




MCCとXCC、どちらも化け物
さて、Sapphire RapidsのXCCの内部構造は、以前何度か説明した。最初に説明したのは連載586回だが、この後いくつか新情報があり、補正したのが連載631回で筆者が示した図である。ただこの構造でもまだ間違っていた。どのあたりが間違っていたか、というと「EMIB経由の通信はUPIではない」ということだ。
下図は、XCCにあるタイルの内部構造「推定図」である。なぜで推定か? というと、インテルが示した画像では潰れて見えないためである。ただこの構造そのものは、Skylake-SPベースの初代Xeon Scalableから共通のもので、縦横のリングバスでメッシュの構成となる。
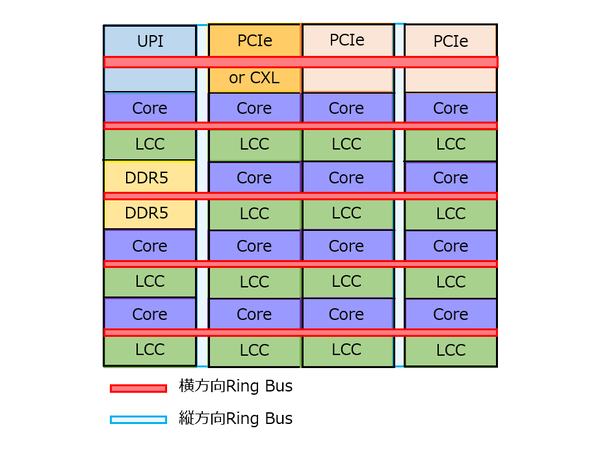
XCCにあるタイルの内部構造推定図
ブロック(黒枠)は全部で20個あり、うちCPUコアが15個、PCIe I/Fが2個、PCIe/CXL I/Fが1個、UPIが1個、DDR5 2chのメモリーコントローラーが1個という構図と思われる。
インテルが示したタイルアーキテクチャーの構造図。潰れて見えない……
なおUPIにはおそらくDMIのI/Fも含まれていると思うが、ここではこれは無視する。上の画像の左図にある左上のタイルを模した格好だ。リングバスは横方向が5本(うちPCIeやUPIをつなぐリングのみやや太いので、これのみ2対なのかもしれない)、縦方向が2本になっている。
さて、4タイルのXCCではこれがどうつながるか? というのが下図だ。要するに4つのタイルの内部にある、縦横のリングバス同士をEMIB経由で接続することで、物理的には4つに分割されていつつも、論理的には1つの巨大なモノリシックなダイが構築されることになる。
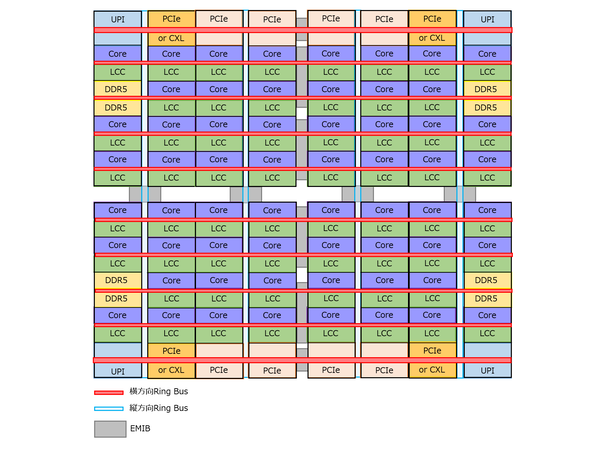
4タイルの構造推定図
なにせ縦方向4本、横方向10本の巨大なメッシュである。この際EMIBは、縦方向は1本で1つ、横方向は2本あたり1つ(I/F同士の接続は1本で1つ)配されており、合計で10個という計算になる。インテルとしては、UPI経由での接続にすることでのレイテンシーの増加や帯域の制限はどうしてもいやだったらしい。
このあたりは、それを割り切ってインフィニティ・ファブリックでの接続としたEPYCとの大きな相違点である(どちらが良い悪い、というのは簡単には断じることができないが)。結果としてXCCは、論理上は1600mm2にもおよぶ巨大なモノリシック・ダイのプロセッサーになったわけだ。
なおXCCとHBMの違いだが、HBMではコアの数がタイルあたり14個に減り、その代わりにHBMのI/Fが搭載された形になっている。HBMのI/FとDDR5のメモリーコントローラーが別、というのは以前HotChipsで明確に返事をいただいており、またXeon MAXはハイエンドの9480でも56コア(つまりタイルあたり14コア)であることから、下図のような構成と考えられる。
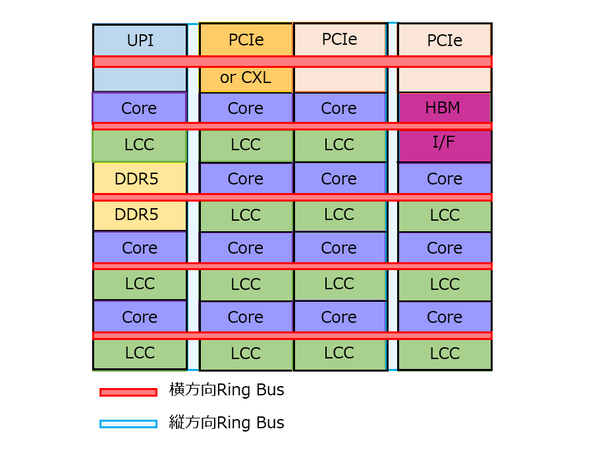
Xeon MAXの構造推定図。なぜ右端に寄せたか? という理由は後述する
もっとも、怪しいのはそもそもそこまでHBM2eのI/Fは大きいのか? という疑問があるからだ。次に説明するが、このHBM I/FにはPHYは含まれていない。純粋にその上位のコントローラー部のみである。
実はHBMとXCCは物理的には同じタイル(つまり15コア+HBM I/Fが全部入っている)で、HBM I/Fを無効化したのがXCCタイル、コア+LCCを1ブロック無効化したのがHBMタイルという可能性もなくはない。
ただ公式のインテルの見解は別のもの、ということになっているのだが、記事冒頭の画像でXeon MAXの欄を見るとダイチップが“XCC”と書いてあるあたり、少し怪しい気がする。
さてXCCの話はこのくらいにして次はMCCである。今回インテルはMCCのダイを一切披露していない。ただインテルが示した画像で大まかに構成はわかる。ということで下図がその推定図である。
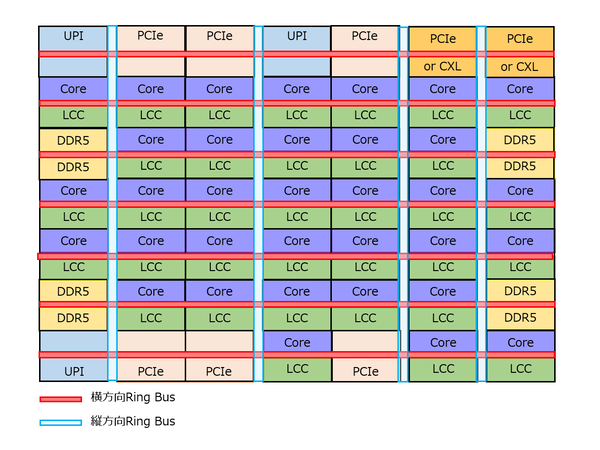
MCCの構造推定図
横方向7本、縦方向4本のリングバスでメッシュを構成しており、ブロック数は7×7で49個。うち32個がCPU+3次キャッシュで、残る17個がI/F類というかたちになる。ところでこのMCCのサイズはどのくらいだろうか? 下の画像は、インテルが公開したXCCのウェハー写真である。
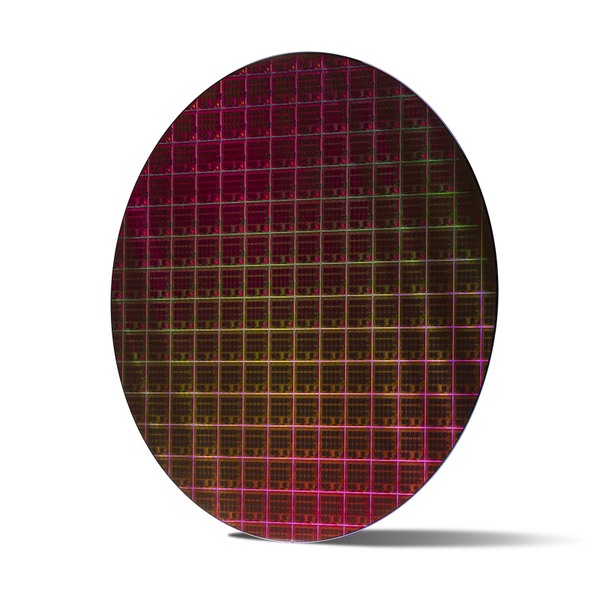
XCCのウェハー
例によって斜めからの撮影なのでけっこう歪みがある。そこで大雑把に歪みの補正を行なったのが下の画像だ。
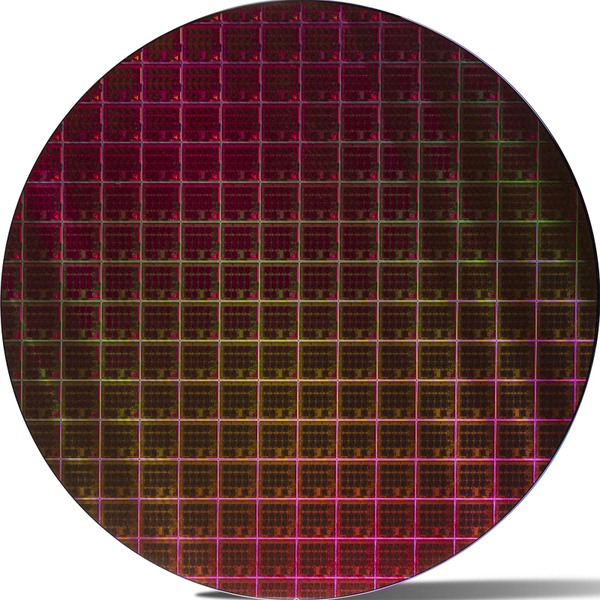
ちなみに取れるタイルの数は148個。歩留まりが100%として、タイル1個あたりの製造原価はほぼ100ドル程度、それが4つで400ドルとなる。もっともパッケージング(EMIBの採用があるので高くなる)やテストなども込みにすると、製品原価は600ドルくらいだろうか?
300mmウェハーで、縦横ともにタイル15個分ほどであり、ダイサイズは事前説明があったように20×20mmと計算される。ウェハーの中心部を拡大したのが下の画像であるが、CPUとDDR5、I/Fからなる20ブロック(つまり赤/黄/橙/青/水色で囲った部分)の面積は17.0×15.5mmほどと推定される。この20ブロックで263.5mm2、ブロック1個あたり13.18mm2ほどになる計算だ。
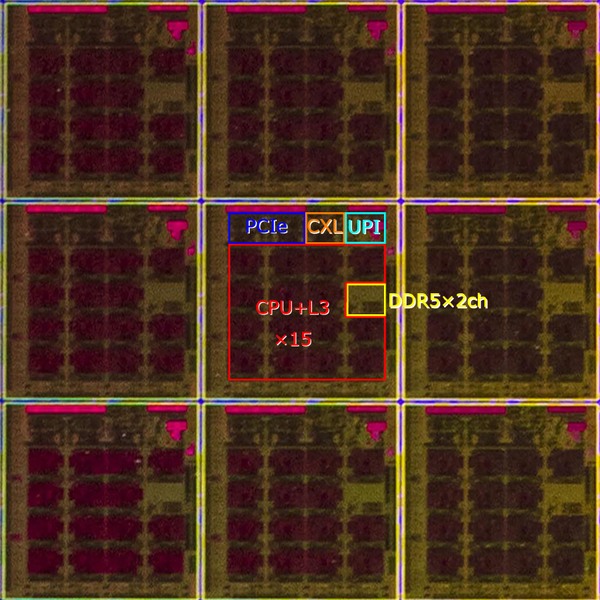
XCCのウェハーを補正したもの。記事冒頭の画像の左側で言えば、右上(と左下)のタイルに相当すると考えられる
ここでDDR5×2chのブロックのすぐ右は、DDR5のPHYが占めていると考えられる。一方左および下側は未使用のエリアに見えるが、ここにはアンコアの部分、つまりアクセラレーター類が搭載されているのだろう。
HBMタイルに関して言えば、左側の空いている部分にPHYが来るのではないか? と筆者は考えている。このアクセラレーターとDDR5のPHY(と、もしかするとHBMのPHY)の面積は、400mm2から20ブロックの分を抜いた136.5mm2ほどになるという計算だ。
さてここでMCCに話を戻す。MCCの構造が想定図のとおりだとすると、この49ブロック分の面積は13.18×20≒645.8mm2ほどになる。MCCはHBMのI/Fは持たない一方、DDR5が8ch分出てくるので、PHYの面積はそれなりになる。それ+アクセラレーターの分まで加味すると、大雑把に言って750mm2かそれ以上になる計算だ。
つまり相当大きい(レティクルリミットに挑戦する)サイズになると考えられる。こうなってくると相当歩留まりも低そうな感じであり、どこまでちゃんと取れるのか心配になる。ウェハー1枚から取れる個数は試算では75個前後になる計算で、製造原価は200ドルほど、製品原価で300ドルは切らないだろう。
このMCCを使う一番安い製品はXeon Bronze 3408Uだが、諸費用を考えるとギリギリ赤字になるかならないか、というあたりの際どい値付けであることがわかる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























