




Thread Blockを複数まとめた管理単位を新たに追加
複数のSM間でメモリーの共有や同期を高速に行なえる
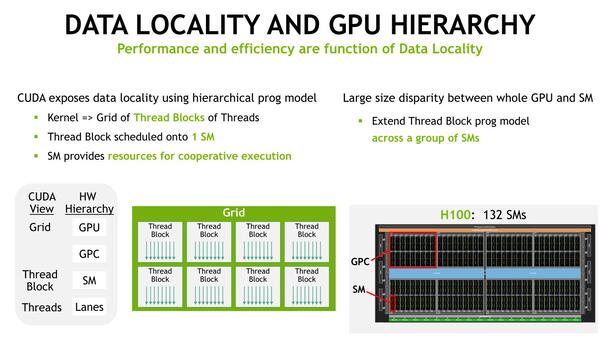
次にTBC(Thread Block Cluster)について。これは比較的小規模な処理を効率的に行なうために新たに導入された仕組みである。A100世代まで、処理はスレッドの塊(Thread Block)単位で行なわれ、このThread Blockは1つのSMに割り付けられる構成になっていた。
あくまでThread Blockがペナルティなしでアクセスできるのは、自分に割り当てられたVMのShared Memoryのみである
SMの中で処理が完結すれば問題ないのだが、他のSMに割り当てられたメモリーの内容の参照などには余分なコストがかかることになる。そこでThread Blockを複数まとめたTBCという管理単位を新たに追加、このThread Blockに属する複数のSM間でメモリーの共有や同期を高速に行なえる仕組みを新たに追加した。

ここに出てくるInter-Block Shared memory accessが、2つ下の画像に出てくるDSMEMである
ちなみにTBCは最大16Thread Blockまでとなっており、このTBCは1つのGPC内に収まることが保証されている。
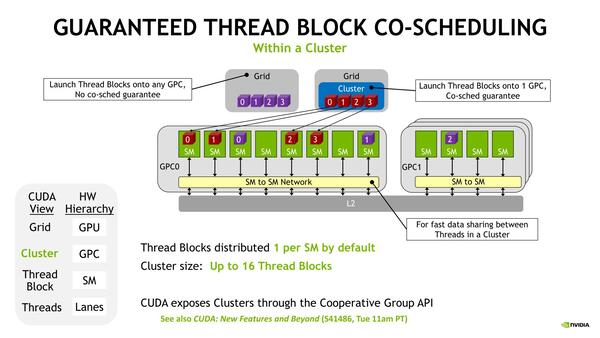
TBCは1つのGPC内に収まる。逆に言うと、1つのGPC内に収まらないような大きな処理は、TBCの恩恵を受けられないことになる。GPCは18SM構成なのになぜ16SMなのかは、実際のSM数はGPCあたり16ないし17に制限されており、この低い方に合わせたのだと思われる
GPC内のSM間のメモリー共有メカニズムがDSMEM(Distributed Shared Memory)で、これによりTBC内のデータ交換が高速で行なえるようになったそうだ。A100比ではレイテンシーが7分の1になったという。
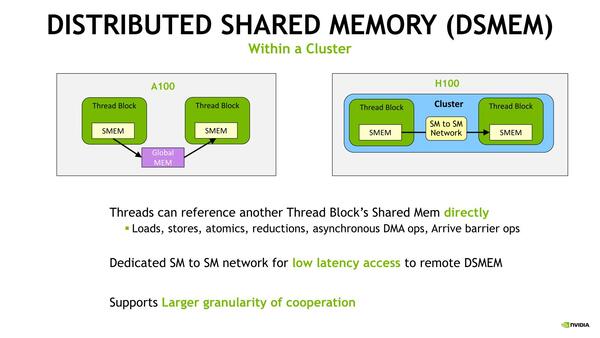
あくまでもこのDSMEMは1つのGPCの中でしか使えないのだろう
DSMEMは、256K L1 Data Cache/Shared Memoryから任意のサイズを割り当てできるそうで、サイズは任意に選べる模様だ。このTGCの利用により、64K個のFFTの処理で2倍、Longstaff-Schwartzモデル(金融工学の価格付けモデルの1つ)で2.7倍、Histogram Collectionで1.7倍の性能を発揮できるようになったとのことだった。
メモリー周りではもう1つ、TMA(Tensor Memory Accelerator) Unitと呼ばれる仕組みが導入された。
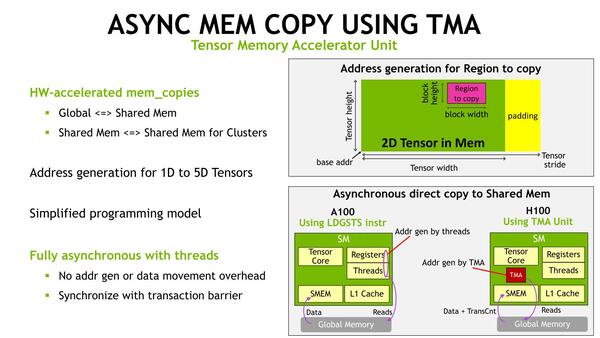
DMAエンジンは通常1次元のアドレス生成しかできないが、TMAは最大5次元のメモリアクセスが可能、というのが大きな違いかもしれない
もともとA100の世代で、非同期処理に向けてAsync Copyと呼ばれる仕組みが導入されている。あるスレッドでデータの処理中に、その処理の完了を待ってから次のデータアクセスをしようとすると、どうしても待ちが発生する。そこで処理の完了を待たずに次のデータアクセスを始めることで、処理が完了したら次のデータにすぐアクセスできるという仕組みだ。
ただA100の世代では、Async Copyは実際にはSM内のLoad/Storeユニットが処理しており、事実上はあるスレッドがそうした非同期のデータアクセス処理を実施しているというだけに過ぎなかった。
これに対し、H100世代ではデータアクセス(のためのアドレス指定)を行なうTMAというユニットが追加され、これが自動的に次のデータアクセスをしてくれる。要するにDMAエンジンみたいなものだ。これにより、より効率的にAsync Copyが可能になったとされる。
なお先にTCGで性能が上がったという話をしたが、あの性能向上はTCGに加えてこのAsync Copyを利用したTransaction Barrierの効率化が貢献しているという話であった。これは、スレッド間の同期待ちの間、A100世代ではメモリーアクセスができないが、H100世代ではTMAを利用して次のデータの準備ができるからだ。
ここまでスライドには出てこなかったが、GH100では6スタックのHBM3メモリーを実装しているのだが、実際にホワイトペーパーを読むと「H100 SMX5モジュールは、5スタックで80GBの容量を持つHBM3メモリーを搭載し、合計で3TB/秒のメモリー帯域を持つ。これは2年前に発表したA100の2倍のメモリー帯域である」と記述されており、実際には5スタックでの利用になっているようだ。
つまりスタックあたり16GBであり、現状HBM3が1znm~1αnm世代 DRAMで実装されていることを考えると、16Gbitチップの8層構成と考えられる(仕様的には最大12層まで可能)。
むしろおもしろいのはメモリー帯域である。HBM3は1024bit幅で最大6.4Gbpsの転送速度なので、このピーク値ではスタックあたり819.2GB/秒。これを5つ並べれば4TB/秒の帯域になるはずだが、上のホワイトペーパーの記述によれば3TB/秒であり、速度そのものは4.8Gbpsに抑えたものが使われていると考えられる。
というあたりが大まかにGH100の特徴ということになる。ちなみにここまではH100 SMX5、つまりSMXモジュールのものだけを説明してきたが、これとは別にH100 PCIeというPCIeカードのものも用意されていることが明らかにされている。
こちらはGH100を搭載しているものの、7あるいは8HPC、114SM構成で、しかもメモリーはHBM2eに変更され、また消費電力は350WとH100 SMX5の半分に抑えられている。
ホワイトペーパーによれば「H100 SMX5 GPUの65%の性能を、50%の消費電力で実現している」とされる。先にGH100 SMX5におけるブーストクロックを1730MHzと推定したので、そこから考えるとH100 PCIeはブーストで1300MHzほどにクロックが抑えられていると思われる。
Hopperベースのコンシューマー向け製品が
仮にあったとしても中身は大分変わるハズ
最後にコンシューマー向けへの展開であるが、少なくともGH100のままでは不可能と思われる。というのは、以下の3つの問題点があるからだ。
1つ目は、RT Coreが存在しない(のでレイトレーシングが一切できない)こと。
2つ目は、全体の4分の1の性能でしかグラフィック出力ができないこと。3Dレンダリングそのものは可能で、ホワイトペーパーにも「全体のうちSXM5とPCIeのH100は、どちらも2つのTPCのみグラフィック出力可能であり、Vertex/Geometry/Pixel Shaderを実行できる」と書かれている。
3つ目は、ビデオエンコーダーであるNVENCが搭載されていないこと。NVDECつまりビデオデコーダーは搭載されているが、無理やりGPUカードに仕立ててもおそらくGeForce RTX 3050や3060程度の性能(でしかもレイトレーシングが使えない)ということになる。
これらの問題点があるにもかかわらず価格が高騰するのが見えている。コンシューマー向けは、仮にHopperベースであったとしても中身は大分変わることになるだろう。もちろん現時点でNVIDIAはコンシューマー向け製品に関しては一切ノーコメントである。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























