




今回は、VLSIシンポジウムでインテルが招待講演として語った"Beyond RibbonFET: Energy Efficiency Innovations to Drive Technology and Design for the Next Decade"(TFS2-2)の内容を説明する。
Intel Foundryとしての提供がどうなるか、はともかくとして一応Intel 18Aはほぼ完成して、Panther Lakeの量産に向けて準備を整えるとともに、Intel 14Aの実用化に向けての作業も行なっているものと思われる(Intel 18A-PとIntel 18A-PTは、正直この先どうなるのか見えなくなっている。やるとしても優先度が下がりそうな感じだ)。今回の講演は、そのIntel 14Aのさらに先の話である。
プロセッサーが抱える現状の課題は
消費電力削減とトランジスタの小型化
昨今AI Eraなどと呼ばれるようになっており、AIプロセッサーに利用されるシステムの消費電力が大問題になっているのは御存じのとおり。
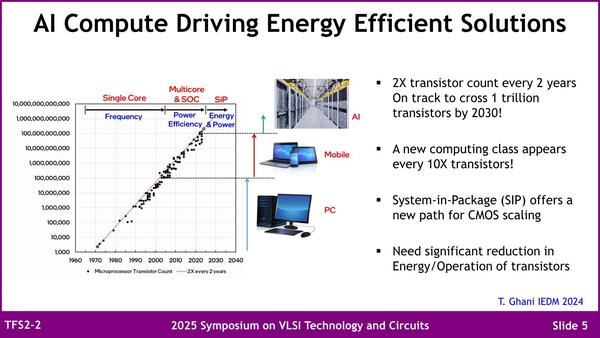
消費電力はトランジスタだけの問題ではないのだが、トランジスタも問題の1つであるのは間違いない
昨今では動作周波数を引き上げるのはだいぶ難しくなっており、むしろ演算器の数を増やす方向になっていて、それもあって世代ごとに必要となるトランジスタの数が10倍になるという状況になっている。特にAIでは並列処理が効果的に動くため、演算器の数にスケールするように性能が上がりやすいからだ。こういう状況であるから、消費電力を減らせないにしても増え方を抑えるためには、まずトランジスタの消費電力を下げるというか、より効率的にする必要があると説く。
このための基本的な構造は現在のGAA RibbonFETにBSPDNを組み合わせた形の進展で実現できるが、ただしその先には新材料や根本的に新しいデバイスが必要であるとする。

さて近未来、おそらくIntel 14Aの次か次の次くらいに来るであろう話が、トランジスタの小型化である。これはRibbonの幅を減らすことでCell Heightそのものを削減するとともに、Ribbonの数を減らすことで、それぞれCdyn(dynamic effective capacitance)を5%/10%削減できるとする。Cdynは要するにトランジスタが動作している時の、見かけ上の容量と見なせる。
このCdynがなぜ重要か? というと、動作に必要なエネルギーE=C×V<sup>2</sup>として計算できるため、Cdynを減らすとそれだけエネルギーが削減できるからだ。もちろん動作電圧を下げる方がより効果的ではあるが、電圧を減らすのは前提として、さらに下げようと思うと容量を小さくした方がいい。
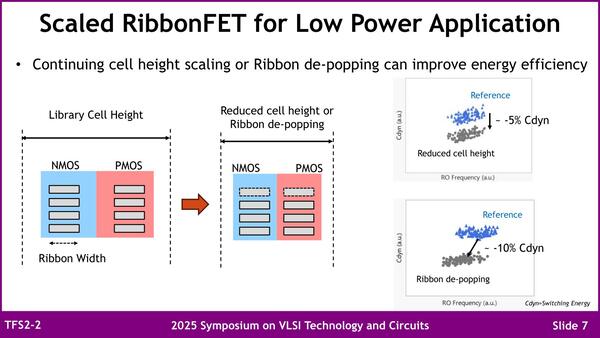
Ribbonの幅も枚数も、減らすことで流れる電流そのものが減るから、高密度向けではあっても高速向けとしては不適当ではある
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 -
第874回
PC
AIの未来は「電力」で決まる? 巨大GPUを支える裏面給電とパッケージ革命 -
第873回
PC
「銅配線はまだ重要か? 答えはYesだ」 NVIDIA CEOジェンスンが語った2028年ロードマップとNVLink 8の衝撃 - この連載の一覧へ














&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")


















ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












