




Confidential Computingとは
TEEでデータを保護すること
先ほど後回しにしたConfidential Computingは、ここまで説明したTEEの上位の概念になる。もともとは2019年8月に、Linux Foundationがセキュアなコンピューティング環境を構築しよう、ということで立ち上げたのがC3ことConfidential Computing Consortiumであり、オープンな形でセキュアな環境を提供するためのフレームワークや仕様の策定を行なっている。NVIDIAもこのC3のメンバーである。
ところでC3においてはConfidential Computeを「ハードウェアベースのTEEで処理を実行することで、利用中のデータを保護すること」としており、具体的には「コードの完全性(不正なプログラムが実行されない)、データの完全性(不正なデータを注入されたりしない)、データの機密性(データが外部に流出しない)、という3つの主要な特性に対して、あるレベルの保証を提供する環境」と定義されている。
レベルについては別途定義されているが、今回は別にTEEの説明をしたいわけではないので割愛するとして、HopperではこのC3の定義するTEEに準拠する形で自身もTEEを実装しており、それもあって「業界では初めてConfidential Computingに対応したGPUである」と説明している。
第4世代NVLinkを18本搭載するGH100
さて次はNVLink絡み。Hopper世代では第4世代のNVLinkが実装された。GH100の場合、このNVLinkが18本搭載される。
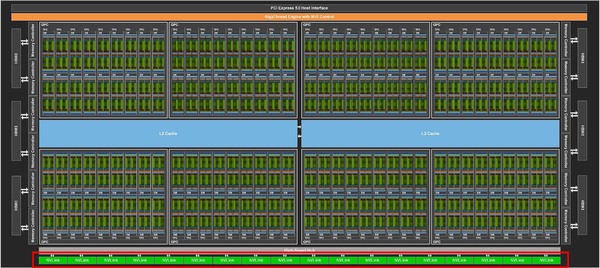
一番下段の赤枠部参照。NVLinkが18本搭載されているのがわかる
1リンクあたり25GB/秒(片方向あたり:双方向では50GB/秒)なので、18リンク合計では900GB/秒もの帯域をカバーする。A100の場合は、速度は同じく片方向当たり25GB/秒だが、1枚のA100から最大12リンクしか出せなかった。
これを利用したDGX H100の構成が下の画像だ。8つのH100から、それぞれ4本づつのNVLinkが、4つのNVS(NV Switch)に接続される格好だ。NVSの方は最大64ポートということで、8枚のH100程度なら十分お釣りが来る。

SHARPとはNVIDIAが買収していたMellanoxが保有していた、Scalable Hierarchical Aggregation and Reduction Protocolのこと。Map/Reduceをネットワークプロトコルで実施する、と言えばわかりやすいか。元はInfiniBand向けのものだが、これをNVLinkに持ってきた形だ
少し意外だったのは、この構成ならH100とNVSの間をそれぞれ4リンクづつつないで、200GB/秒にしても良かったのではないか? と思うのだが、NVLinkではポートトランキングをサポートしていないようだ(資料を調べると、Trunk動作をできなくはないようなのだが、GPUとNVSの接続には利用できないらしい)。
SHARPの動作例がこちらで、トラフィックそのものを減らすことで実効性能を最大2倍にできるというものだ。もっとも、なんでもかんでも2倍にできるわけではないので、使いどころはやや限られてくるだろう。

SHARPの動作例。まとめられるものはまとめる仕組みである
ちなみにNVIDIAの説明によれば、このDGX H100が最小単位として、そのDGX H100を32ユニット接続するのはそのままNVLinkで可能であり、これを超える構成はInfiniBandでつなぐという構成で、1024ユニットまで接続できるという話である。

DGX H100を32ユニット接続するのはNVLinkで可能。右の図で、下側は2つ上の画像を上下逆にしたもの、つまりDGX H100そのものである

InfiniBandなら1024ユニットまで接続できる。ここまでくると、確かにDGX A100よりは帯域は上かもしれないが、NVLinkとInfiniBandのデュアルネットワークよりも、いっそInfiniBandの大規模スイッチを入れた方がレイテンシーが少ないのでは? という気がする
DPX命令を利用すると
Ampere世代より7倍高速化する
それともう1つ、DPX命令についても触れておきたい。こちらはまだ詳細は明らかになっていないのだが、DPX命令とはDynamic Programming、日本語では動的計画法と呼ばれる技法である。簡単に言えば、複雑な再帰的問題を、より単純な部分問題に分解して解くアルゴリズムで、例えばゲノム解析ではSmith-Waterman法、ロボット工学ではFloyd-Warshallアルゴリズムといった手法が有名になっている。
NVIDIAがこれに対してどういう命令セットを提供しているのかが今ひとつはっきりしないのだが、NVIDIAによればGH100で搭載されたDPX命令を利用すると、こうした動的計画法の実行をAmpere世代と比較して7倍高速化できた、としている。
ということで661回と今回でGH100/H100の特徴を説明してきたが、ごらんの通り全然コンシューマー向けには要らない機能が満載であって、やはりHopperはGPGPU向け専用ということで終わりそうだ。やはりコンシューマー向けはAda Lovelaceベースのものになるだろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























