna-3.6B」を上回る性能
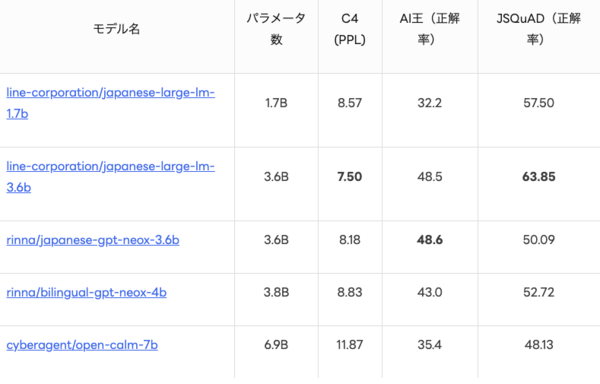
ベンチマーク結果
出現する単語をモデルがどの程度正確に予測できたかを計測するPerplexityスコア(PPL)および、質問応答・読解タスクの正解率で評価したところ、1.7Bモデルはサイバーエージェントの「OpenCALM-7B」と同等かタスクによってはよい性能を、3.6Bモデルはrinnaの「Rinna-3.6B」と同等かタスクによってはよい性能を達成可能なことがわかった。
近日中には、これらのモデルについて、指示文に対して適切な出力を行えるようにチューニング(Instruction tuning)したモデルも公開されるという。
本記事はアフィリエイトプログラムによる収益を得ている場合があります





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















