



Datadogの実環境調査から紐解く“複雑化するAI運用”
急増するトークン消費にマルチモデル化 AI活用は“見える化”してから広げる時代に
2026年06月03日 17時00分更新

Datadog Japanは、2026年6月2日、Datadogユーザーの実環境を分析した「AIエンジニアリング」に関する最新レポートの日本語版を公開した。同レポートでは、生成AIが実装フェーズへ移る中で、複雑化するAI運用の実態が明らかとなっている。
同社のSenior Developer Advocateである萩野たいじ氏は、「AI運用の複雑さがボトルネックになり始めている」と指摘。「安易にAI導入を加速するのではなく、継続的な運用を意識して、“安全に拡張していく”段階に来ている」と強調した。

Datadog Japan Senior Developer Advocate 萩野たいじ氏
モデルが増えるごとに増大する運用負荷
今回のレポートは、グローバルで1000社を超えるDatadogユーザーの本番環境におけるデータに基づき、2026年3月時点のAIエンジニアリングの現状を分析したものだ。同レポートの説明会に登壇した萩野氏は、調査から得られた3つのポイントを抜粋し、組織が直面している課題を解説した。
最初に触れられたのは「単一モデルからマルチモデルへのシフト」だ。
LLMプロバイダー別の採用状況を1年前と比較すると、OpenAIが12ポイント減となりながらも、63%で首位を維持。一方で、AnthropicのClaudeが23ポイント増、GoogleのGeminiが20ポイント増と大きく採用を伸ばしている。ただし、OpenAIの利用量が減少しているわけではなく、他のプロバイダーの成長がそれを上回った結果、シェアが相対的に低下した形だ。
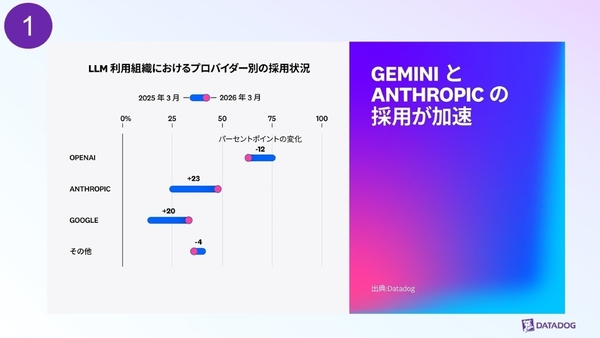
LLM利用組織におけるプロバイダー別の採用状況
さらに、この一年で著しく変化したのが、6モデル以上を利用する組織が、23%から41%へと急増したことだ。3モデル以上の併用に至っては、70%にまで達している。この背景について萩野氏は、「コストやレイテンシー、精度、安全性などに応じて、最適なモデルを選択する動きが広がってきたため」だと指摘する。
一方で、運用モデルの増加は、APIやセキュリティ、ガバナンス、フェールオーバー、コストといった管理負荷の増大に直結する。そのため、標準化されたモデル管理の仕組みが必須となっている状況だ。
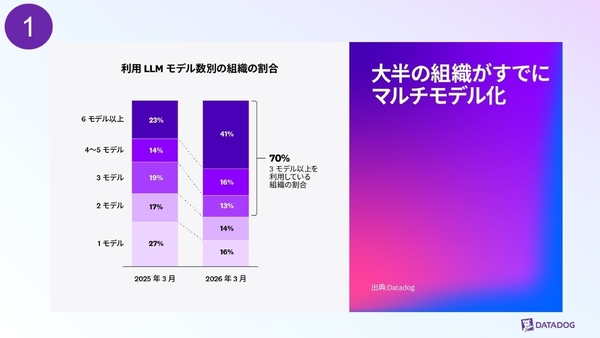
利用LLMモデル数別の組織の割合
フレームワークの利用拡大でAIワークフロードはブラックボックス化
2つ目のポイントが、エージェントフレームワークの利用拡大だ。
LangChainやLangGraphといったAIエージェントを構築するためのフレームワークの採用が、この1年で9.1%から17.5%へとほぼ倍増している。この傾向は、スタートアップから中堅企業、大企業まで同様である。
この結果は、AI活用が単純なモデルの呼び出しから、複数ステップの処理やツール連携などを伴う「より高度なワークフロー」へと移行している実態を裏付けている。
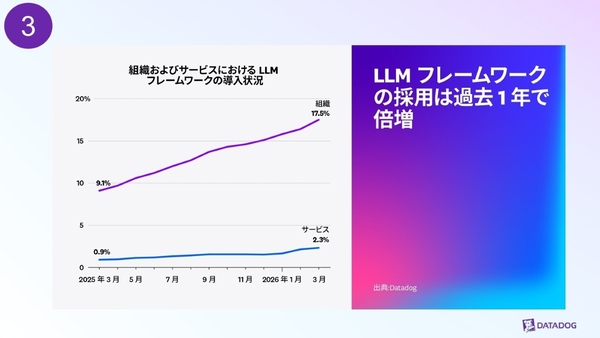
組織およびサービスにおけるLLMフレームワークの導入状況
フレームワークを利用すれば、高度なAIアプリを容易に実装できるようになる。しかし、フレームワーク内の処理が増え、AIワークフローがブラックボックス化する懸念が生じる。その結果、意図しないコスト増や性能の低下が発生しても原因が追跡できず、AI特有の再現性の低さも相まって、解決できない問題が増加してしまう。
「エージェント化が進むことでより成果を得られやすくなるが、運用面では、これまで以上に詳細な可視化やテレメトリが必要になる」(萩野氏)
トークン消費の急増で「コンテキストエンジニアリング」が重要に
3つ目のポイントは、コストに直結する「トークン消費量」の急増だ。この1年で、リクエストあたりのトークン使用量、つまりコンテキストの量が2倍以上に増大。上位10%のヘビーユーザー企業においては、実に4倍に膨れ上がっている状況だ。
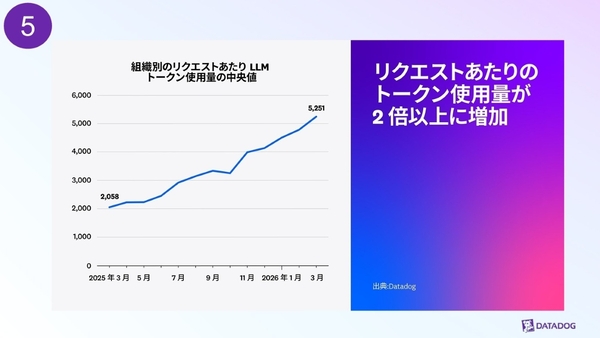
組織別のリクエストあたりのLLMトークン使用量の中央値
背景にあるのは、「コンテキストウィンドウの大幅な拡大」だ。主要モデルのコンテキストウィンドウはここ2年で劇的に広がり、最大200万トークンまで扱えるモデルも登場するほどだ。その結果、会話の履歴や検索結果、ドキュメント、ツールの出力など、多様な情報をLLMに与えられるようになり、AIシステムの高度化も進んだ。
一方で、プロンプトが肥大するほど、レイテンシーの悪化を招き、なにより推論コストを増加させる。加えて萩野氏は、「情報量が増え過ぎた結果、本当に必要なシグナルが埋もれてしまうリスク」を指摘する。
こうした中で先進企業は、コンテキストを構造化・最適化するための「コンテキストエンジニアリング」に投資の軸足を移しているという。
本記事はアフィリエイトプログラムによる収益を得ている場合があります



