




Unicode正規化処理はどうなっているか?
Unicodeは、複数の文字を組みあわせる合字のような機能があるため、文字列を比較するような場合に、必要に応じて文字列を正規化して、正しく判定できるようにする必要がある。
たとえば、アクセント記号付きの欧文文字などには、アクセントなしの文字とは別のコードが割り当ててあるため、比較などで問題になることがある。日本語でも、全角の片仮名、平仮名では、濁点のついた文字があるが、半角片仮名には、濁点のついた文字はなく、濁点なしの文字と濁点をならべて利用する。このような場合に「が」という文字を検索するなら「ガ」や半角の「カ」「゙」も探したい場面がある(探す必要があるかどうかはアプリケーションの判断である)。
また、Unicodeには日本語の全角文字の濁点に相当する文字がある。このため、「ガ」を「カ」+「゛」とすることも可能だ。正規化は、こうした問題を解決するための手法の1つだ。Unicodeでは、必要に応じて正規化を行うことで、文字列判定のために「ガ」と「カ」+「゛」を変換するためのルールが定められている。これをAPIとして実装したのが、.NET Frameworkの文字列オブジェクトの「Normalize」メソッドである。これを使うことで元号の合字、たとえば「㍻」(平成合字)を「平成」に変換することが可能だ。
平成合字には、U+337Bという文字コードが割り当てられている。この文字コードを使って変数に文字を代入してみる。
> $heisei = [char]::ConvertFromUtf32(0x337B)
これを表示させると、平成合字を表示できる。では、$heiseiを正規化してみよう。
$heisei.Normalize("FormKD")
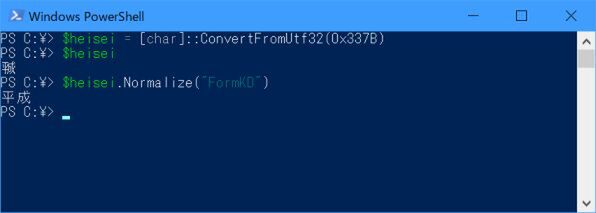
平成合字を表す「U+337B」という文字を$heiseiに設定する。そのまま表示させる合字となるが、正規化を行ったら「平成」の2文字に変換される
FormKDとは、「Normailze Form KD」(正規化形式KD)という正規化の方法を示す定数だ。
正規化形式には4つあり、それぞれ「Form C」「Form D」「Form KC」「Form KD」と呼ばれる。略して「NFC」「NFD」「NFKC」「NFKD」と呼ぶこともある。NFは「Normalization Form」の略である。また、Cは合成(Compositon)、Dは分解(Decomposition)を意味する。
Form KDこと「NFKD」とは「互換等価」(Compatibility Equivalent)というルールで文字列を分解することを示すものだ。このあたりは、かなり面倒なので、細かい説明は省くが、平成合字のように複数の文字の組合せと同じ意味を持つ合字のようなものでも、NFKDで正規化することで通常の文字表現に戻すことができるわけだ。
詳しく知りたいなら「Unicode正規化」でググるか。以下のUnicodeコンソーシアムの資料を見てほしい。
●UNICODE NORMALIZATION FORMS
https://unicode.org/reports/tr15/
この正規化で個々の文字がどのように分解されるのかについては、Unicode側で定義を行っている。情報としては文字1つ1つに対して分解をどうするかの定義がある(もちろん分解できない文字もある)。これは、Unicodeのバージョンに応じて変わる情報であり、.NET Frameworkは、Unicodeの改変に応じてこれを取り込む必要がある。
というわけで、年号の合字に対して「Normalize("FormKD")」メソッドを適用すると、同じ意味の文字に正規化できる。では、「令和」の合字はどうだろうか? 令和合字のフォントパターンは、まだ提供されていないが、すでにコードは割り当てが決定していて、「U+32FF」となっている。$reiwaにU+32FFを代入しても、やはり表示されず、正規化でも「令和」となることはない。前者は、単に令和合字の文字フォントパターンがないだけだが、後者は、令和合字が未定義のままであることを表す。
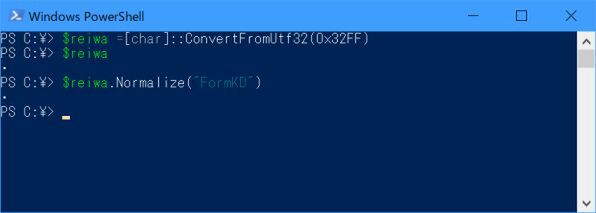
同様に令和合字(U+32FF)を代入してみる。これが表示されないのは、合字のフォントパターンがないからである。さらに正規化しても「令和」にならないのは、.NET Framworkに令和合字の正規化の情報が組み込まれていないからだ
たとえば、Widnows付属の「文字コード」アプリは、「U+32FF」の位置を飛ばして表示する。
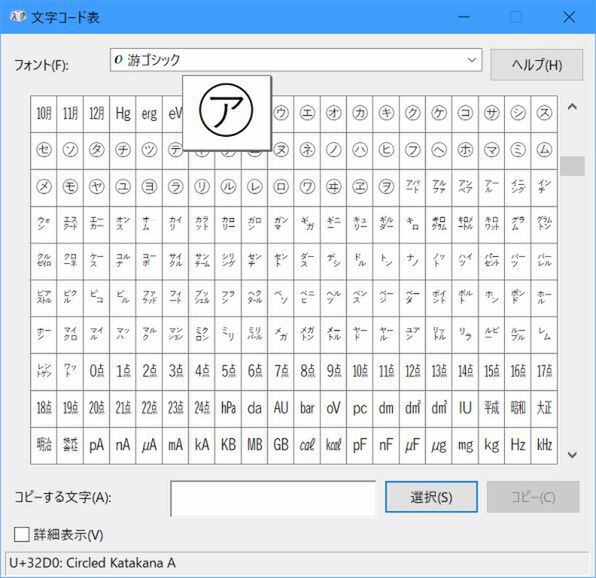
文字コード表アプリでは、令和合字のコードは詰めて表示されてしまっている。丸囲みの「ヲ」と「アパート」合字の間に令和の合字がある
これに対して、MS-IMEのIMEパッドでは、この位置に未定義であることを示す記号を表示するものの、この位置にコードがあることがわかる。つまり未定義の文字に対して、プログラムによって扱いが違う。このような状況で、データとして未定義の文字である令和合字が入ってきた場合、想定外の挙動を示す可能性がある。
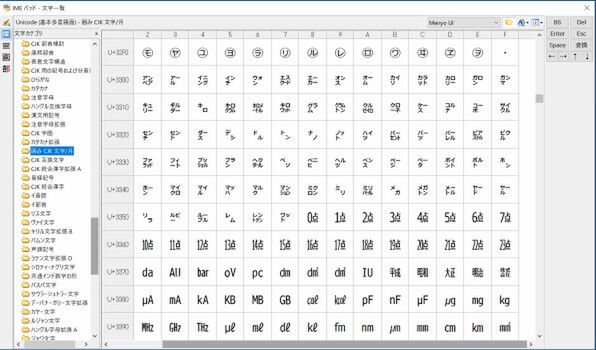
MS-IME付属のIMEパッドでは、最初からU+32FFの位置は空いており、未定義文字を示す記号が表示されている
マイクロソフトは、4月中に提供するアップデートにより「令和」を扱えるようになると主張していることの意味は、この部分にもある。つまり、レジストリを設定しただけでも、「令和」という表記や「元年」といった表示は可能になるものの、令和合字などは、未定義のままであり、それをプログラムで処理した場合には、予想がつかない結果となる可能性があるわけだ。
この連載の記事
-
第428回
PC
Google/Bingで使える検索オプション -
第427回
PC
WindowsのPowerShellのプロファイルを設定する -
第426回
PC
WindowsでAndroidスマホをWebカメラにする機能を試した -
第425回
PC
無料で使えるExcelにWord、Microsoft 365のウェブ版を調べた -
第424回
PC
Windowsの基本機能であるクリップボードについてあらためて整理 -
第423回
PC
PowerShellの今を見る 2つあるPowerShellはどっち使えばいい? -
第422回
PC
Windows 11の目玉機能が早くも終了、Windows Subsystem for Android(WSA)を振り返る -
第421回
PC
進化しているPowerToys LANで接続したマシンでキーボード/マウス共有機能などが追加 -
第420回
PC
Windowsプレビュー版に搭載されたsudoを試す -
第419回
PC
Windows Insider Previewが変わって、今秋登場のWindows 11 Ver.24H2の新機能が見えてきた? -
第418回
PC
Windows 11のスマートフォン連携は新機能が追加されるなど、いまだ進化している - この連載の一覧へ










が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")

















