

本記事はFIXERが提供する「cloud.config Tech Blog」に掲載された「BERT(Keras BERT)を使用した文章分類を学習から予測まで紹介!」を再編集したものです。
概要
絶賛フロントエンド勉強中の井上です。今回は自然言語処理界隈で有名なBERTを用いた文書分類(カテゴリー分類)について学習(ファインチューニング)から予測までを紹介したいと思います。本記事では実装ベースでお話しするので、「そもそもBERTって何?」という方は検索するか、参考URLを載せておくのでそこから飛んでいただけると助かります。
目次
・事前準備
・学習
・評価
・予測
・参考文献
事前準備
Google Colaboratory
学習は膨大な計算量が必要なので、Google Colaboratoryを使用します。
https://colab.research.google.com/notebooks/welcome.ipynb?hl=ja
・無料でTPU(Tensor Processing Unit)が使えるのでお得!
googleさんありがとうございます
TPUはIntelのHaswellとNVIDIAのK80と比較すると、性能は15~30倍
・DeepLearningに必要なライブラリはあらかじめインストールしてあります。
※ インストールされていないライブラリなどもあるので、それらは随時インストールしなければいけません。
TensorFlowでGPU使えるようになっている人(Cuda環境とか構築済みの人)は自分のPCでやってもいいと思います。ただ、自分がローカル環境で試したのは予測だけで学習は試していないので分かりません!
事前学習モデル
事前学習モデルを作成するには膨大な時間がかかりますが、SentencePieceとWikipediaを用いて学習したモデルを配布している方がいるので、そのモデルを利用させていただきます。ホームページからGoogle Driveにアクセスしダウンロードしてください。
https://yoheikikuta.github.io/bert-japanese/
必要データ一覧
BERT用のファイル
・model.ckpt-1400000.data-00000-of-00001
・model.ckpt-1400000.meta
・model.ckpt-1400000.index
SentencePiece用のファイル
・wiki-ja.vocab
・wiki-ja.model
学習用データ
学習に用いるtrainデータとtestデータを作成します。train、testどちらもカラム名がfeatureで文章だけのCSV(features.csv)、それに紐づくカラム名がlabelでラベルだけのCSV(labels.csv)を作成してください。作成したデータはtrains,testsフォルダを作成し格納しておいてください。以下に例を示します。
例
ちなみに弓道のリーグ戦は四人一組のグループが交互に引く形である:スポーツ
番号変えたいと思う人間もいるのではないのでしょうか?:携帯電話
<features.csv>
feature
ちなみに弓道のリーグ戦は四人一組のグループが交互に引く形である
番号変えたいと思う人間もいるのではないのでしょうか?
<labels.csv>
label
スポーツ
携帯電話
本記事では簡単に学習・予測を行えるようにしたいので、学習用データは定番のデータセットであるKNBCのデータセットを用います。(自分のデータセットで学習したい人は上記形式のcsvを作成し入れ替えれば可能です!)
・KNBCのデータセット
http://nlp.ist.i.kyoto-u.ac.jp/kuntt/index.php
設定ファイル
BERTの学習に用いる設定ファイルをjson形式で作成します。設定ファイルのパスを指定している箇所を変更すればファイル名はなんでも大丈夫です。
ここで注意しなければいけないことは、max_position_embeddingsとmax_seq_lengthの値を使用する学習データセットの最大トークン数にしなければいけないことです。誤った値を入れていると学習が収束せずに頭の悪いモデルが出来上がります。
最大トークン数を調べるソースコードを載せて置くので、学習を行う前に調べておいてください。
{
"attention_probs_dropout_prob": 0.1,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"max_position_embeddings": 103,
"max_seq_length": 103,
"num_attention_heads": 12,
"num_hidden_layers": 12,
"type_vocab_size": 2,
"vocab_size": 32000
}
最大トークン数を取得するソースを以下に示します。ソースは雑に書いているので、trainデータとtestデータ両方で実行し、大きい方の値を設定ファイルに記述してください。
import pandas as pd
import sentencepiece as spm
# feature.csvは上記で用意したファイルのパスを指定してください
train_features_df = pd.read_csv('features.csv')
def _get_indice(feature):
tokens = []
tokens.append('[CLS]')
tokens.extend(sp.encode_as_pieces(feature))
tokens.append('[SEP]')
number = len(tokens)
return number
sp = spm.SentencePieceProcessor()
# ダウンロードした事前学習モデルのパスを指定してください
sp.Load('wiki-ja.model')
numbers = []
for feature in train_features_df['feature']:
features_number = _get_indice(feature)
numbers.append(features_number)
# 最大トークン数
max_token_num = max(numbers)
print("max_token_number: " + str(max_token_num))
フォルダ構成
各自、好きなように構成して頂いて構いませんが、今回は以下のような構成で行います。

学習
GoogleColaboratoryを使用するため、出力データや事前準備で用意したデータはGoogleDriveに保存する必要があります(上記のフォルダ構成でdriveに保存)。
また、GoogleColaboratoryはnotebook形式なので、以降に記載するソースコードはまとめて実行するのではなく、逐次実行する形式を想定しています。
GoogleDriveのマウント
以下のソースを使用し、GoogleDriveをマウントすることでドライブへの読み書きが可能になります。
from google.colab import drive
drive.mount('/content/drive')
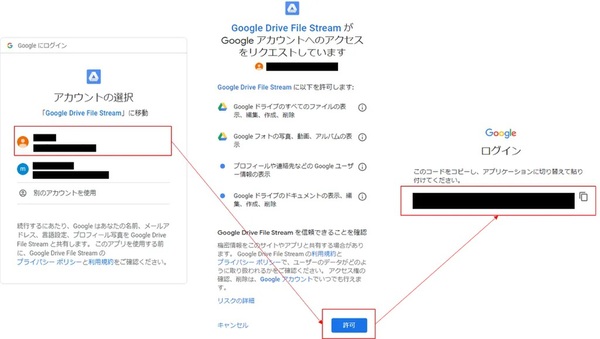
ソースを実行すると以下のような表示になるので、記載されたリンクに飛び、ドライブへのアクセス許可を行います。許可するとコードが表示されるので、そのコードを入力することでドライブマウント完了です。

ライブラリのインストール
標準インストールされているライブラリだけでは足りないので、以下のライブラリをインストールします。
pip install sentencepiece
pip install keras_bert
BERTの設定ファイル、モデルのロード
学習回数と事前に調べていた最大トークン数、ファイルパスを自分用に書き換えてください。以下に書き換える箇所を示します。
・config_path:設定ファイルのパス
・checkpoint_path:事前学習モデルのファイルパス
◦拡張子まで書かないでください
・SEQ_LEN:最大トークン数
・EPOCH:学習回数
import sys
sys.path.append('modules')
from keras_bert import load_trained_model_from_checkpoint
# BERTのロード
config_path = '/content/drive/My Drive/bert/bert-wiki-ja/bert_finetuning_config_v1.json'
# 拡張子まで記載しない
checkpoint_path = '/content/drive/My Drive/bert/bert-wiki-ja/model.ckpt-1400000'
# 最大のトークン数
SEQ_LEN = 103
BATCH_SIZE = 16
BERT_DIM = 768
LR = 1e-4
# 学習回数
EPOCH = 20
bert = load_trained_model_from_checkpoint(config_path, checkpoint_path, training=True, trainable=True, seq_len=SEQ_LEN)
bert.summary()
学習データのロード関数
こちらの関数でもモデルの読み込みを行うので、各自ファイルパスの変更をお願いします。
・sp.load("ファイルパス")
文章のベクトル化
_get_indice関数では、SentencePieceとwikipediaモデルを使用し文章のベクトル化を行っています。
学習データ読込
_load_labeldata関数は学習データを読込、_get_indice関数を用いて特徴量を抽出しています。
sp = spm.SentencePieceProcessor()
sp.Load('/content/drive/My Drive/bert/bert-wiki-ja/wiki-ja.model')
def _get_indice(feature):
indices = np.zeros((maxlen), dtype = np.int32)
tokens = []
tokens.append('[CLS]')
tokens.extend(sp.encode_as_pieces(feature))
tokens.append('[SEP]')
for t, token in enumerate(tokens):
if t >= maxlen:
break
try:
indices[t] = sp.piece_to_id(token)
except:
logging.warn(f'{token} is unknown.')
indices[t] = sp.piece_to_id('<unk>')
return indices
def _load_labeldata(train_dir, test_dir):
train_features_df = pd.read_csv(f'{train_dir}/features.csv')
train_labels_df = pd.read_csv(f'{train_dir}/labels.csv')
test_features_df = pd.read_csv(f'{test_dir}/features.csv')
test_labels_df = pd.read_csv(f'{test_dir}/labels.csv')
label2index = {k: i for i, k in enumerate(train_labels_df['label'].unique())}
index2label = {i: k for i, k in enumerate(train_labels_df['label'].unique())}
class_count = len(label2index)
train_labels = utils.np_utils.to_categorical([label2index[label] for label in train_labels_df['label']], num_classes=class_count)
test_label_indices = [label2index[label] for label in test_labels_df['label']]
test_labels = utils.np_utils.to_categorical(test_label_indices, num_classes=class_count)
train_features = []
test_features = []
for feature in train_features_df['feature']:
train_features.append(_get_indice(feature))
train_segments = np.zeros((len(train_features), maxlen), dtype = np.float32)
for feature in test_features_df['feature']:
test_features.append(_get_indice(feature))
test_segments = np.zeros((len(test_features), maxlen), dtype = np.float32)
print(f'Trainデータ数: {len(train_features_df)}, Testデータ数: {len(test_features_df)}, ラベル数: {class_count}')
return {
'class_count': class_count,
'label2index': label2index,
'index2label': index2label,
'train_labels': train_labels,
'test_labels': test_labels,
'test_label_indices': test_label_indices,
'train_features': np.array(train_features),
'train_segments': np.array(train_segments),
'test_features': np.array(test_features),
'test_segments': np.array(test_segments),
'input_len': maxlen
}
モデル作成関数
from keras.layers import Dense, Dropout, LSTM, Bidirectional, Flatten, GlobalMaxPooling1D
from keras_bert.layers import MaskedGlobalMaxPool1D
from keras import Input, Model
from keras_bert import AdamWarmup, calc_train_steps
def _create_model(input_shape, class_count):
decay_steps, warmup_steps = calc_train_steps(
input_shape[0],
batch_size=BATCH_SIZE,
epochs=EPOCH,
)
bert_last = bert.get_layer(name='NSP-Dense').output
x1 = bert_last
output_tensor = Dense(class_count, activation='softmax')(x1)
# Trainableの場合は、Input Masked Layerが3番目の入力なりますが、
# FineTuning時には必要無いので1, 2番目の入力だけ使用します。
# Trainableでなければkeras-bertのModel.inputそのままで問題ありません。
model = Model([bert.input[0], bert.input[1]], output_tensor)
model.compile(loss='categorical_crossentropy',
optimizer=AdamWarmup(decay_steps=decay_steps, warmup_steps=warmup_steps, lr=LR),
#optimizer='nadam',
metrics=['mae', 'mse', 'acc'])
return model
学習データのロードとモデルの準備
事前準備で作成した学習用データと学習後のモデル名および出力先を指定してください。
・trains_dir,tests_dir:学習用データのパス
・model_filename:学習後のモデル名、出力先のパス
# データロードとモデルの準備
from keras.callbacks import EarlyStopping, ModelCheckpoint, TensorBoard
trains_dir = '/content/drive/My Drive/bert/data/trains'
tests_dir = '/content/drive/My Drive/bert/data/tests'
data = _load_labeldata(trains_dir, tests_dir)
model_filename = '/content/drive/My Drive/bert/models/knbc_finetuning.model'
model = _create_model(data['train_features'].shape, data['class_count'])
model.summary()
学習の実行
いよいよ学習の実行です。以下のプログラムを実行した際に画像のような出力が出ると思います。(tensorflowのバージョンでWarningが出ますが問題ありません)あとはお茶でも飲みながら学習経過を観察してみましょう!
history = model.fit([data['train_features'], data['train_segments']],
data['train_labels'],
epochs = EPOCH,
batch_size = BATCH_SIZE,
validation_data=([data['test_features'], data['test_segments']], data['test_labels']),
shuffle=False,
verbose = 1,
callbacks = [
ModelCheckpoint(monitor='val_acc', mode='max', filepath=model_filename, save_best_only=True)
])

評価および予測
評価の出力
学習経過
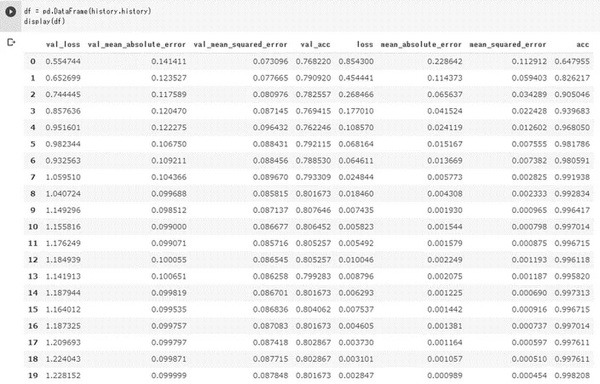
学習回数毎の精度を算出し、学習経過を見ることが出来ます。
※ 学習を行った後に同じnotebookで実行してください。
df = pd.DataFrame(history.history)
display(df)
モデル評価
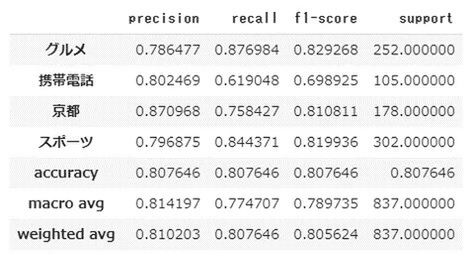
テストデータを用いて学習結果を算出出来ます。ここで用いられている指標については以下のURLを参照してください。
http://tkdmah.hatenablog.com/entry/2014/02/22/193008
from sklearn.metrics import classification_report, confusion_matrix
from keras.models import load_model
from keras_bert import get_custom_objects
model = load_model(model_filename, custom_objects=get_custom_objects())
predicted_test_labels = model.predict([data['test_features'], data['test_segments']]).argmax(axis=1)
numeric_test_labels = np.array(data['test_labels']).argmax(axis=1)
report = classification_report(
numeric_test_labels, predicted_test_labels, target_names=['グルメ', '携帯電話', '京都', 'スポーツ'], output_dict=True)
display(pd.DataFrame(report).T)
予測
いよいよ学習したモデルを用いた予測です。流れとしては入力された文章の特徴量を抽出し、モデルに入力するだけの簡単なお仕事です!ただ注意点もあります。それについては一度下記のソースを実行した後に解説します。
import sys
import pandas as pd
import sentencepiece as spm
import logging
import numpy as np
from keras import utils
from keras.models import load_model
from keras.preprocessing.sequence import pad_sequences
from keras_bert import load_trained_model_from_checkpoint
from keras_bert import get_custom_objects
from sklearn.metrics import classification_report, confusion_matrix
sys.path.append('modules')
# SentencePieceProccerモデルの読込
spp = spm.SentencePieceProcessor()
spp.Load('/content/drive/My Drive/bert/bert-wiki-ja/wiki-ja.model')
# BERTの学習したモデルの読込
model_filename = '/content/drive/My Drive/bert/models/knbc_finetuning.model'
model = load_model(model_filename, custom_objects=get_custom_objects())
SEQ_LEN = 103
maxlen = SEQ_LEN
def _get_indice(feature):
indices = np.zeros((maxlen), dtype=np.int32)
tokens = []
tokens.append('[CLS]')
tokens.extend(spp.encode_as_pieces(feature))
tokens.append('[SEP]')
for t, token in enumerate(tokens):
if t >= maxlen:
break
try:
indices[t] = spp.piece_to_id(token)
except:
logging.warn('unknown')
indices[t] = spp.piece_to_id('<unk>')
return indices
feature = "昨日は携帯電話を買いに行った。"
test_features = []
test_features.append(_get_indice(feature))
test_segments = np.zeros(
(len(test_features), maxlen), dtype=np.float32)
predicted_test_labels = model.predict(
[test_features, test_segments]).argmax(axis=1)
print(predicted_test_labels[0])
</unk>

注意点というのはモデルからの出力がラベル番号であることです。これらの番号はtrainデータの上から順に0から割り振られますが、同じラベルが並んでいた場合は、新しいラベルが出現するまで番号は割り振られないので安心してください。
例
ちなみに弓道のリーグ戦は四人一組のグループが交互に引く形である:スポーツ(ラベル:0)
番号変えたいと思う人間もいるのではないのでしょうか?:携帯電話(ラベル:1)
iPhone11のタピオカメラは高性能だと思う。:携帯電話(ラベル:1)
最近のテレビはAndroidOS搭載が標準化してきている。:家電(ラベル:2)
上記の対策として、突貫作業ではありますが、私はcsvでラベル番号とラベル名の紐づけを行い、ラベル名を出力するようにしています。
新しいフォルダとファイルを作成して以下のプログラムを実行してみてください。
bert/label_id/id_category.csv
id label
0 携帯電話
1 スポーツ
2 グルメ
3 京都
import sys
import pandas as pd
import sentencepiece as spm
import logging
import numpy as np
from keras import utils
from keras.models import load_model
from keras.preprocessing.sequence import pad_sequences
from keras_bert import load_trained_model_from_checkpoint
from keras_bert import get_custom_objects
from sklearn.metrics import classification_report, confusion_matrix
sys.path.append('modules')
# SentencePieceProccerモデルの読込
spp = spm.SentencePieceProcessor()
spp.Load('/content/drive/My Drive/bert/bert-wiki-ja/wiki-ja.model')
# BERTの学習したモデルの読込
model_filename = '/content/drive/My Drive/bert/models/knbc_finetuning.model'
model = load_model(model_filename, custom_objects=get_custom_objects())
SEQ_LEN = 103
maxlen = SEQ_LEN
def _get_indice(feature):
indices = np.zeros((maxlen), dtype=np.int32)
tokens = []
tokens.append('[CLS]')
tokens.extend(spp.encode_as_pieces(feature))
tokens.append('[SEP]')
for t, token in enumerate(tokens):
if t >= maxlen:
break
try:
indices[t] = spp.piece_to_id(token)
except:
logging.warn('unknown')
indices[t] = spp.piece_to_id('<unk>')
return indices
feature = "昨日は携帯電話を買いに行った。"
test_features = []
test_features.append(_get_indice(feature))
test_segments = np.zeros(
(len(test_features), maxlen), dtype=np.float32)
predicted_test_labels = model.predict(
[test_features, test_segments]).argmax(axis=1)
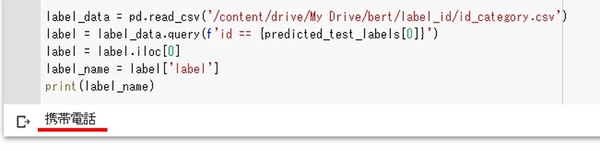
label_data = pd.read_csv('/content/drive/My Drive/bert/label_id/id_category.csv')
label = label_data.query(f'id == {predicted_test_labels[0]}')
label = label.iloc[0]
label_name = label['label']
print(label_name)
</unk>
長くなりましたが、以上でBERTの学習から予測までの紹介終了です!
お疲れさまでした!
最後に
学習から予測まで実装が簡単になっているのでぜひ試してみてください。
自分が学習不足なだけですが、最終出力でどれくらいの割合でそのラベルと判断したのかを現状のプログラムでは出せないのでそこは何とかしたい!教えてくれると泣いて喜びます。
つぶやき
自分の実装では予測部分をAPI化して使用中。
ただ、モデルの読込が重いのでglobalを用いてAPI起動時に読み込ませていますが、tensorflowがマルチスレッドで動かない問題が発生してるのでマルチスレッドを使わずにやっています。
どうにかしたい…
参考文献
1.SentencePiece + 日本語WikipediaのBERTモデルをKeras BERTで利用する
2.Googleの自然言語処理AI(BERT)をTPU上で転移学習
3.GoogleColabの使い方
4.BERTによる文書分類
井上 雅都/FIXER
pythonをこよなく愛するおじさん。最近フロントエンドの学習してるけど、9割バックエンドやってますん。
本記事はアフィリエイトプログラムによる収益を得ている場合があります




