





マイクロソフトは1月5日(現地時間)、3秒間の声のサンプルを使用するだけで、その人の声を真似た音声を合成できる言語モデリングアプローチ「VALL-E」を発表した。
しゃべらせたいテキストと3秒間のお手本音声を入力するだけ
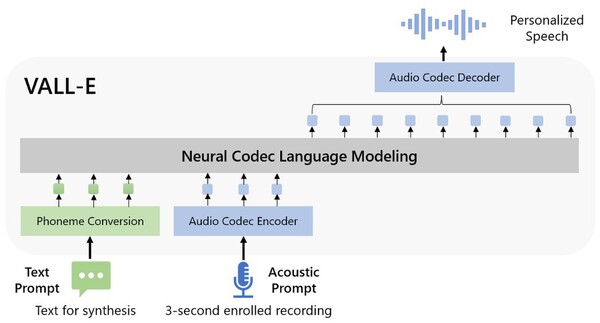
概念図
「ニューラルコーデック言語モデル」と呼ばれるVALL-Eは、Metaが2022年10月に発表した「EnCodec」というAIを使った音声圧縮技術をベースにしている。
論文によると、しゃべらせたいテキスト(Text Prompt)と、お手本となる3秒間のサンプル音声データ(Acoustin Prompt)を入力すると、事前にトレーニングされたデータを使って分析し、その声が3秒間のサンプル以外のフレーズを話した場合にどう聞こえるかをAIが予測し、まるでお手本を録音した人がしゃべったかのようにテキストを再生できる。
トレーニングは、やはりMetaが作成した7000人以上の話者による6万時間を超える英語の音声ライブラリ「LibriLight」を使用して実施されており、サンプル音声がトレーニングデータの音声に近いものであればあるほどよい結果をもたらしてくれるという。
「怒った声」や「電話越しの声」も再現できる

LibriSpeechによるサンプル
それでは実際に合成された音声を聞いてみよう。マイクロソフトが用意したデモページには、Metaが作成した音声データセット「LibriSpeech」を使ったサンプルデータを聞くことができる。
一番左の「TEXT」がしゃべらせたいテキスト、その右にある「Speaker Prompt」がお手本となる3秒間の音声だ。この2つを元に生成される音声が一番右の「VALL-E」だ。
「Ground Truth」は、お手本と同じ話者がそのフレーズを発声した既存の録音、つまり正解となる。「VALL-E」と聴き比べてみると、サンプルによって出来不出来はあるが、声の音色だけではなく、アクセントやスピードなども再現されていることがわかる。
なお、「Baseline」は従来の音声合成方式による合成例だ。「VALL-E」と比べるとかなり平坦に聞こえる。

多様性のサンプル
また、生成時に必要なパラメーターを変えることで、トーンやアクセントなどが異なる多様性のあるサンプルを複数生成できる。

音響環境の変化によるサンプル
さらに、サンプル音声の「音響環境」を再現することも可能。例えばサンプル音声が電話越しに録音された音声だった場合、電話の音響特性や周波数特性が合成された音声にも適用される。
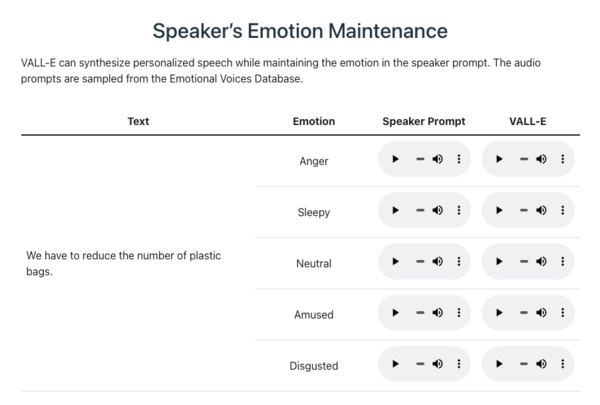
話者の感情によるサンプル
同じ文章を「怒っている」、「眠い」、「普通」、「楽しい」、「ダルい」といった様々な感情を持ったサンプル音声を使って生成した例。AIは感情まで模倣できるようになったのだ。
犯罪に利用される可能性もあるため公開は微妙
このように、たった3秒のサンプルデータで驚くべき音声合成精度を持つVALL-Eだが、もちろんまだ進化の余地はある。単純に、手本となるサンプルデータや事前学習データの量を増やすだけでも、よりリアルな音声を合成できるだろう。
また、GPT-3のような言語生成モデルと組み合わせることで、「自分の声でしゃべるAIボット」を作成することもできるようになるだろう。
とは言え、現状利用できるのは英語のみ、多言語に対応するためには英語以外の学習用データセットが充実する必要があるだろう。
現時点でVALL-Eは一般公開されていない。ディープフェイク動画などと組み合わせることでなりすまし詐欺など犯罪に利用される可能性が高いからだろう。
このような倫理的問題に関してマイクロソフトは、「実用化の際にはサンプルデータを提供する話者の同意を得る仕組み、合成されたデータを検出するシステムなどのコンポーネントを提供する必要がある」と声明を出している。
少なくともこの準備が整うまでは一般公開されることはないだろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります














&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")

















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












