
次がALU/AGUの実行段である。ここに関してはそれほど意外さはないのだが、最大8 MicroOpのRetirementをサポートしているあたりはかなり強力な印象である。
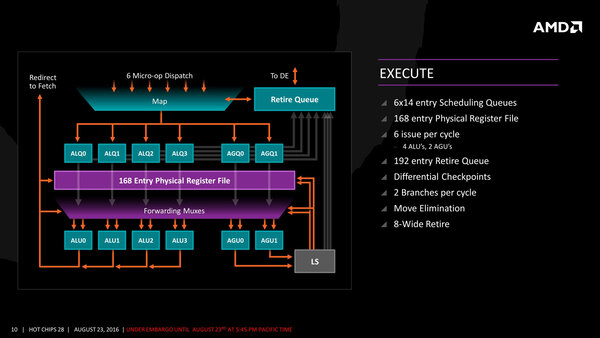
ALU/AGUの実行段。分岐命令に関しても1サイクルあたり2つを同時に処理できるというのもかなり珍しい
またキューの数も192と多く、このあたりはSkylakeと比較しても遜色はない。Load/Storeユニットの構造は下の画像のように一見複雑に見えるが、それほど不思議なものはない。
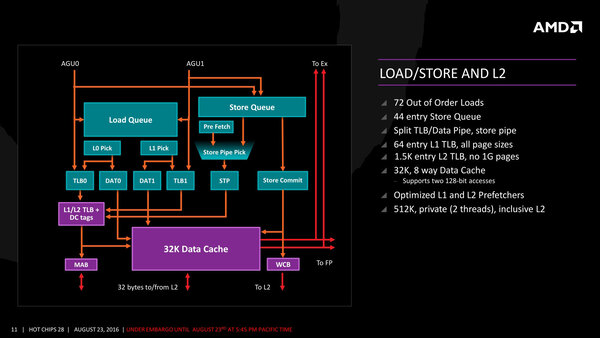
Load/Storeユニットの構造。ちなみにSkylakeのLoad/Store Queueのサイズは72/56となっており、Zenとそう大きく変わらない。Store Unitが実質1つであることを考えると、むしろQueueが深く取れるという言い方もできる
Skylakeに比べるとピーク性能(SkylakeはLoad/Storeユニットを合計4つ搭載)は半減するが、Haswell/Broadwellとは同等で、そもそもSkylakeの4ユニットのLoad/Store Unitは512bit幅のAVX-512命令(Core iグレードでは無効で、Xeonでのみサポート)を前提としたものなので、これをサポートしないZenには無関係であり、逆に言えばAVX-512を除くオペレーションではSkylakeと互角の性能ではないかと思われる。
一方浮動小数点側の実行段では、Micro-OpのDispatchの後、2回のスケジューリングが行なわれることが今回明らかにされている。またこちらも8命令のRetirementがサポートされている。
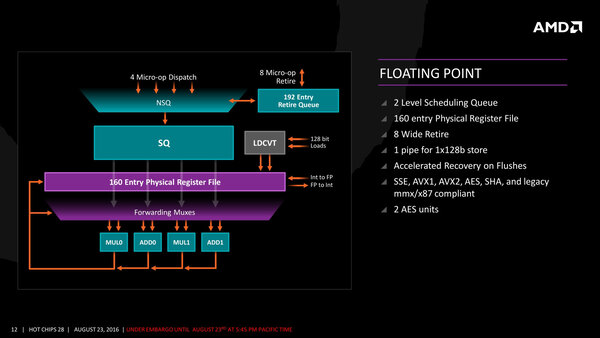
なぜ2段階のスケジューリングが必要だったのか、は今回特に説明されなかった
それと、3次キャッシュに関してだ。連載370回の時点でははっきり記載されていなかったが、今回明確に1次/2次キャッシュはInclusive、3次キャッシュはExclusiveの構造になっていることが示された。
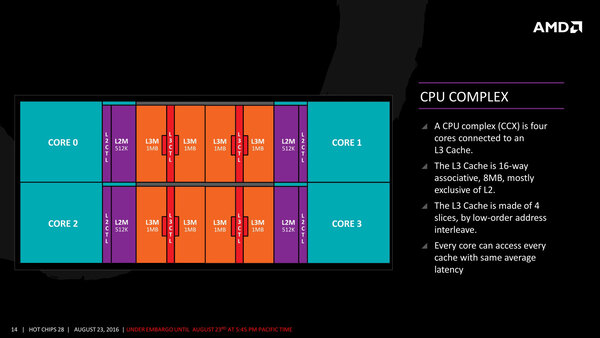
3次キャッシュの構造。将来的には、例えば3次キャッシュを半減させた形でAthlonをリリースすることもありえると思うが、この構成ならそうした対応は容易になる
また4つのコアと1MB×8のブロックを組み合わせて1つのCPU Complexが形成されることも明らかになった。ちなみにこのCPU Complex内はFabricで接続されているそうである。
Summit Ridgeは8コア構成なので、CPU Complexが2つ搭載されている格好だが、このCPU Complex同士はハイパートランスポートではない独自のリンクで接続されるそうだ。
最後に訂正を1つ。連載370回で「おそらくは(不要ブロックの電源供給をもカットする)Power Gatingも複数レベルで実装されているだろう。」と書いたが、説明の中でPower Gatingは現段階では実装されていないことが明らかにされた。
ただこれは、Power Gatingが必要ないほどGlobalFoundriesの14LPPのリーク電流が少ないという話なのか、それともなにかしらの技術的な理由によりPowerGatingが実装できないという話なのか、あるいはその他のなにか理由があるのか、は現時点では不明である。
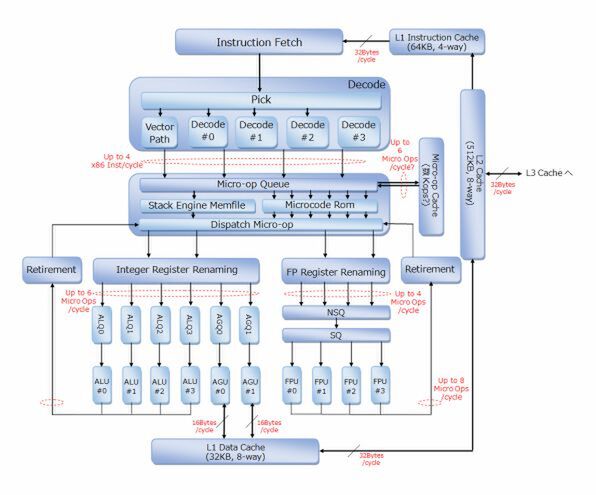
筆者が推定するZenの内部構造図 改訂版
以上の訂正をもとに、図を反映してみた。個人的な見解は、これでZenとK12の切り分けがはっきりしてきたと思う。K12は、マイクロコードRomとその上が全部入れ替えになり、一方でDispatchから下側は完全にZenと同一形態を取るであろう。
x64命令とAArch32/64では当然デコーダーの構造が異なる(特にAArch32をサポートするのが必須なので、この部分の作りこみが結構大変そう)ため、ピックやデコードの構造は当然異なるし、Vector Pathも作り直しだろう。Micro-op Queueも保持するデータの構造が違うと思われる。ただこうした差はマイクロコードRomまでで吸収されるはずで、Dispatchから下は差がないだろう。
実はそう考えると、FPU2がFMA256命令をサポートしない理由もなんとなくわかる。本来のFPUはSSEとNEONの両対応がメインで、そこに互換性を維持するためAVX256を追加した、という感じだからだ。
ARMは今年のHotChipsで、128bit単位で最大2048bitまでの幅を持つSIMDエンジンであるScalable Vector Extensionsという新しいSIMD命令を発表したが、これに対応することは考えていないと思われる。筋論から言えば、AMDはHPC用途にはPolarisやVEGAなどのGPGPUを使いたいところで、K12に長大なSIMDエンジンを搭載することは考えていないだろう。
以上のように、だいぶ強力なコアであることがあらためて確認できたのは非常に喜ばしいことで、年末の発表が待ち遠しいところだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ












