サーバ管理者がネットワーク管理に手を広げるときに便利な「スタンダード・ツールセット」
フルスタックエンジニアへの第一歩を踏み出すためのツール
2016年06月06日 08時00分更新

あらゆるエンジニアがネットワーク管理も身につけておくべき理由
意外なように思えるかもしれないが、昔々(今も一部では?)、大規模なITシステムの運用管理は「縦割り」の世界だった。クライアントPCの担当者はクライアントPCの管理に、サーバの管理者はサーバの面倒に、そしてネットワーク管理者はネットワーク機器のお守りに専念し、双方にまたがる障害が発生したような時には、たとえ社内といえどもチーム間・担当者間の調整が必要だったのだ。
しかしDevOpsの潮流が広がり、インフラからアプリケーションに至るまで幅広い知識を備えた「フルスタックエンジニア」が求められる昨今、「私の担当はサーバの管理だけ」などとは言っていられない。
クラウドサービスが普及してきた現在では、「それほど深く運用管理について知らなくても大丈夫」と思う人がいるかもしれない。
しかし、サードパーティが提供するさまざまなサービスを利用すればするほど、障害が発生したときの原因追及(切り分け)は複雑化する。エンドユーザーから「アプリケーションが利用できなくなった」という問い合わせが来たとき、本当にクラウドサービスの問題なのか、社内ネットワークの問題なのか、あるいはユーザーが利用している端末に原因があるのか、適切に判断を下す重要性はますます高まっている。少なくとも「うちの問題ではない」ことを示せる体制を整えておくことは重要だ。
それでなくても、サーバ本体はもちろん、ストレージやネットワークに至るまで、ITシステムを構成するあらゆるコンポーネントが仮想化され、「Chef」や「Ansible」といった自動化ツールを通して同じように扱える環境が整いつつある。むしろ、サーバ管理者がそれ以外の分野にも手を広げ、スキルアップを図る好機が到来していると言えるのかもしれない。
既存のSNMP対応監視ツール、機能豊富だけれどちょっと重過ぎ?
では、これまで主にサーバの面倒を見ていた技術者がネットワーク管理に手を広げようというときには、どこから始めたらいいだろうか?
サーバ管理の基本を振り返ってみると、まず死活監視に始まる。管理下のサーバが正常に動作しているかを確認するため、定期的に問い合わせを投げ、応答が返ってこない場合は障害と見なし、障害対応の次のフェーズに移行する。前回の記事で紹介したPingによるネットワーク到達性の確認だけでなく、ポート単位、サーバ上で稼働しているサービス単位でチェックを行うことも多い。
中にはcronやwgetといったコマンドを活用し、スクリプトを組んでアプリケーションの動作監視を行っている管理者もいるだろう。また、対象は外部に公開されているサーバに限られるが、サービスとして指定したIPアドレスのサーバ監視を行うものも登場している。
そして何よりこの手の「サーバ監視ツール」(より正確にはネットワークも含めた統合管理ツール)は種類が豊富だ。特に、SNMP(Simple Network Management Protocol)対応の管理ツールとなると、商用製品はもちろん、「Nagios」「Zabbix」「Hinemos」といったオープンソースソフトウェアも多数リリースされている。
そこでこうしたツールを用いて、サーバ監視とネットワーク監視を一元的に行い、機器の死活管理からネットワーク管理の理解を深めてみてはどうだろうか――と言いたいところだが、これらのツールはいずれも機能が豊富で、それだけにやや導入・操作が複雑だ。個人でちょっとずつネットワーク機器の操作に慣れていきたいという段階のインフラ管理者にとっては、やや“重い”ソリューションかもしれない。
手元のPCで手軽にネットワークを監視「スタンダード・ツールセット」
「そこまで本格的な監視を行わなくても、ちょっと状況を把握できるようにしておきたい」、そんなときに試してみたいのが、ソーラーウインズが無償で提供しているネットワーク管理ツール群「スタンダード・ツールセット」だ。ネットワーク監視・管理を手助けする14種類のツールをパッケージ化したものだ。
例えばこの中に含まれている「Watch It!」は、ネットワークに接続されたサーバに加え、ルータをはじめとするネットワーク機器の可用性をICMP経由で監視する。小さな信号機のようなウィンドウをWindows上に表示させておけば、基本的な死活監視を手軽に実現できる。もし、監視対象デバイスから応答が来ないなど、何らかの異常が発生した際には表示が赤色に変わって警告する仕組みで、Telnetなどでデバイスに直接接続し、詳細を調べることになるだろう。
小さな死活監視ツールで便利な「Watch It!」
「IP Network Browser」ではもう少し詳しい情報を収集できる。これは指定したIPアドレスレンジ内を探索し、存在するネットワーク機器やサーバを一覧表示するツールで、ICMPやSNMPで得られるデバイスステータスも収集可能だ。機器の名称やベンダー名はもちろん、例えばシスコ製のルータならばIOSのバージョンや導入されているネットワークカード、ポートの状況、さらにはARPテーブルの情報などを手元で把握可能だ。こうした情報を一元的に目で見ることで、ネットワークの世界への理解を深める糸口になるのではないだろうか。
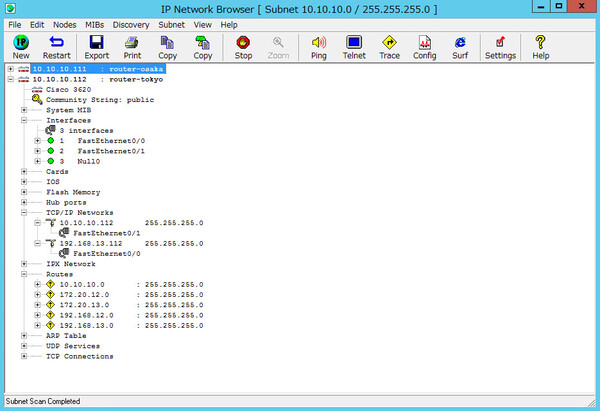
IPアドレスレンジ内のデバイスをスキャンし一覧表示する「IP Network Browser」
他にも、特定のリモートネットワークデバイスで送受信されているデータの帯域幅の統計値を収集し、メーターで表示する「Network Bandwidth Gauge」や、シスコルータが出力するNetFlowデータを受信分析し、トラフィックをアプリケーションごとにグラフ表示する「NetFlow Realtime」といったツールが含まれている。
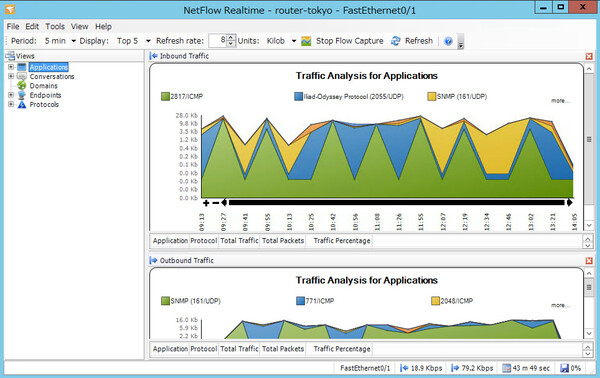
NetFlowデータからトラフィックを可視化「NetFlow Realtime」
スタンダード・ツールセットには、これら一連のツールのワークスペースとして動作し、ツール間の連携動作も可能にする「Workspace Studio」も含まれているため、監視作業の自動化も行える。例えば、あるスイッチのレスポンスタイムが遅くなっていることが発覚したら、そのCPU利用状況や帯域消費状況、メモリなどリソース周りの情報を収集するといった作業を、自分が今使っている端末から実施できる。
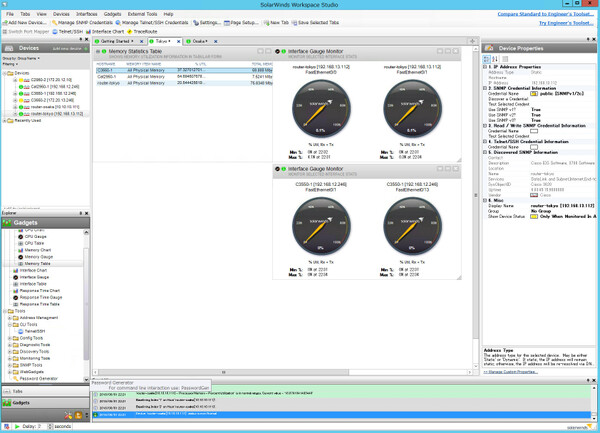
各ツールのワークスペースとして動作する「Workspace Studio」
例えば、企業としてシステム全体を監視するオフィシャルな管理ツールを入れているケースは多いだろうが、それに加えてこうした無償のツールを活用し、特に気になる機器やサーバの様子をアドボックに監視する、といった使い方もあり得るだろう。ツールの動作に必要なCPUやメモリのハードルは非常に低く、古いPCでも動作することもポイントだ。
サーバ管理者がネットワーク管理者と連携し、一体となって安定したインフラを実現していく上でも、こうしたお役立ちツールを使い分けて「平常」を知り、「異常」に備えておきたい。
(提供:ソーラーウインズ)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
")





&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")



















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")


