




Frontierは2つのRadeon Instinctを搭載すれば
100キャビネットで1.5 EFlopsを達成できる
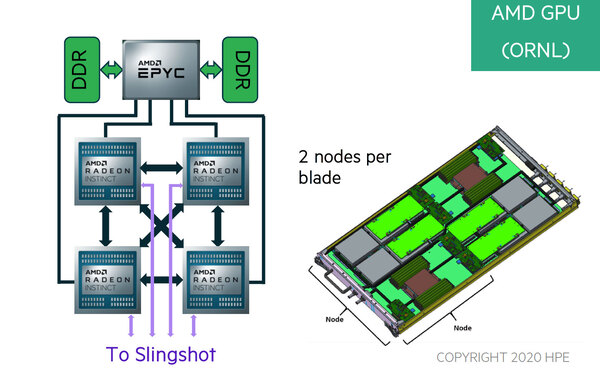
FrontierのNODE Diagram
ところで前の画像(NODE Diagramのもの)をもう一度見直すと、1本のラックモジュールに2つのノードが搭載される格好になっている。この構成が下の画像である
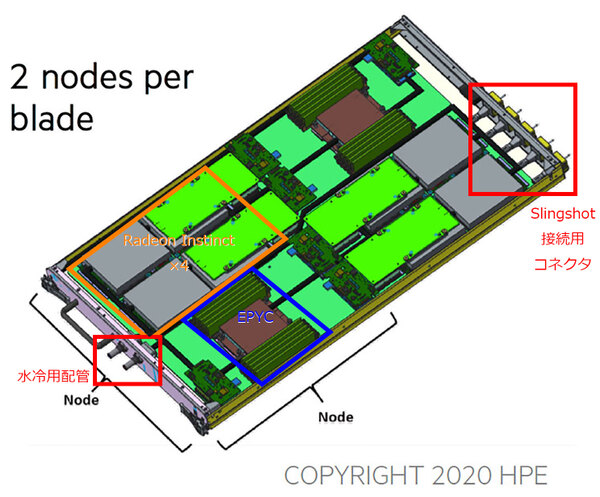
前の画像にある右下の図を拡大していろいろ書き込んでみた
一見して「電源ユニットがどこにあるの?」「冷却用の配管が入出それぞれ×1で足りるの?」「Slingshot接続用コネクターは、1つで2系統分の接続が可能?」といくつか突っ込みどころはあるものの、モジュールの高さはほぼDIMMと同じ程度で、ラックモジュールは高さが1Uのように見える。HPEがどんなキャビネットを納入するかはまだ不明だが、42Uだとすると最大で84ノードが1本のキャビネットに収まる格好になる。
オークリッジ国立研究所によればFrontier全体の構成は100キャビネット以上とされている。100キャビネットなら8400ノード程になる計算だ。この100キャビネットのままだと仮定すると、1.5EFlopsを実現するためには、1ノードあたり178.6TFlopsを達成すればいい計算になる。
ただ実はこれもけっこう敷居が高い。現行のRadeon Instinct MI100の性能がFP64で11.5TFlopsなので、4枚でも45TFlops程度でしかない。こちらもEPYC同様、最終的には第2世代のCDNAベース製品に刷新されるのかもしれないが、それにしてもギャップがありすぎる。
これに関して筆者の推定であるが、実は先の図で1つのRadeon Instinctと描いたものが、2つのRadeon Instinctを搭載したモジュールだと仮定すると、このギャップはもう少し縮まることになる。
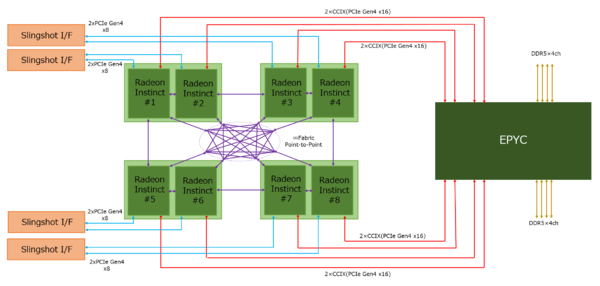
Radeon Instinctを搭載したノード構成推定図
連載590回にもあるように、もともと次世代のRadeon InstinctではInfinity Fabricを利用して8つのRadeon Instinctを相互接続する構成になっていた。
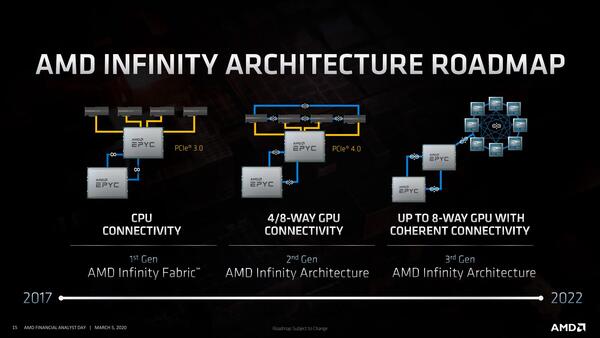
次世代のRadeon Instinctは、Infinity Fabricを利用して8つのRadeon Instinctを相互接続する
これはインテルがPonte VecchioをXe-Link経由で相互接続するのと同じことになる。発表はAMDの方が先なので、別にインテルの真似をしたというわけではなく、結局こうなったという話だろう。
これなら、ダイそのものが変わらなくてもモジュールあたりの性能は倍の23TFlopsだから、ノードあたり92TFlops。次世代のCDNA(CDNA2)は、公式には“Advanced Node”で製造とされているが、仮にTSMCのN5だとするとTSMCのN7比でロジック密度を8割、速度を2割増やせるとする。
これをそのまま利用すると、23×1.8×1.2=49.68TFlopsになるが、ここまで上がることはないだろう。1割のマージンを見込んで44TFlopsくらいにすると、4枚で176TFlops。CPUの方は、MilanベースのEPYCがFP64だと4TFlops弱がピークで、これがGenoaになって5TFlops弱程度だとすると、合計で180TFlopsほど。なんとか100キャビネットで1.5 EFlopsを達成する可能性が見えてきた格好だ。
実はこの数字、一応の根拠がある。今年6月に開催されたISC High Performance 2021の基調講演の中でインディアナ大のThomas Sterling教授が示したのが下の画像だ。

冷却回りが結構馬鹿にならないわけで、例えばRadeon Instinctの消費電力をモジュールあたり350W程度まで落とせれば、CPU+GPUは14.4MWほどになり、冷却に10MWほど費やしてもつじつまが合う計算になる
104ラックで1.5 EFlopsを達成見込みとしている。実際にはTOR(Top of Rack:キャビネットの一番上のスペース)にはSlingShotのスイッチが入るであろうし、ストレージなどに割く分もあるだろうから、平均して1つのキャビネットに35~36枚程度が収まれば御の字だろう。すると104キャビネットで7500ノード程度だろうか。ノードあたり200TFlopsくらいが欲しいところで、その意味では第2世代CDNAはかなりアグレッシブな構成になる(モジュール1枚あたり50TFlopsほどになる)計算だ。
もっともこの数字、米エネルギー省が2020年11月に出した資料とつじつまが合わない。こちらだと9000ノード以上とされているが、仮に9000ノードを104キャビネットで割ると、キャビネットあたり86ノード以上になるからだ。
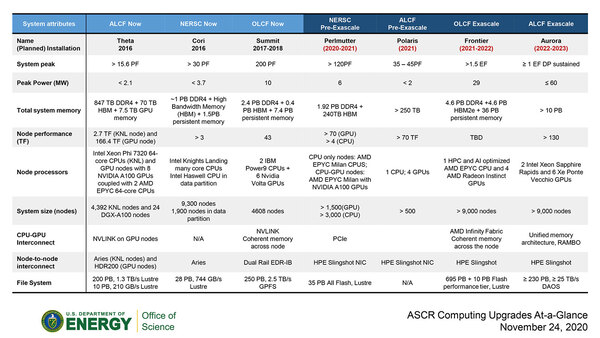
米エネルギー省が2020年11月に出した資料。この時点では、まだPolarisの構成は定まっておらず、インテルとAMDで受注合戦を繰り広げていた
つまり43枚以上のラックモジュールを突っ込んでいる計算になるのだが、ということは実は42Uのラックではなく、50Uのラックということだろうか? ちなみに9000ノードで計算すると、ノードあたり167TFlops程度の性能があればよく、Radeon Instinctのモジュール1つあたり40TFlops強の性能があれば足りることになる。
ちなみに米エネルギー省(DoE)の資料を見ると、システム全体で29MWと推定していることだ。9000ノードを前提に話をする。仮にCPU+メモリー+その他もろもろで200W、Radeon Instinctのモジュール1枚を500Wと仮定すると、ノードあたり2.2KW、9000ノードで19.8MWほどになる。これに冷却機構やSlingshotのスイッチやらなにやらとストレージ類を込みにすると、29MWはかなりギリギリという結果である。
あるいはCDNA 2のモジュールはモノリシックなダイ×2ではなく、EPYC同様に複数(4~8チップ)のダイを集積した構成になっており、CUの数を大幅に増やし、その一方で動作周波数を低めに抑えて消費電力を下げる工夫をしている可能性もありそうだ。
逆に上の画像で言えば、インテルが納入予定のAuroraが、システム全体で60MWという数字を出しているのも壮絶である。やや古い話だが、もともと2013年にDoE Exascale Initiativeが始まった時の目標は、1 Exaflopsを20MW以内で実現という話であった。
Frontierは1.5 Exaflops/29MWなので、この当初目標を比率的にはクリアしていることになる。対してAuroraは1 Exaflops/60MWで、このあたりをどう判断するものか。それもあってか、Thomas Sterling教授が示した2つ上の画像では性能に“≧1 EF DP sustained”(実効性能で倍精度で1 Exaflopsを実現)と注記がされているあたり、なんとかしてFrontierとの差別化を図らないと「米エネルギー省の」面子が潰れかねないと苦心している様がうかがえる。Frontierの実効性能がどの程度になるかが楽しみである。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























