



AI狙うサイバー攻撃の手法と対策、MBSDとChillStackのセキュリティ/AI専門家6名で共同研究
“AIを守るセキュリティ”専門家がタッグを組み啓蒙やトレーニング
2020年04月03日 08時00分更新

スマートスピーカーやチャットボットから、自動運転車、産業用ロボット、大型施設の制御システムまで――。AI/機械学習/ディープラーニングの技術は、すでに多くの分野で活用され始めており、社会的な期待も高い。他方で、開発者が自分で簡単に実装できるフレームワークやプラットフォームも登場しており、すでにAI技術を組み込んだアプリケーションの開発に取り組んでいる方も少なくないだろう。
AI/機械学習の活用が進むなかで、懸念されるのが「AIに対するサイバー攻撃」だ。現在のところはまだ目立った攻撃事例は観測されていないものの、その技術が社会に浸透していけば、必ずサイバー攻撃は増え、高度化していくだろう。
その動きを見越して、セキュリティ研究者の間ではAI自体の脆弱性に対する研究が始まっており、考えられる攻撃手法や課題、検証ツールなども提案されている。AI市場が確立され、拡大する前のいまこそ、開発や運用のフェーズにうまくセキュリティ対策を組み込み、防衛体制を整える良いチャンスである。
「AI領域で、企業を攻撃者の後手には回らせない」。そんな思いを共にしたメンバーが集まり、“AIを守る”セキュリティ技術についての共同研究が始まっている。攻撃手法と対策の検証や体系化のほか、ホワイトペーパー発行や講演を通じた啓蒙活動、さらには開発者やデータサイエンティスト向けのハンズオントレーニングもスタートする。
AI/機械学習が抱えるセキュリティリスクや実際の攻撃手法、そして共同研究の内容などについて、三井物産セキュアディレクション(以下、MBSD)の米山俊嗣氏と高江洲勲氏、AIセキュリティ分野のスタートアップであるChillStackの伊東道明氏に話を聞いた。

(左から)三井物産セキュアディレクション(MBSD) テクニカルサービス事業本部 プロフェッショナルサービス事業部 先端技術セキュリティセンター セキュリティエンジニアの高江洲勲氏、ChillStack 代表取締役/CEOの伊東道明氏、MBSD テクニカルサービス事業本部 プロフェッショナルサービス事業部 先端技術セキュリティセンター センター長の米山俊嗣氏
「日本のAI業界にセキュリティの文化を根付かせること」が目標
この共同研究は現在、MBSDの3名とChillStackの3名をメンバーとして進められている。
MBSDの米山氏は、これまでに47件の脆弱性報告(CVE取得)実績を誇るバグハンターだ。高江洲氏は、脆弱性診断へのAI適用を目指した研究と実装に取り組み、Black Hat USAで自作ツールを発表した経験も持つ。廣田一貴氏は、セキュリティ・キャンプで講師を務め、セキュリティ関連の書籍も執筆している。

MBSD 米山俊嗣氏

MBSD 高江洲勲氏
一方でChillStackからは、学生時代からAI、セキュリティの両分野について研究し、国際学会で最優秀論文賞を受賞するなど実績を積み重ねてきた伊東氏のほか、CTFチーム「TokyoWesterns」リーダーで攻防の視点からセキュリティ領域を極めるテクニカルアドバイザーの市川遼氏、AI畑を突き進み「DeNAデータ解析コンペティション」の優勝経験も持つデータサイエンティストの長澤駿太氏が参加している。

ChillStack 伊東道明氏
高江洲氏によると、各メンバーとはこれまでセキュリティのイベントなどで顔を合わせるたびに「AIセキュリティ分野で何かやりたい」と話していたという。「セキュリティとAIの両分野で強い人が初期メンバーに揃ったと自負している」と述べ、今後は活動を通じて仲間を増やしつつ、「日本のAI業界にセキュリティの文化を根付かせること」を将来的な目標に掲げる。
今回の共同研究では、既知および新規の攻撃手法に関する論文などを検証し、その情報を体系的に理解できるよう整理して提供するなど、「情報共有」に力を入れていく方針だ。米山氏は、論文は英語で書かれたものが大半なので、日本語で情報を整理し、提供することには意義があると語る。
また、機械学習エンジニアやデータサイエンティスト、ソフトウェアエンジニアなどを対象とした「セキュアAI開発トレーニング」の申し込み受付も4月2日からスタートした。このハンズオントレーニングは2日間/三部構成の集中コースで、“AIを意図的にだます”“AIを乗っ取る”“AIシステムに侵入する”攻撃手法とその対策を学ぶことができる。このコースは、すでにAI/機械学習を活用していてコーディング経験もある中上級者向けだが、将来的には初級者向けコースや、さらに上級者向けのコースも検討していくという。

中上級者向けのハンズオン「セキュアAI開発トレーニング」を提供開始する(https://jpsec.ai)
データの準備段階での攻撃「学習データの汚染」とは
では、AI/機械学習にはどのようなセキュリティリスクが存在するのだろうか。AIの開発工程を「設計」「データの準備」「モデル開発」「運用」の4フェーズに分類したとき、特に注意が必要なのは「データの準備」と「運用」のフェーズだという。
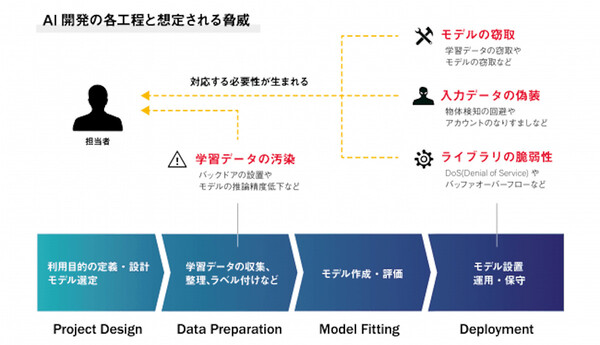
AIの開発フェーズと、そこに潜在する脅威の代表例(公式Webサイトより)
まずデータの準備フェーズで考えられる脅威は、AIのトレーニングに使う学習データの「汚染」だ。
「最近はAI/機械学習のフレームワークやプラットフォームが充実しており、それを利用すれば、数学的知識がなくてもAI/機械学習を活用できる。ただし、AIをトレーニングするための学習データはユーザー側で用意しなければならない。そして、ユーザー自身で収集したデータに悪意あるデータが混在していた場合、意図しない結果が導かれてしまう可能性が出てくる」(米山氏)
たとえば、正常なデータセットを装ったものの中に細工した(不正な)データを紛れ込ませ、それを学習したAIに判断を誤らせるという攻撃の手口が考えられる。通常、AIのトレーニングには大量のデータが使われるため、そうしたデータが一部に紛れ込んでいてもなかなか気づきにくい。
実際、インターネット上にはAIのトレーニング用としてさまざまなデータが公開されているが(そして大半は善意に基づき公開されているものだが)、中には汚染されたデータが混在している可能性も十分にある。
また、収集したデータを分類/ラベル付けして学習データを作成する際にも、リスクが作り込まれる可能性があると高江洲氏は指摘する。
「ある人に聞いた話だが、データセットの作成作業を外注して仕上がりをチェックしたところ、ナイフの画像が『ペン』とラベル付けされているミスが見つかったそうだ。これは単なる作業ミスかもしれないが、ラベル付け作業を請け負う業者は世界中にたくさん存在し、中には悪意を持って“間違ったラベル付け”をする業者が存在してもおかしくない」(高江洲氏)
データ汚染への対策はデータの性質やモデルにより異なるが、たとえばラベル付け後に人間がチェックするための効率的な手法もあるという。
「データ品質を向上させる方法として、まず教師なし学習の手法で画像をクラスタリング、つまり『似ている画像』にざっくり分類し、それをラベル付けしてチェックするというものがある。人間が数百万枚もの画像をクレンジングしてからラベル付けするのは現実的ではないが、1000枚くらいまで絞り込まれていれば、徹夜してでもなんとかチェックを頑張ろうという気になれる(笑)」(伊東氏)
運用段階での攻撃「モデルの窃取」「入力データの偽装」など
もうひとつが、AI技術を組み込んだシステムの運用フェーズにおける脅威だ。想定される脅威は、大きく3つあるという。
1つは「モデルの窃取」だ。AIシステムに何らかの入力値を渡すと、判定結果が出力されるが、この予測や判断をするためのロジックをモデルと呼ぶ。どのようなモデルを使っているのか、そこで何が判定基準になっているのかが攻撃者にわかってしまえば、そのロジックを“狂わせる”攻撃手法が編み出される可能性がある。
そして、モデルが組み込まれたAIシステムで入出力を何度か観察すれば、そうしたことはある程度見えてくるのだという。

「これは、パスワードに対するブルートフォース攻撃(総当たり攻撃)のようなイメージだ。何度も入力を繰り返して出力を検証すれば、データ分類の基準となる『決定境界』がどこにあるかが見えてくる。最近は少ない回数でモデルを判別する攻撃手法も研究されており、リスクは高い」(米山氏)
2つめは「入力データの偽装」だ。下の例では、女子バレーボール選手の画像データ(顔写真)に細工を加え、AIによる画像分類器を“だます”ことで「写真の人物は高江洲氏」だと誤判定させている。人間が左右の写真を見ても違いはわからない(同じ人物と判断するだろう)が、画像分類器の判断基準は人間と異なる(しかもブラックボックス化している)ため、こうした攻撃が実現するわけだ。

中国の元女子バレーボール選手、郎平(Jenny Lang Ping)氏の顔写真だが、データに細工した右の写真は高江洲氏だと判定されてしまった(MBSDブログ https://www.mbsd.jp/blog/20190311.html より)
入力データの偽装攻撃によって、たとえば物体検知の回避や顔認証のすりぬけ(なりすまし)などが可能になる。さらに、自動運転車を操作するAIをだますような攻撃も研究されている。「一時停止」の標識に(人間には気づきにくい)細工を施して見落とさせたり、街路樹にプロジェクターで道路標識を投影して誤認識させる、といった攻撃手法が有効であることが研究論文で発表されている。
「これを悪用すれば、ライバル会社の自動運転車で事故を多発させて、信頼失墜や株価下落を目論むこともできる」と伊東氏。また、米山氏は別の攻撃ターゲットとして「犯罪組織であれば、入出国ゲートの顔認証を誤魔化したいと思うだろう」と述べ、この攻撃手法が悪用される可能性が高いことを示唆した。
3つめの脅威は「AIフレームワーク」の脆弱性である。TensorFlowやCaffeなどの機械学習フレームワークでは、DoSやバッファオーバーフローの脆弱性が多数報告されている。これについては、通常のソフトウェアセキュリティ対策と同じように、パッチの適用や最新情報の収集などで対応できる。
「今はまだ“おいしい”ターゲットがいないためか、こうした攻撃が顕著化していない。だが、AI活用の敷居がますます下がり、攻撃ツールも出回り始めている現状を考えると、AIを簡単に攻撃できる世界は1、2年も待たずにやってくると思う」。高江洲氏は、AIを狙った攻撃が活発化する前に、どのようなリスクが存在し、どのような対策を講じることができるのかを検討、展開しておくことが大切だと強調する。
“AIを守るセキュリティ”は国内ではまだ新しい領域であり、伊東氏は「開拓している感じがあって楽しい」と笑う。高江洲氏も、AI固有の開発工程や脆弱性発生のポイントがあり、難しいながらも手ごたえがあって新鮮だとうなずく。
WebアプリケーションフレームワークにXSSやSQLインジェクション対策が実装されているように、いずれはAI領域でも開発者が意識せずに対策できるフレームワークが提供されるべきだと米山氏。「そこも含めて共同研究で議論しながら、成果を出していきたい」。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



