




6月7日、日本IBMは非構造化データ(テキストデータ)の分析ソフトウェアの新バージョン「IBM Content Analytics with Enterprise Search V3.0」(ICA V3.0)を発表した。Hadoopとの連携が可能になり、従来バージョンの10倍のデータ量に対応できる。
検索と自然言語解析の融合
IBM Content Analytics with Enterprise Search V3.0は、名前の通り「コンテンツ(非構造化テキストデータ)の解析ツールとエンタープライズサーチを組み合わせたソフトウェア」と表現できる。Hadoopとの連携が可能になったことで扱えるデータ量が従来の10倍、ペタバイト単位にまで拡張された結果、ビッグデータに対応する膨大な量のテキスト解析が実現したという。たとえば、Twitterの言語別つぶやき件数で日本語は第2位で、1日あたり約2600万件のつぶやきがあるというが、ICA V3.0では数億件規模、約1~2週間分の日本語によるつぶやきすべてを一度に分析することが可能だという。
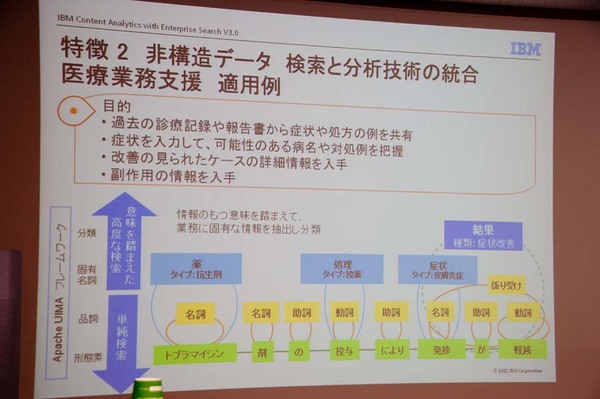
ICA V3.0による自然言語解析のイメージ。一般的な検索ツールのような文字列単位のインデックスだけではなく、文の構造を文法的に解析し、品詞を判断した上で文意を踏まえた高度な検索を実現している。
また、従来11言語に対応していたが、V3.0で新たにロシア語、チェコ語、ヘブライ語、ポーランド語の4言語に対応し、計15言語の分析ができる。この15言語で、全世界の総人口の約70%がカバーできるという。
ソフトウェアとしてみると、インタラクティブにアドホックな検索/抽出を行なうためのインターフェイスが前面に出ており、利用イメージとしては「大量のテキストデータの中から関連の高い情報を抽出するためのツール」のように見える。ただし、単に文字列のマッチングを見ているだけではなく、ソースとなる大量のテキストデータを独自の自然言語分析技術によって単語単位での切り分けや品詞分解、主述や係り受けといった文法的な構造までを解析している点だ。この自然言語解析技術は、もともと日本の基礎研究所で開発されたもので、起源は機械翻訳技術の研究にあるという。この結果、単語の意味を文脈から推測するという、人間が文意を把握するのと同様のプロセスで分析を行なうことができる。
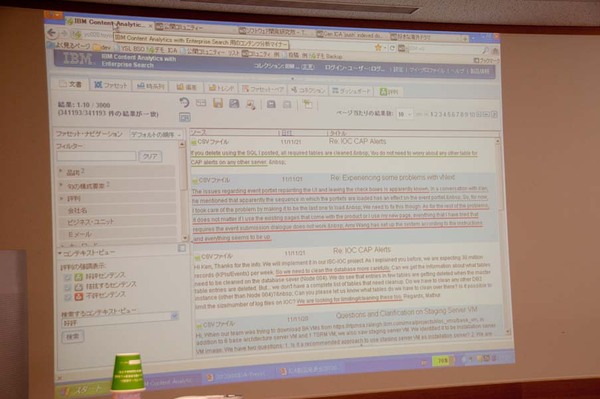
ICA V3.0の画面イメージ。表示されているのはソースとなる「文書」の表示画面。「ファセット」「時系列」「トレンド」といったタブで、それぞれの分析を行なうことができる
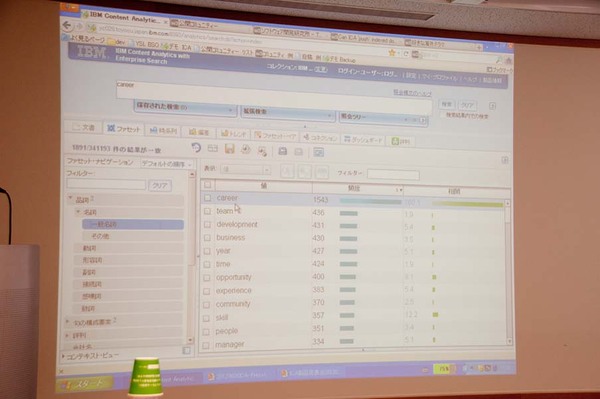
テキストを品詞に分解し、相互の相関を判定することで特定のキーワードに対してどのような言及がなされているかを判断できる
データの中から、ある特定のキーワードについて言及しているものを抽出し、さらに別のキーワードを加えたうえで強い相関関係にあるものを選び出す、といったインテリジェントな操作が可能な洗練された検索ツールとして機能するほか、文意が肯定的な評価なのか否定的な評価なのかを判断して明示する「評判分析」といった機能も実装する。Twitterの大量のつぶやきのなかから自社製品に対して言及しているものを抽出し、どのような評価が行なわれているかを知る、といったマーケット分析などの用途が考えられるが、曖昧な表現から関連する情報を見つけ出すテキストマイニングなどにも強みを発揮する。
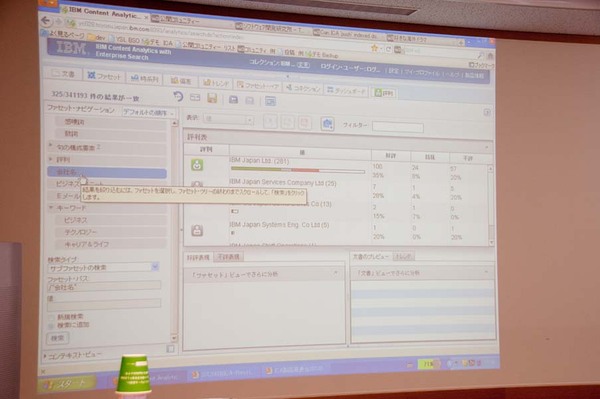
「評判」分析では、あるキーワードに対して肯定的な言及と否定的な言及の比率をグラフ化するなどの分析が可能
ライセンス価格は、同社独自のプロセッサコア数と処理能力に基づく“Processor Value Unit”単位で算出され、100Processor Value Unitあたり801万円からとなっている。




