仮想マシン単体のSLAから、高可用性、災害復旧(DR)構成やバックアップの要点まで
Azureで実現する高可用性の“勘どころ”と構築のポイント
2022年01月03日 11時00分更新


Azureの各種サービスを組み合わせてシステム構築やシステム移行をしたいが、クラウドのメリットを生かした方法、あるいはクラウドならではの注意点といったものはあるのだろうか。
本連載では、Azureシステムの設計や構築、運用の段階で知っておくべき考え方(特にオンプレミスとの違い)、関連サービスや機能についてまとめていく。第1回は「システムの高可用性」についてのポイントだ。
●第1章:まずはAzureの基本をおさらいしよう
-コンピュート(仮想マシン)の可用性
-ディスク(ブロックストレージ)の可用性と注意点
-ネットワーク接続の可用性
●第2章:高可用性と災害復旧のベストプラクティスを学ぼう
-高可用性:仮想マシンの冗長化(可用性セット、可用性ゾーン)
-可用性セット:障害ドメインと更新ドメイン
-可用性セットとロードバランサー
-災害復旧:Azure間でのAzure Site Recovery(ASR)
-「Azure Backup」によるバックアップと復元
-システム規模に合わせた高可用性と災害復旧の考え方
-まとめ:高可用性構成と災害復旧構成、それぞれのポイント
-Azure NetApp Files(ANF)の活用
第1章:まずはAzureの基本をおさらいしよう
ここ数年で企業におけるデジタルトランスフォーメーション(DX)が加速したことを背景に、そのシステム基盤としてIaaS型、PaaS型のクラウドサービスの採用が増加している。その有力な選択肢のひとつが「Microsoft Azure」(以下、Azureと略)だ。
ただしその一方で、DXを通じてビジネスがデジタル化することにより、システムの可用性に対する要求はより厳しいものになっている。ダウンタイムが発生すれば、ビジネス上の損失に直結するからだ。こうした現状から、Azureにおける高可用性システムの構築・運用方法に関する関心も高まっている。
Azureのベストプラクティスを紹介していく本連載の第1回では、Azure上で高可用性を実現するための“勘どころ”と“構築のポイント”について解説していく。まずは、Azureで高可用性を担保したアーキテクチャーを設計していくうえで最低限理解しておかなければいけない、Azureの基本的なテクノロジーついておさらいしていきたい。
コンピュート(仮想マシン)の可用性
Azureで高可用性を担保したアーキテクチャーを設計していくうえでは、まず仮想マシン(Azure VM)に対する理解が重要となる。ポイントは以下の3つだ。
①豊富なラインナップからワークロードの要求にあった仮想マシンを選択する:
Azureではさまざまなサイズ(スペック)の仮想マシンがラインナップされているが、稼働させるワークロードの負荷に耐えられないような低スペックのものを選んでしまうと、可用性のダウンにつながる。

現時点の仮想マシン(Azure VM)ラインナップ。低コストで開発/テスト環境向けのAシリーズ(Av2)から最大416vCPU/12TBメモリを備えるMv2シリーズまで、さまざまなサイズの仮想マシンがそろう
②「ACU」を理解してコストパフォーマンスの良い仮想マシンを選定する
可用性を高めようと高スペックの仮想マシンを選択すると、今後はコストが上がってしまう。仮想マシンのコンピュート能力を比較する指標として「Azure Compute Unit(ACU)」という数値が用意されているので、これを参照しながら可用性とコストのバランスを取ることが重要だ。

仮想マシン各サイズのACUによる比較。Aシリーズ(Av2)を基準の「100」として、各サイズのコンピュート能力を数値で示している
③パフォーマンス状況を監視しながら、スケールアップ/スケールアウトを行う
システムを運用していくうちに負荷が高まってくることもある。短時間で仮想マシンのスケールアップ/スケールアウトができるクラウドのメリットを生かし、必要に応じてコンピュートリソースの量を調整することで、仮想マシン単体での可用性が担保できる。
ディスク(ブロックストレージ)の可用性と注意点
仮想マシンにアタッチするディスク(ブロックストレージ)についても、可用性の観点からおさらいしておこう。
ディスクの可用性を考えるうえで重要なのが「管理ディスク(Managed Disk)」の存在だ。この管理ディスクには、IOPSやレイテンシ、コストが異なる4種類がラインアップされている。詳しくは第2章で説明するが、このうちのPremium SSDを使うことがAzureの仮想マシンでSLAが保証される前提条件となる。
現在では、仮想マシンを作成するとデフォルトでこの管理ディスクを使うことになる。古いシステムとの互換性維持のために非管理ディスク(unManaged Disk)の選択肢も残されているが、それを使うメリットはない。新規に仮想マシンを作成する場合は、必ず管理ディスクを選択すべきだ。
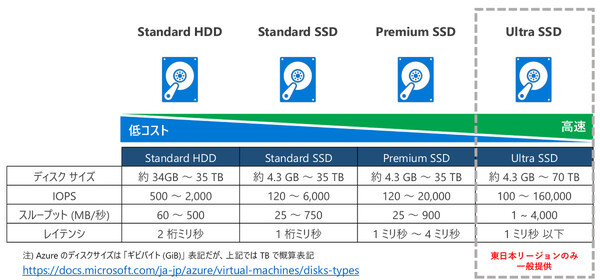
仮想マシンのディスク(管理ディスク)ラインアップ(2022年1月現在)
また、最近では大規模でミッションクリティカルなシステムにおいて、NetAppの高速ストレージをAzureのサービスとして利用できる「Azure NetApp Files(ANF)」を採用するユーザーが増えている。これも可用性の向上につながる機能を持つ。詳しくは第2章で解説する。
ディスクの可用性という観点で、もうひとつ覚えておいていただきたいのが「一時ディスク」だ。次の図を見てほしい。

仮想マシンとディスクの関係(配置)
Azureの仮想マシンは「Azureクラスター」と呼ばれるラック(サーバー群)の中で稼働している。一方で、仮想マシンにアタッチされるディスクのうち、OSディスクやデータディスクの実体はAzureクラスターの“外”(別のラック、Azureストレージ)にある。このドライブを、仮想マシンがネットワーク越しにマウントしているイメージだ。
仮想マシンとドライブの実体が切り離されていることで、構成が柔軟になる。たとえば利用中の仮想マシンをスケールアップしたい場合や、クラスターに物理障害が発生した場合などには、仮想マシンを別のクラスターに移動させることがあるが、このとき、元のクラスターとストレージのリンクをいったん切断して、新しいクラスターへリンクを張り直す。これにより、ディスクの中身(データ)を保持したままで新しい仮想マシンを利用できる。
ただし、ディスクの中でひとつだけ例外となるのが「一時ディスク」だ(上図のDドライブ)。AzureではOSのキャッシュ領域として使われており、より高速なアクセスを提供するために、仮想マシンと同じクラスター内から提供されている。そのため、ほかのディスクのように別クラスターの仮想マシンにリンクし直すことはできない。つまり「一時ディスクはクラスターにある=クラスターの障害時にはデータが消える」。
この点をよく理解して、一時ディスクは障害発生時に消えてもかまわないデータだけを書き込むようにしてほしい。具体的に言えば、SQL Serverのtempdb(一時領域)などがそれに該当する。
ネットワーク接続の可用性
第1章の最後に、ネットワークについても見ておこう。
システムの可用性を高めるために、Azureでは「Azure Traffic Manager」「Azure Application Gateway」「Azure Load Balancer」といった負荷分散サービスがよく利用される。複数の仮想マシンや複数のリージョンでシステムを冗長化し、いずれかのシステム系統で障害が発生した場合はほかのシステムにトラフィックを誘導してサービス停止を防ぐ。これはごく一般的な考え方であり、読者の皆さんもすぐに思いつくだろう。
その一方で忘れがちなのが、オンプレミス環境からAzureの内部環境へ接続するネットワークの可用性だ。まず、オンプレミスなど外部からAzureへの接続方法には、次の図にある3種類が用意されている。

外部からAzureの内部ネットワークに接続する3つの方法
上の表で「接続の回復性」に注目してほしい。これは、それぞれの接続形態におけるVPNゲートウェイ、ExpressRouteゲートウェイの運用モードを示している。これらは外部からAzure仮想ネットワーク(VNet)への“接続口”となるサービスだ。
「アクティブ-スタンバイ」モードの場合、1つのパブリックIPを使用して、アクティブなゲートウェイがダウンした場合に自動でスタンバイゲートウェイに切り替わる(フェールオーバーする)。一方で「アクティブ-アクティブ」モードの場合は、2つのパブリックIPを使って、2つのゲートウェイに常時アクセスできる。いずれも可用性を担保できる仕組みとなっている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第6回
TECH
Azureの利用コストを最適化するためのベストプラクティス -
第5回
TECH
Azureにおける「IDとアクセス管理」のベストプラクティス -
第4回
TECH
あらゆる観点から考える「データセキュリティ」のベストプラクティス -
第3回
TECH
“ポストクラウド時代”の効率的なインフラ管理方法とは -
第2回
TECH
「失敗あるある」から考える、Azure移行のベストプラクティス - この連載の一覧へ