
7nmのVegaは今年後半に
製品の出荷を開始
本題は7nmのVegaである。会場ではCinema4D R19を使ってのレンダリングデモが行なわれ、きちんと動作することが示されたうえで、すでにこのRadeon Vega 7nmを搭載したRadeon Instinctが顧客向けのサンプル出荷を開始しており、今年後半に製品の出荷を開始することが明らかにされた。

7nm Vegaのパッケージを示すLisa Su CEO
バイクの一部分のレンダリング。向きを変えると一瞬荒い画像になるが、すぐにレンダリングをやり直してこの画面のようになる。その間数秒

Radeon Vega 7nmを搭載したRadeon Instinctは今年後半に製品の出荷を開始。もっとも右下に小さく“Dates subject to change”(スケジュールは変更の可能性があります)とあるのがおかしい
Radeon Instinctだけ? という声が聞こえてきそうだが、少なくとも現時点ではRadeon Instinctだけしかロードマップには載っていないようだ。もっともRadeon Instinctでもビデオ出力はある(でなければ先のレンダリング画面が出てこない)ため、これを使ってゲームをするのは不可能ではないだろうが、あまり現実的ではないだろう。理由は2つある(後述)。
7nmプロセス版Vegaのダイサイズは
720mm2相当
まず先ほどのダイ写真から7nm Vegaのダイサイズを推定してみたい。連載442回でやったように、HBM2のサイズが7.75×11.87mmとわかっており、ここから7nm Vegaのダイサイズはおおむね15.0×23.9mmで358.5mm2と推察できる 小さな画像からの推定なので、±1mm程度の誤差はあることを念のために付け加えておくが、とりあえず丸めて360mm2と仮定する。一方14nm LPPを利用したRadeon RX Vega 64/56のダイサイズは510mm2なので、面積でいえば7割ほどに減った形だ。
ただしGlobalfoundriesの7LPPは、14LPPと比較しておよそ2倍ものトランジスタ密度となる。実はGlobalfoundriesそのものは7LPPについて「ロジック密度は2.8倍になる」と説明しているが、これはスタンダードセルライブラリーを14LPPの7.5トラックから7LPPでは6トラックに変更することも含んでいる。
一方AMDは「我々はFoundry(Globalfoundries)の提供するスタンダードセルライブラリは利用せず、自社開発のスタンダードセルライブラリーを利用する」(Joe Macri氏)としており、事実Ryzen 2でもGlobalfoundriesの12LPP用のライブラリーは利用していない。このため、ダイサイズが初代Ryzenと変わらない。
Vega 7nmについてもやはりAMD自身のスタンダードセルライブラリーを利用している模様で、密度は2倍にしかならない計算だ。つまりVega 7nmのダイは、仮に14LPPで製造したとすれば、720mm2相当のサイズになると考えられる。
いろいろ留保条件はあるにせよ、CU数とダイサイズがほぼ比例するとすれば89.6CU相当になる計算だが、もちろんこんな中途半端なCUはありえないわけで、88CUあたりか、実際はもっとダイサイズが大きくて96CUになると考えられる。
88CUとすれば、動作周波数が同じなら37.5%ほどCU数が多いわけで、これがそのまま性能差につながるわけだが、37.5%という数字はあまり大きなインパクトにはなりえない。
では動作周波数は? というと、同一消費電力なら40%アップというのが、2017年のIEDMにおけるGlobalfoundriesの発表である。
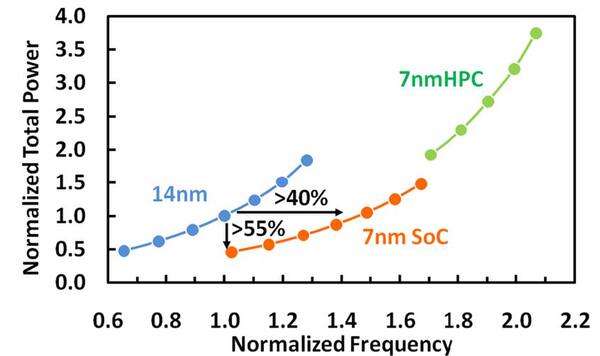
同一周波数なら55%消費電力を落とせるし、同一消費電力ならば40%性能が改善できる
画像の出典は、“A 7nm CMOS Technology Platform for Mobile and High Performance Compute Application”
ただ同一消費電力で40%の性能アップを選んでしまうと、CUの数だけ消費電力があがることになる。そうでなくてもRadeon RX Vega 64の時点でTDPが295Wなうえ、HBMの数も増えているため(容量でいえば8GB→32GBで4倍、チャネル数でいえば2倍)、そのままでは400Wを超えかねない。
となると、動作周波数を若干上げつつ消費電力を落とす、というあたりがベターな選択だろう。下の画像は20%アップのケースで、これだと40%ほどの省電力となる。これならCU増分の分を吸収しつつ、若干の性能アップが可能だ。この場合、トータルの性能改善率は65%ほどになる。
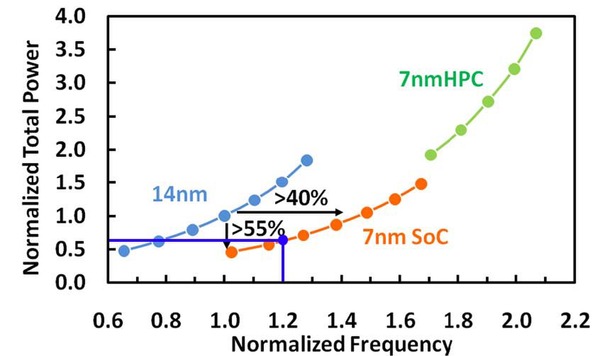
青が20%動作周波数アップの試算(筆者記入)
「もう少しなんとかならないの?」という気もするが、現実問題としてはこのあたりが妥当なバランスポイントと思われる。この場合、7nm Vegaの理論性能は20.9TFlops(Single Precision)となる。
対抗馬であるNVIDIAのTesla V100が同じくSingle Precisionで15.7TFlops(NVLink版)とされるから、なかなか良い数字だ。加えてメモリー帯域も従来のVegaの2倍に広がっており、こと科学技術計算に関していえば従来のVegaよりももっと実効性能が上がるかもしれない。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ












