
MI355XはMatrix Pathを大幅に強化
ではもう少し細かく見てみたい。下の画像は記事冒頭のチップ写真のアップであるが、ここからHBM3eのパッケージサイズ(11×11mm)を基準にそれぞれの寸法を算出すると下表になる。

ダイの拡大写真。厳密に計算したら、正方形ではなかった
| MI350の寸法 | ||||||
|---|---|---|---|---|---|---|
| パッケージ | 76.9×73.0mm | |||||
| XCD | 10.6×11.0mm=116.6mm2 | |||||
| IOD | 28.6×25.6mm=732.2mm2 | |||||
IODはかなり大きいが、先に書いたように以前に比べると大きなサイズでの歩留まりが向上していることが期待できる。一方でXCDは116.6mm2に収まっている。意外だったのは、N5→N3Pで面積が変わっていないことだ。
| MI300Xの寸法 | ||||||
|---|---|---|---|---|---|---|
| XCD | 115.0mm2 | |||||
| IOD | 370.0mm2 | |||||
というのはMI300Xは上表の寸法となっており、MI350XでIODのサイズが2倍になっているのは妥当なところ。その一方でXCDはほとんど面積が同じである(形は異なるが)。
余談ながらインターポーザーは57.1×48.8mmで2786.5mm2とかなり大きいが、2024年のTSMCのCoWoSのロードマップによれば、80×80mmまでの基板ではCoWoS-Sのままいけるとしており、今回もこれを利用して実装したものと考えられる。
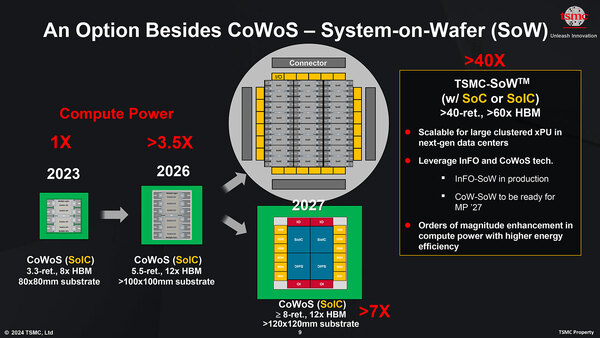
2024年のTSMCのCoWoSのロードマップ。次のInstinct MI400シリーズは、あるいは有機パッケージを使ったCoWoS-Rに切り替わるかもしれない
次に内部構造をもう少し。MI350の内部は下の画像のようになっているというのがAMDの説明である。

MI350の内部。XCDというのは本来はダイを指す名称だったのだが、まるでこれだとダイが8つあるように見えなくもない。構造を見ているとキレイな対称型になっており、物理的にダイが8つでも不思議ではないように見える(歩留まりを考えるとその方がお得だが)のだが、前頁2つ目の画像と矛盾する
この構造の模式図が下の画像で、おのおののXCDは36個のCUが搭載され、そのうち32個が有効化されており、それと4MBの2次キャッシュが組み合わされている。
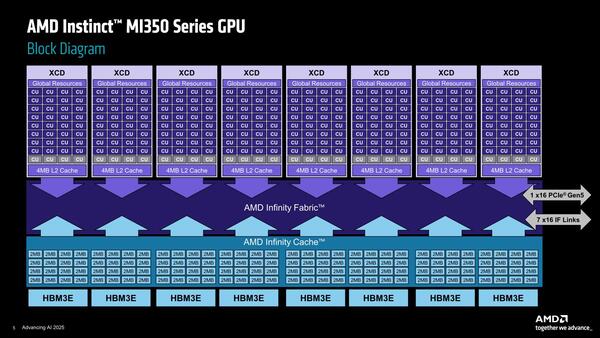
Infinity Fabric Advanced Packageはあくまで2つのIODのInfinity Fabric同士を接続するものであると理解できる
一方Infinity CacheはHBM3EのI/Fごとに32MB(2MB×16)が搭載され、これが8つで合計256MBという格好である。この構図を念頭にチップを拡大してみると、下の画像のような構図になっているのがわかる。
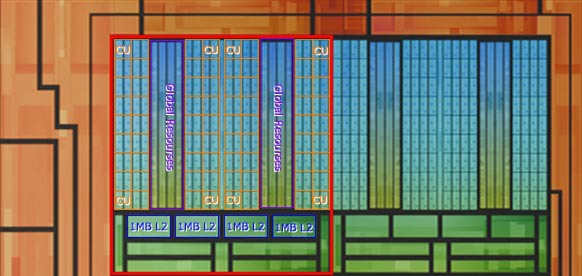
CUの構造次第ではあるのだが、もしMI300Xのものの延長にあるとすれば、CUの配置はこんな具合になっているものと思われる。2つのCU群の間に挟まれる紫色で囲んだ部分は、L1 Cacheとは考えにくい(最初はこれがL2かと思っていた)ので、Global Resourcesに相当する部分と考えた
さて問題のCUの構造だが、実はCUの構造が公開されていない。したがって、下の画像にある数字を基にCUの構成を推定する必要がある。

基本FP16/BF16以下のMatrix Pathの性能を倍増させ、かつFP6/FP4のサポートを追加したことになる
MI300XとMI355Xのスペックを比較したものが下表だ。
| MI300XとMI355Xのスペック | ||||||
|---|---|---|---|---|---|---|
| MI300X | MI355X | |||||
| XCD | 8 | 8 | ||||
| CU/XCD | 38 | 32 | ||||
| 総CU | 304 | 256 | ||||
| 総SP数 | 19456 | 16384(推定) | ||||
| 総Matrix Core数 | 1216 | 1024(推定) | ||||
| 最大動作周波数 | 2.1GHz | 2.4GHz | ||||
単純にCU数×動作周波数の比では以下の式になる。
304×2.1:256×2.4=638.4:614.4≒1:0.962
上の画像では"~1.0x"と丸められてしまっているが、前回の表では例えばVector FP16/32/64がいずれも"~0.96x"となっており、このCU×動作周波数の比に近いことから、CUの中のVector Pathに関しては少なくとも大きな手は入っていないように思われる。
したがって、Matrix Pathの方を大幅に強化した、というのがCDNA3→CDNA4の変更点というのは間違いないだろう。そもそもエリアサイズを比較した場合、(Global ResourcesやL2まで含めたラフな計算で言えば)、下式のようにCUあたりの面積は60%以上大きくなっている。
MI300X:40CU/115.0mm2なので2.875mm2/CU
MI350X:36CU/166.6mm2なので4.628mm2/CU
実際にはプロセスの違い(TSMCのN3は、ロジック密度がN5比で70%向上と説明されていた)も加味すると、仮にMI350XをTSMCのN5で実装したとしたら、面積は7.868mm2と2.74倍くらい巨大化していた可能性が高い。CUの規模を大型化したそのほとんどがMatrix Pathの性能向上に充てられたことがわかる。
しかも(これも前回も説明したが)Matrix FP64に関しては性能が半減している。これは、おそらくMatrix FP64の性能を維持したままではさらにサイズが大型化すること必至であり、Matrix FP64の性能を落とす(対応する演算器を減らす)ことでギリギリまでサイズを削ったのだろう。
こう考えると、MI350XはNVIDIAのBlackwell同様、HPCは捨ててAIを強化する方向に舵を切った構成と考えて間違いはないだろう。Blackwell対抗をうたう以上、HPC向けをある程度切り捨てないと勝負にならないのは仕方ないだろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ













