



内部データパスはTuringの2倍
GeForce RTX 30-Series Tech SessionsでわかったAmpereが超進化した理由
2020年09月05日 06時00分更新

モーションブラー処理もレイトレーシングで高速化
AmpereではRTコアが第2世代に進化し、レイトレーシング性能を大幅に向上しているが、具体的には何が変化したのだろうか?
Turingの時に解説済みだが、RTコアの役割はレイトレーシングの処理において最も計算負荷の高い「光線(レイ)がどのポリゴンに衝突するかの計算」を高速で処理することにある。もう少し細かく言えば、BVH(Bounding Volume Hierarchy)という階層構造を使ってレイが衝突しそうなポリゴンを効率良く絞り込む「バウンディング・ボックス・インターセクション」と、ポリゴンにどう衝突するかを計算する「トライアングル・インターセクション」の2つの処理(これをまとめてBVHトラバーサルと呼ぶ)がRTコアの役目だ。
Ampereの第2世代RTコアでは、トライアングル・インターセクションに手を加えることで、モーションブラーの計算を高速化することが可能になった。動いているポリゴンに対してレイトレーシングのモーションブラーを処理する場合、そのポリゴンが次の瞬間、次の次の瞬間……でレイとどう衝突するか追跡した上で結果を出す必要がある。第2世代RTコアでは、トライアングル・インターセクションの前段でこの処理をハードウェア的に実行できるようになった、というものだ。
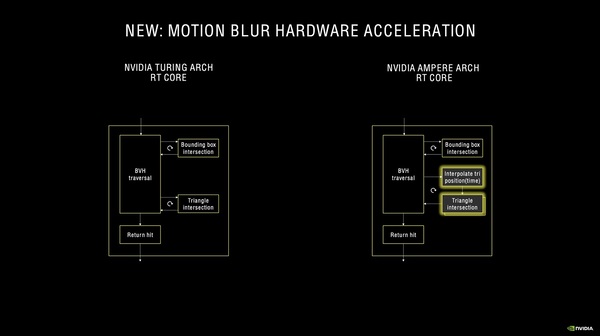
TuringのRTコア(左)とAmpereのRTコア(右)を比べると、後者ではトライアングル・インターセクションの前段にモーションブラーを高速化する機能を設けている
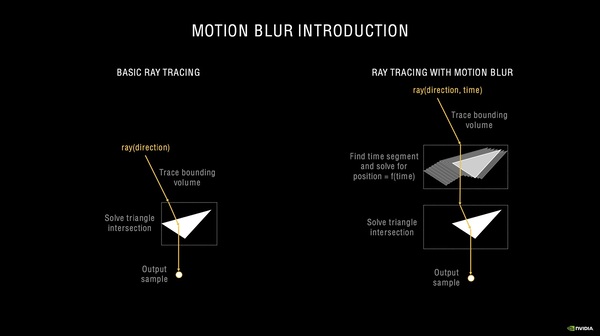
モーションブラーがない場合(左)は、単純にトライアングル(ポリゴン)にどう衝突したかを判定するだけ。対して、モーションブラーをかける場合(右)は、そのトライアングルがどう動いたかを考慮して計算する必要がある
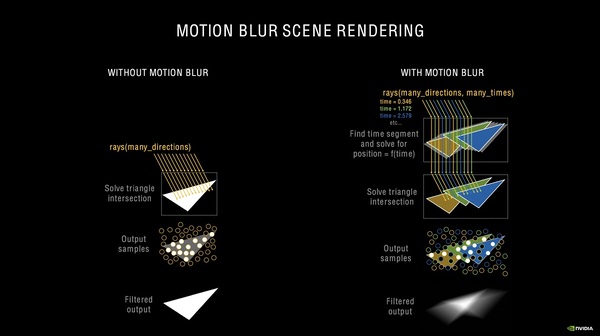
モーションブラーをレイトレーシングで実現する場合(右)でも、レイを放ちトライアングルとの衝突を計算するが、ごく短い時間ごとにもレイを飛ばして計算する。図では黄色・緑・青の3回に亘ってレイを飛ばし、その瞬間のトライアングルとの衝突結果から、モーションブラーを作り出している
ただし、モーションブラーはレイトレーシング処理の有無に関係なく負荷が高いため、ゲームではオフにしてしまうことが多い効果のひとつだ。そのため、レイトレーシングでこれを実装されてもゲーマーにはあまりメリットがなさそうではあるが、CGレンダリング目的なら非常に頼もしい進化点ではある。

第2世代RTコアは前世代に比べて最大8倍のレイの追跡が行なえるようになった。なお、この「最大8倍」とはモーションブラー適用時のことだろう
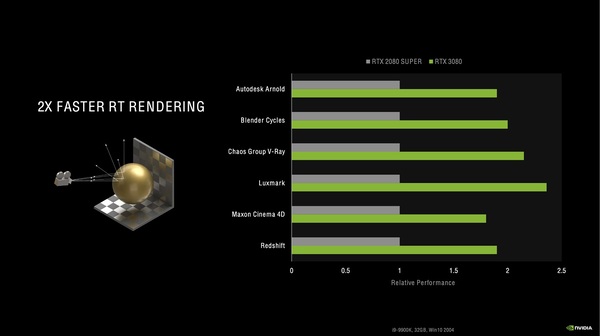
AmpereはTuringからレイトレーシング性能が向上したおかげで、「Arnold」や「Redshift」といった3Dレンダリングソフトのレンダリング速度も概ね2倍に高速化した
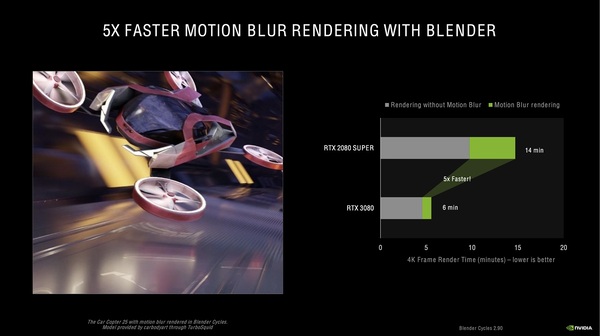
BlenderのCyclesレンダーでは、レイトレーシングのモーションブラー処理時間が劇的に短縮。グラフのグレー部分はモーションブラーを必要としない部分のレンダリング時間で、緑の部分がモーションブラーの処理時間を示している。グレーの部分はざっと2倍だが、緑の部分は5倍高速になった、と主張している
本記事はアフィリエイトプログラムによる収益を得ている場合があります






















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")




















