



ロードマップでわかる!当世プロセッサー事情 第801回
光インターコネクトで信号伝送の高速化を狙うインテル Hot Chips 2024で注目を浴びたオモシロCPU
2024年12月09日 12時00分更新

フォトニクスは別のプロセスで製造し
チップレットで接続するのが現実的
スライドの順番が変わっているが、インテルはプロセッサーの大量結合をAI Ageとしており、省電力と広帯域/高密度の配線が必要としている。
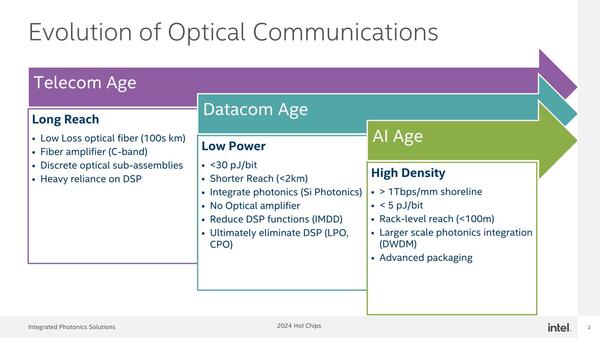
DWDM(Dense Wavelength Division Multiplexing:高密度波長分割多重)が必須、というのは単にインテルがDWDMに対応したMux/DeMuxをすでに手にしているから、という気もしなくもない
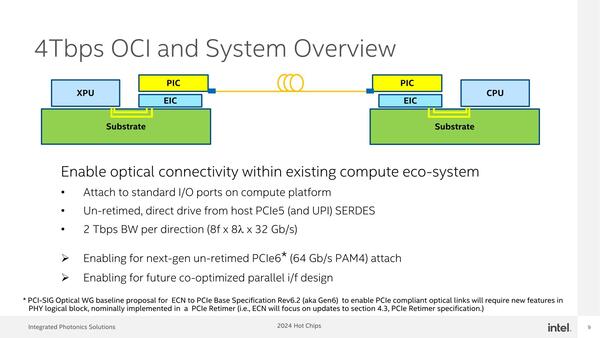
実際にこれをどう実装したのか? というのが下の画像だ。要するにBroadcomと基本的に同じであり、PIC(Photonics Integrated Circuit)とEIC(Electrical Integrated Circuit)を積層する形でOCI(Optical Compute Interconnect)のチップレットを構成し、これとプロセッサーの間をUCIeで接続する方式だ。

大きな構造は、BroadcomのTomahawk 5で採用されているものと同じである。ちなみにTSMCも同種のものを試作しているが、こちらはPICとEICが逆(PICが底面で、その上にEICが載る)の構造である
これまでのインテルではプロセッサーの中に直接実装するとか言いそうではあるのだが、現実問題として昨今のXPUは3nmプロセス(Arrow LakeはTSMC N3B、Xeon 6はIntel 3)を採用しており、この先は2nm以下(Intel 18AのRibbon FET構成)になる。
一方シリコンオプティクスはインテルでも22nmあたりであり、これを3nmや2nm以下に持ち込むのは厳しい。だからといっていまさら22nmなどでXPUを製造しても競争力は皆無である。素直にフォトニクスに関しては別のプロセスで製造し、それをチップレットの形で接続するのが現実的な解である、というわけだ。
スライドの中の"heterogenous integration trumps monolithic integration"(ヘテロ方式の統合がモノリシックな統合よりも優れている)というのはこのあたりの事情を考慮してのことと考えられる。
ちなみにチップレットの接続にUCIeを利用することに関する比較が下の画像である。例えば今回の試作は4Tbpsでの接続になっているが、こんな速度の配線は現実問題として無理である。

本文に示した1.25pJ/bitなり0.75pJ/bitという消費電力はあくまでUCIeの配線の分だけで、Host I/Fの分までは含まれていない。これらを全部合わせても5pJ/bit未満、というのがここでの説明である
短距離(数mm)の接続であっても信号速度は100Gbpsが一般的な上限で、がんばれば200Gbps(100G+PAM4変調)が可能かもというレベルであり、仮に200Gbpsだとしても20本の接続になる。しかもここまで信号速度を引き上げると、信号配線同士の干渉が大きくなるので、配線密度は1mm幅に500~800Gbps(つまり100Gbpsの信号配線を5~8対通す)が限界とされる。
一方のUCIe、最新の仕様はUCIe 2.0になっているが、信号速度そのものはUCIe 1.0と変わらず32Gbpsが上限である。ただし、その分配線の数を大幅に増やせるものになっている。仕様によればStandard Packageでは56対、Advanced Packageでは330対の信号を1mmの間に通せる。
Standard Packageのままでも56×32Gbps=1792Gbpsとなり、4Tbpsの信号の接続に必要な配線は4mm未満(3mm前後)の幅で片付く計算になる。またEnergy Efficiencyも、UCIeの仕様によれば0.7Vなら1.25pJ/bit、0.5Vなら0.75pJ/bitと極めて省電力である。
ただし、内部でバス幅の変換が必要になるのが欠点である。今回は該当しないのだが、例えば100Gbpsの光信号×20chに変換しようとした場合、32Gbps×63chを100Gbps×20chに変換するGear Box(前回のBroadcomのところに出てきた、バス幅/バス速度の変換機構)が必要になり、このGear Boxの消費電力がけっこうバカにならない。なのでなるべくUCIeの信号速度を変換せずに利用できるような工夫が必要となる。
そんなこともあってか、今回インテルは信号速度32Gbpsの光信号を64対(8波長×8ファイバー)束ねて、片方向当たり2Tbps(32Gbps×8×8=2048)、双方向で4Tbpsとなるリンクを構築したという発表となった。
ただ、1枚のキャリアボード上にモジュールを8つ搭載して、そこの相互接続にこれを使うのは配線の観点から美しくない気はするが、不可能ではない
これならUCIeの信号をGear Boxを介さずにそのまま光に変換し、DWDMを利用して多重化、光ファイバーに送り出す(受信側はその逆)ことができる。片方向当たり2Tbpsというのは256GB/秒であって、PCIe 5.0x16の4スロット分の帯域である。
現状、例えばGaudi 3が相互接続に200G イーサネット×3を使っており、リンクあたり600Gbps「しかない」ことを考えると、片方向当たり2Tbpsのリンクの高速さがよくわかると思う。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























