



ロードマップでわかる!当世プロセッサー事情 第796回
Metaが自社開発したAI推論用アクセラレーターMTIA v2 Hot Chips 2024で注目を浴びたオモシロCPU
2024年11月04日 12時00分更新

2週空いてしまったが再びHot Chips 2024で注目を浴びたオモシロCPUに戻る。第7弾は、MetaのMTIA v2である。初代であるMTIAは連載730回で名前だけ出てきたが、内部についての説明はしていないので、まずはここから話をしたい。
RISC-Vベースだが限りなく専用プロセッサーに近い
AI推論用アクセラレーターMTIA v1
MTIA v1は2023年に発表された。目的は推論処理の高速化であり、特に同社のサービスのRecommendation EngineをGPUベースから置き換えることを目的としていた。

MTIA v1。開発開始は2020年とのこと
製造プロセスはTSMCのN7で、800MHzで動作。INT 8で102.4TOPS、FP16で51.2TFLOPSの性能を持つとされる。
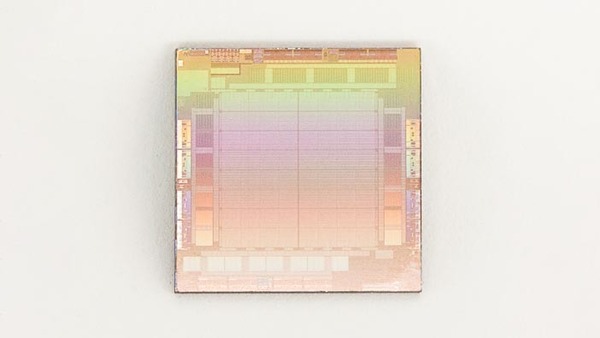
MTIAのダイ。TDPは25Wとのこと。ダイサイズやトランジスタ数は公開されていない
内部構造は下の画像のようになっており、中央に8×8で合計64個のPE(Processor Element)が配される。PEの内部構造そのものは未公開であるが、おのおののPEには2つのRISC-Vベースのコアが搭載され、片方にはVector Engineも搭載されている。
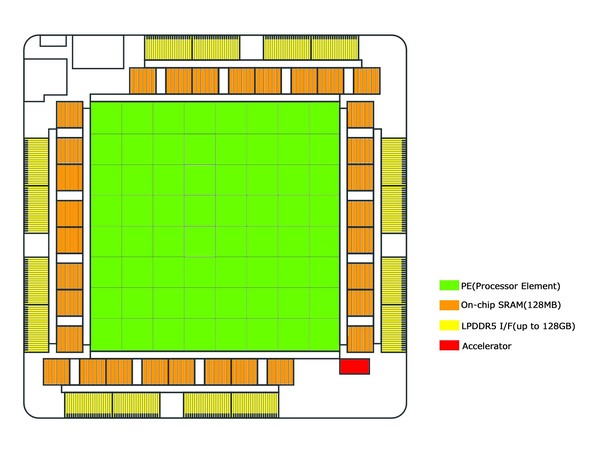
MTIAの内部構造。元の図はMeta提供。着色と脚注は筆者
また行列の乗算と加算、データ移動、非線形関数(アクティベーション用と思われる)のための専用命令が追加されているそうで、RISC-Vベースとは言え限りなく専用プロセッサーに近い。おそらくはVector Engineを搭載しているコアには行列の乗加算や非線形関数のアクセラレーターが搭載され、こちらが演算処理を行なう。
もう一方のコアはデータ移動のアクセラレーターが搭載され、これが処理の制御であったり、ほかのPEとのデータ移動だったりをつかさどるものと思われる。64PEでINT 8で102.4TOPSなので、1PEあたり1638.4GOPS。800MHz駆動だから1サイクルあたり2048 Opsという計算になる。
これをVector Engine(つまりSIMD)だけで実装しようとすると巨大なSIMD(16384bit幅!)が必要となるが、どうもこの102.4TOPSは行列乗算(俗に言うTensor Engine)の結果と思われるので、そこまで大規模な回路でなくてもなんとかなりそうだ。これに加え、各PEには128KBのSRAMが搭載されており、スクラッチパッドのように利用可能なものと思われる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























