




先々週に引き続き、今週もNVIDIAのHopperと、少しだけGraceの話をお届けしたい。前回はGH100のコア部分のみの紹介で終わってしまったので、今回はその周辺部の話である。
具体的には先々週に冒頭で名前だけ挙げた、第2世代のMulti-Instance、Confidential Computing、第4世代NVILink、DPX命令セットなどである(Transformer Engineは先々週紹介している)。

GH100チップ
GPUを仮想マシンの数に分割できる
第2世代マルチ・インスタンスGPU
まず第2世代のMIG(Multi-Instance GPU)について説明しよう。MIGは、1つのGPUを複数のVM(仮想マシン)で分割して利用できるというものである。
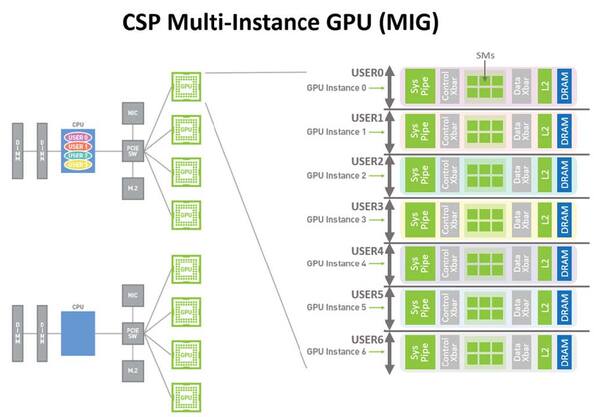
MIGの概念図。このレベルで言えば、A100もH100も差はない
この機能はAmpere世代で導入されたもので、1枚のGPUの上で7つのインスタンスを実行できる。なにを言っているのかと言えば、サーバーの上でVMを最大で7つ立ち上げ、この7つがおのおの自分専用としてGA100なりGH100なりをインスタンスの数だけ占有できるということだ。
上の画像の例は、7つのVMがそれぞれ1つづつインスタンスを占有する例だが、この数は必ずしも1つである必要はなく、例えばUser 0がInstance 0~3の4つを占有、User 1がInstance 4・5を占有して、User 2がInstance 6を占有、という使い方もできる。
このインスタンスはGPC(Graphics Processing Cluster)ごとに1個づつ作られるので、GA100の場合は7 GPCということでインスタンスが7つまでという制限であった。ではGH100だと8 GPCになるからインスタンスは8つか? というと、GA100との互換性を保つために引き続きインスタンスは7つまでに制限されている。
その意味では利用できるインスタンスの数そのものには違いがないが、なにしろGA100とGH100ではGPCあたりの構成もSM(Streaming Multiprocessor)自身も異なるので、ラフに言って3倍の演算性能と2倍のメモリー帯域が利用可能になる、としている。
逆に言えば、粒度が大きくなりすぎている気もするが、連載661回で説明したようにGH100世代ではDSMEM(Distributed Shared Memory)という仕組みが導入され、1つのGPC内部で複数のSMがデータを共有しやすくなっている。
そういうわけでGPCを分割するとDSMEMの仕組みが使えなくなってしまう恐れがあるわけで、インスタンスの最小単位はGPCとせざるを得ない部分もあるだろう。あるいは将来はもう少しGPCに含まれるSM数が減り、その分GPCの数が増えるといった拡張が施されるのかもしれないが。
話を戻すと、ではGH100とGA100の違いは、GPCあたりの演算性能/メモリー帯域の引き上げだけか? というとそうではなく、Confidential Compute/TEE(Trusted Execution Environments)への対応などが新たに追加されている。
内部データを暗号化して
安全性を高める「TEE」
Confidential Computeの話は後述するので、先にTEEについて説明する。Ampereの世代では、例えば7つのGPCをそれぞれ別のVMに割り当てるできるし、VMそのものはあくまで自分に割り当てられたGPCしかアクセスできない仕組みになっている。
ただそれはそういうふうにハイパーバイザーが設定しているだけという話であって、例えば悪意を持った侵入者により改竄されたハイパーバイザーがこっそりインストールされてしまっていると、外部からそのGPCにアクセスしたり、あるいはあるVMが自分に割り当てられていないGPCの中身を参照することも不可能ではない。
そうした問題があっても、参照されたり改竄されたりできないようにしよう、というのがTEEである。
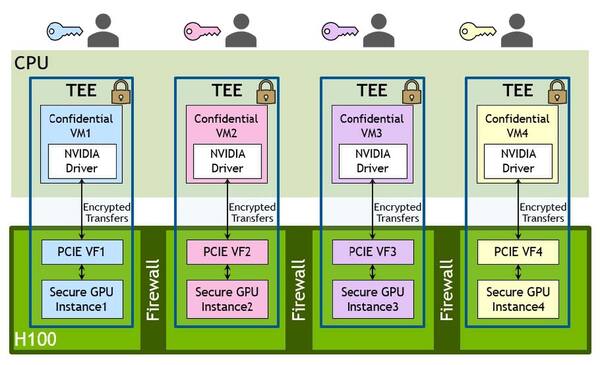
TEEではGPC間にファイアーウォールが設けられ、またVMとGCPの間の通信も暗号化される
このTEEの仕組み、実はArmが2021年6月頃に発表したCCA(Confidential Compute Architecture)と、その実装メカニズムであるRealmに近いものがある。もっともArmの技術を使ったわけではなく、セキュアな実行環境を提供しようとするとどうしても実装の基本的なアイディアは似た物にならざるを得ない、という話である。
それともう1つ、後述するGraceとの絡みもあり、NVIDIAはここで言うCPUにx86だけでなくArm(それもArm v9)を想定している。まだ明確に発表されたわけではないが、おそらくGraceはCCAに基づく実装がなされており(これはNVIDIAがArmのアーキテクチャー・ライセンスを保有している以上、当然の権利である)、おそらくRealmも実装されている。となるとRealmからGH100を呼び出す形になるわけで、それはCCA/Realmと互換性のある実装になるのは当然だろう。
したがって、VM側はセキュアな実行環境、つまり外部から攻撃を受けにくく、受けても重大な影響が出ないような環境を構築した上でアプリケーションを実行していることを前提に、このVMが利用するインスタンス(つまりそのVMに割り当てられたGPC)も、途中のデータ通信を暗号化することで、通信の傍受やGPCに直接アクセスしても、その中身が外部に流出しない仕組みがHopperには実装されている。
要するに、外部から参照されても内部データが暗号化されているので、暗号化のキーがない限り中身が読み取れないわけだ。これにより、安全性を高められるというのがTEEである。
ちなみにAmpereからの変更点として、MIGごとに最低1つのNVDEC(動画デコーダー)とNVJPG(静止画デコーダー)の機能が提供されることになっている。また、MIGごとにPerformance Monitorを利用可能なのもAmpereからの改良点である(ちなみにこのPerformance MonitorはNVIDIA提供の開発者用ツールから利用可能)。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























