




4月12日、日本IBMはオールフラッシュストレージ「IBM FlashSystem」を発表した。HDDやソフトウェア処理前提の汎用ストレージと異なり、フラッシュのパフォーマンスを最大限に発揮すべく設計された製品。RAID技術の組み合わせで高い可用性も実現する。
パフォーマンスの常識を覆す新製品
IBM FlashSystemは、1Uラックマウント筐体を採用したオールフラッシュのストレージ。IBMが2012年に買収した米TMS(Taxas Memory Systems)の製品をベースとしており、今回はエントリモデルの「IBM FlashSystem 710/810」、HAモデルの同720/820の全4モデルが投入される。

IBM FlashSystem 710
発表会で登壇した日本IBM システム製品事業 ストレージ事業部 事業部長 波多野敦氏は、1980~2010年の30年間にCPUは年率60%で向上してきたのに対し、ディスク装置は5%向上にとどまり、システムの大きなボトルネックになってきたと説明。このボトルネックを解消するのが新開発のIBM FlashSystem。「パフォーマンスの常識を覆す技術で、今までのストレージ製品の延長ではない。大きなITを左右する大きな発表」(波多野氏)と、意気込みを述べた。

日本IBM システム製品事業 ストレージ事業部 事業部長 波多野 敦氏
波多野氏は、2200万IOPS/ラックのパフォーマンス、100マイクロ秒という応答速度、1PB/ラックという集積率を実現しつつ、耐久性も既存のMLCフラッシュに比べ30倍高いとそのメリットをアピール。IBM FlashSystem 1台をOracle DBのシステムに追加するだけでパフォーマンスが約12倍に拡大した事例や、データベースのライセンスや保守コストが約40%安価になった事例などを紹介した。レイテンシーの低減やパフォーマンスの向上はもちろんのこと、ソフトウェアやサーバーのライセンスコスト削減や、フロアスペースやエネルギー節減にも効果を発揮するわけだ。

IBM FlashSystemの概要
適用エリアも、データベースのトランザクションやビッグデータでの分析・解析用途を中心に、科学演算、メディア、医療など幅広い分野で活用できるとした。今後3年でフラッシュシステムの研究開発で1000億円の投資を行なうこともあわせて発表した。
フラッシュ前提にしたハードウェア設計
製品概要について説明した日本IBM システムズ&テクノロジー・エバンジェリストの佐野正和氏は、フラッシュはあくまでメモリなのにもかかわらず、ディスクとして制御されている点をSSDの課題として挙げた。
たとえば、ハードディスクの場合、活動できるヘッドが1つなので、同時に1つのデータにしかアクセスできない。またディスクの場合、部分的に壊れても、ディスク全体が壊れてしまうことになる。さらにディスクのセクター配置やアームの動きによって、アクセスの最適化が阻害されてしまう。この結果、メモリがメモリとしての能力を発揮できていないと指摘した。

日本IBM システムズ&テクノロジー・エバンジェリスト 佐野正和氏
これに対してIBM FlashSystemはディスクをシミュレートするSSDとは異なり、フラッシュをあくまで“メモリ”として扱い、アクセス性能の向上や可用性の確保を目指す設計になっている。
まずフラッシュに関しては、汎用MLCフラッシュではなく、耐久性の高いeMLCやSLCを採用。40個のフラッシュチップを1つのモジュールに搭載し、これらを筐体内のメモリスロットのようなインターフェイスに装着する。物理的な装着方法からして、フラッシュをディスクではなく、メモリとして扱っているわけだ。既存のSSDと異なるこうした実装設計により、通常のSSD搭載ストレージに比べ、約5倍の収容効率を実現できるという。
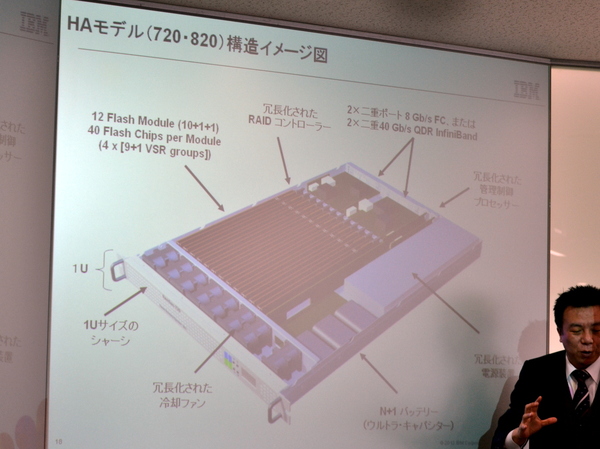
フラッシュをメモリのようにモジュールで装着

フラッシュメモリの特徴を活かした高集積設計
さらに、アクセスの高速化のため、従来汎用CPUとソフトウェアで実行していたデータの入出力を、専用のFPGA(Field Programmable Gate Array)でハードウェア処理する。ソフトウェア制御による割り込みや同一処理のループを、事前に配線された並列処理用の回路でまわすことで、パフォーマンスを最大化。さらにFPGAをモジュール上に複数実装することで、分散処理できるようにした。また、バックプレーンとの接続も、PowerPCベースのゲートウェイコントローラーを介して行なわれる。全般を通して、可能な限りソフトウェア処理を排除しているため、高速な処理速度と低遅延が実現されるわけだ。
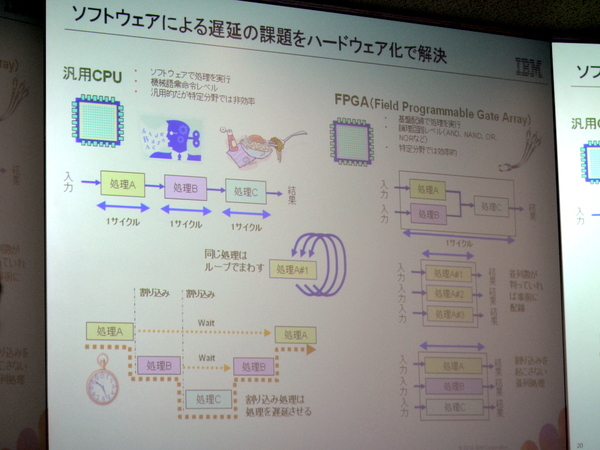
汎用CPU+ソフトウェア処理を排除し、FPGAでハードウェア処理
(次ページ、メモリならではの「2D RAID」で可用性を確保)
本記事はアフィリエイトプログラムによる収益を得ている場合があります



