



ロードマップでわかる!当世プロセッサー事情 第793回
5nmの限界に早くもたどり着いてしまったWSE-3 Hot Chips 2024で注目を浴びたオモシロCPU
2024年10月14日 12時00分更新

WSE-2は事前に処理が必要なGPUと違い
200倍の帯域が利用できて効率が10倍良い
2022年のHotChips 34では"Cerebras Architecture Deep Dive:First Look Inside the HW/SW Co-Design for Deep Learning"と題し、WSE-2の内部構造の説明が行なわれた。そもそもWSE-1の時も非常にラフな構造の説明しかなかった。まずWSE-2では85万個存在する、個々のコア(Cerebras用語ではPE:Processor Element)が下の画像だ。
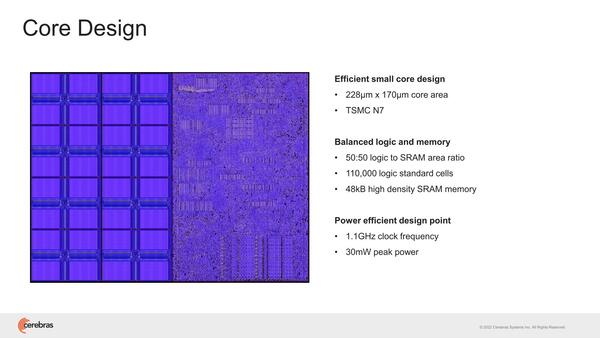
Standard Cellで製造、というのも昨今ではすごい。後述するが、SRAMは48KBを8バンクに分割しており、個々のバンクは6KBということになる
1.1GHz駆動と動作周波数は控えめだが、ピークでも30mWと控えめではある。もっともこれが85万個あるので、本当に全コアがフル稼働するとピークでは25.5KWもの消費電力になる。もっとも前ページのウェハー写真でもわかるように、実際にはこの85万個のPEが84個のダイに分割されており、個々のダイの消費電力は300Wほどになるため、妥当と言えば妥当な数字である。
ここのPEの内部が下の画像で、6ステージのパイプライン構造のインオーダー構造の演算器であるが、FP16を1サイクルで4演算できるようになっている。ここで言う演算はFMAC(Multiply and ACcumulate:積和演算)で、なので見かけ上は1サイクルで8演算になる。
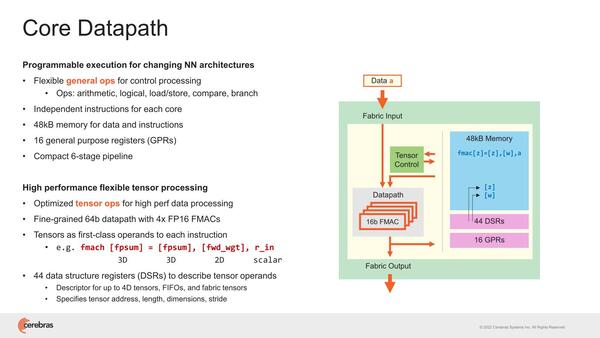
PEの内部構造。テンソル演算でも性能は変わらない。単にデータの持ち方を変えるだけで、演算そのものは4つの16bit FMACで行なうからだ
このPEはデータフローの形で動作する、というのは前回の記事でも説明した通りで、なにもしなくてもSparsityを実現できることになる。このあたりが、事前に処理が必要なGPUとの違いであり、結果効率が10倍良いとするのは大げさではあるかもしれないが、嘘ではないだろう。
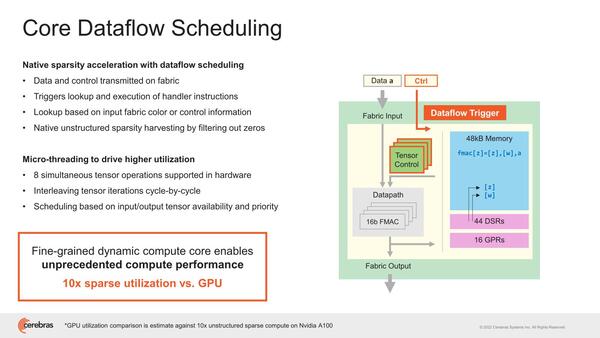
テンソルの場合、1回の演算に複数サイクルを要する(FMACが4つしかないから)。そこでマイクロスレッディングを利用して、演算順序の制御やプライオリティの管理などができるというのはなかなかおもしろい
SRAMブロックの構成が下の画像で、6KBのバンク×8が用意され、かつSWキャッシュが256B搭載される仕組みになっている。SWキャッシュがスクラッチパッドなどではなくキャッシュなのは、これは外部から書き込みするだけで、PE自身にはキャッシュを変更できないためと思われる。
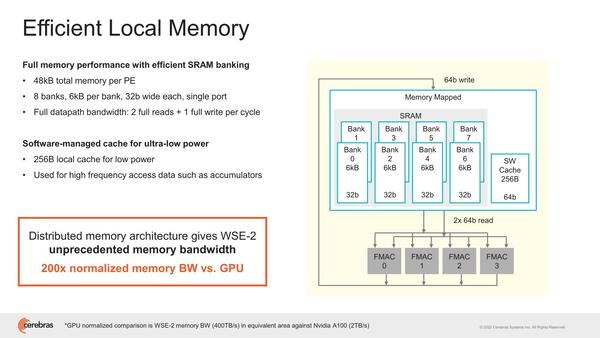
SW-Managed cacheとはあるが、そのSWはどこで動いているものか? というと、PEというかダイというか、全体を管理する上位のコントローラーだろうと思われる
ここの表現を見ると、特にテンソル演算の場合など、同じ処理をずーっと繰り返す、DSP的な動き方になる。PE自身でこれを制御するためには、分岐予測やBTB的なものを用意して、処理が終わったら次のコードに移行するのではなくまた元に戻って繰り返すことをハンドリングする必要があるが、PEにそれを持たせるのは無駄が多いと判断したのだと思われる。
結果的に、DSP的にぶん回すような用途で、GPUと比較して200倍の帯域が利用できるとしているが、この数字が正しいのかどうかは判断がつきかねる。
ちなみにその帯域の話で言えば、処理内容に応じて要求される帯域にはけっこう差があるのは知られた話である。
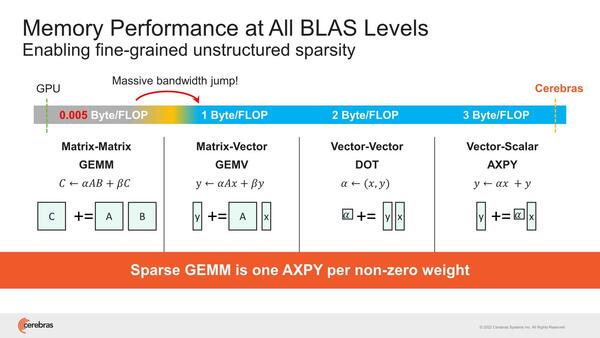
おのおののバンクは32bit幅なので、つまり4バンクからの同時読み出しと、2バンクへの書き込みを1サイクルでできる計算だ
例えばNVIDIAのBlackwellは20PFlops演算性能と8TB/秒のメモリー帯域とされているわけだが、ということは2万TFlopsと8TB/秒だから、演算当たりのメモリー帯域は0.0004Bytes/Flopsという計算になる。
実際には内部の2次キャッシュの帯域はもう少し大きいが、容量は小さいのですぐに使い切ってしまい、結局HBMアクセス待ちになる。これがWSE-2では16bitのFMAC×4に対して、64bit/サイクルの読み込み×2 + 64bit/サイクルの書き込み×1で、3Bytes/Flopsになる計算で、圧倒的に有利としている。
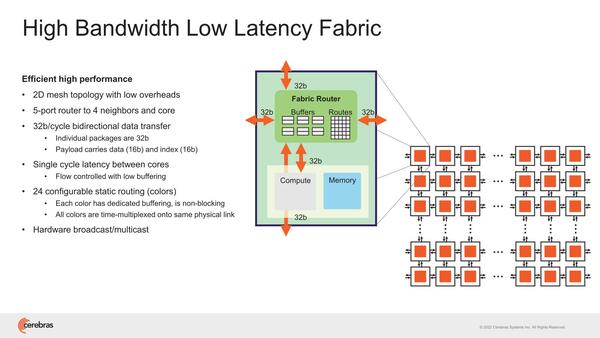
WSE-2ではこのPEを1万156個集積したダイを84個つなぐ形で構成される。おのおののPEの外には5ポートのルーター(うち4ポートは隣接ノードに、1つはPEに接続)が設けられ、これで2次元メッシュを持つ構造だ。バス幅は32bitで、ただしデータは16bit(残りはIndex)なので、PEをまたいでのメモリー参照などはあまり現実的ではない。あくまでPEは自身のSRAMだけを対象に演算すると思われる。
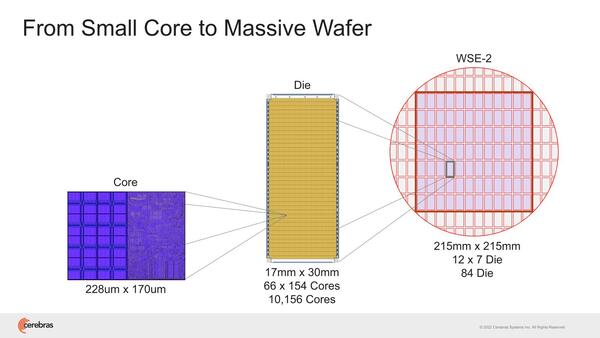
実際には1つのダイには66×154で1万164個のPEがあり、これが84ダイで85万3776個のPEがあるはずだが、当然欠陥があるのでそこは無効化する形になる。つまり冗長PEが3776個あると考えるのが妥当だろう。そもそもダイあたりのPEが8つほど少ないのも、冗長PEのためと思われる
続く2023年のHotChipsでは、クラスターに関する詳細が示された。まずMemoryX、2021年には「2~192台までのWSE-2に対応し、4TB~2.4PBまでのメモリー搭載」と発表されていたが、2023年には多少アップデートされた。
1台のMemoryXは、1TBメモリー/500TBフラッシュで、1台のWSE-2にはこれを12台接続可能。64台なら768台接続できる、ということらしい。やはりシャーシ1個で2.4PBのストレージは無理があったようだ
このスペックからすると、どうも1ノードのMemoryXは1Uのシャーシに収まる規模になり、あとは顧客のニーズというか、どの規模のメモリーを必要とするかで最大12台まで接続できるようになっている模様だ(Dedicated interfaces to WSE-2 and *other MemX*とあるあたり、MemoryX同士での相互接続も可能になっているようだ)。
下の画像はCerebrasが提供するAndromedaという1 Exaflopsのシステムの写真だが、左から9ラック目に12本装着されているのがMemoryXではないかと思われる。

SwarmXは上側であろうか? この一列だけではSwarmX(やEPYC接続用スイッチ)が収まらず、別のラックに収まっている可能性もある
ちなみにこのシステムは他にEPYC Gen3を合計1万8176コア搭載しており、左から1~8および9・10・12ラックに収められた1Uシャーシ(合計132枚)と、11・14~16ラック目の2Uシャーシ(合計12枚)には、全部64コアの2ソケットEPYCが搭載されているものと考えられる。
同様にSwarmXもシャーシが複数必要である。4×WSE-2で12ノードだから単純計算すればWSE-2 1つあたり3ノードのSwarmXが必要になる計算だが、これはノード数が増えるほど大規模になる。
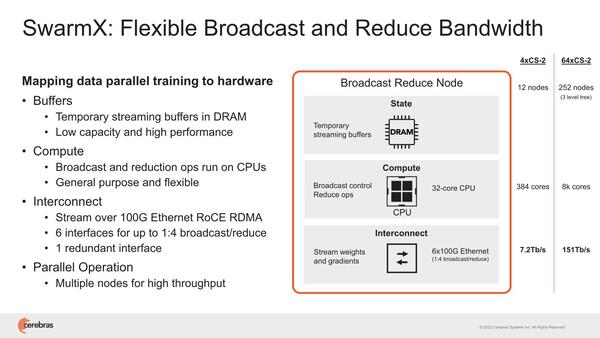
SwarmXもシャーシが複数必要だ。例えばBroadcomのTomahawk 5なら、800GbEで64本、400GbEで128本、200GbEなら256本のリンクを1つのチップで接続できるから、64台のWSE-2でもフラットなネットワークを構成可能である。ただこれは汎用品であることを考えると、そのまま使うことはできないだろう
WSE-2が64ノードだと3 level tree(おそらくFat Treeを構成するのだろう)が必要で、合計252ノードなどになるのは少し多すぎる。独自のプロトコルを実装している関係で、既存のスイッチが使えない結果がこの有様で、このあたりは今後スイッチベンダーと協業して、もっと大規模かつ高速なスイッチになるかもしれない。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






























