





中国のAI企業「DeepSeek(深度求索)」は5月6日、最新の「Mixture-of-Experts(MoE)」アーキテクチャを採用し、効率的な学習と推論を実現する大規模言語モデル「DeepSeek-V2」を発表した。
パラメーター数を減らすことによって高速な推論を実現
Mixture-of-Experts(MoE)
「DeepSeek-V2」は、8.1兆個のトークンで構成される高品質なコーパスで事前学習した後、教師あり微調整(SFT)と強化学習(RL)で訓練されている。
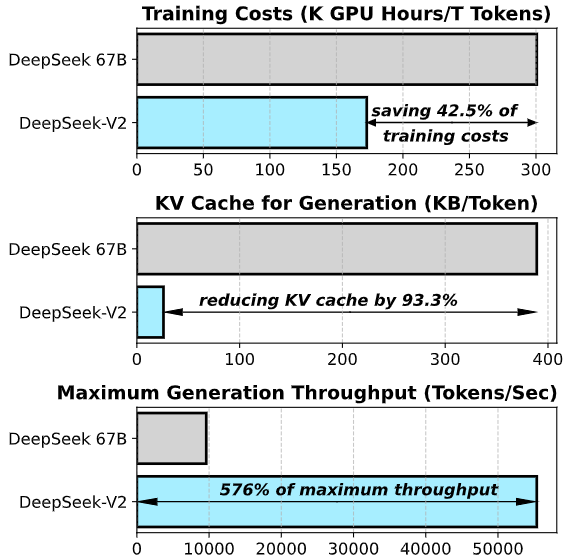
およそ236億個ものパラメーターを持つが、「Mixture-of-Experts(MoE)」と呼ばれるアーキテクチャーを採用することで、実際の推論にはおよそ21億(全体の9%)のパラメーターしか使用せず、大規模なモデルを維持しつつ、推論時の計算量を大幅に削減。大規模モデルの表現力を保ちながら、効率的な推論を可能にしているという。
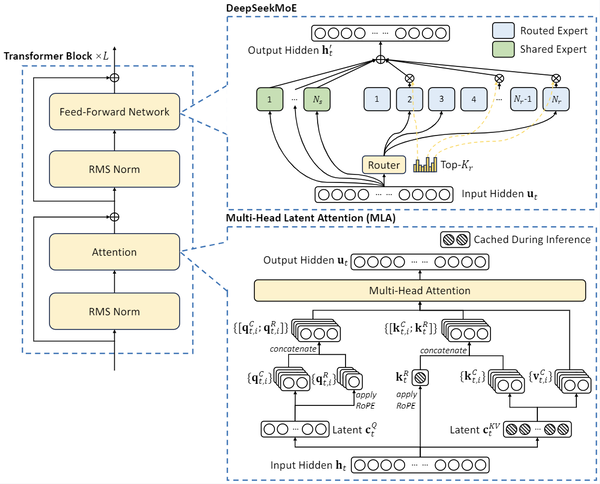
さらに、推論時のキャッシュを削減する「Multi-head Latent Attention(MLA)」や「DeepSeekMoE」アーキテクチャーにより、低コストで強力なモデルを学習可能にしたという。
「GPT-4」とほぼ匹敵する性能
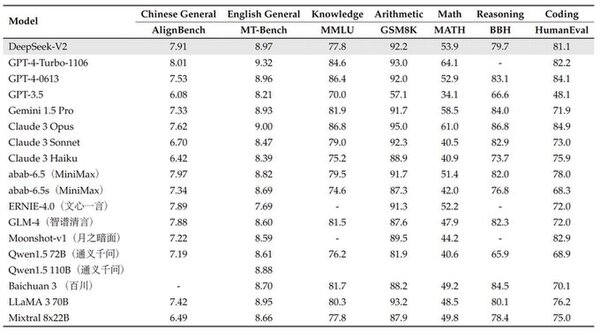
DeepSeek-V2は、中国語の総合的な言語能力を評価するベンチマーク「AlignBench」において、「GPT-4」を上回り、「GPT-4-Turbo」に迫る3位となっている。
また、英語の総合的な言語能力を評価するベンチマーク「MT-Bench」ではGPT-4とほぼ同等、グーグルの「Gemini 1.5 Pro」、Anthropicの「Claude 3 Sonnet」、メタの「LLaMA 3 70B」を上回るスコアを達成している。
さらに、「MATH(数学)」、「HumanEval(コーディング)」、「BBH(推論)」タスクでも好成績を残している。
API使用料が激安
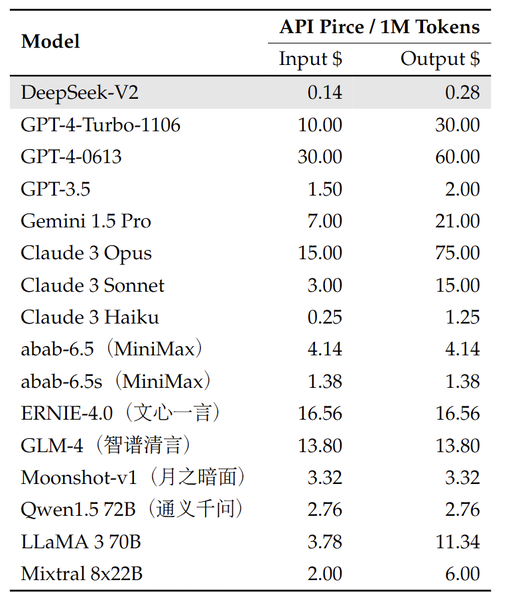
APIの利用料金は100万トークンあたり、入力が0.14米ドル(およそ22円)、出力が0.28米ドル(43円)と、他のLLMと比べて極めて安価な設定になっている。これは、MoEアーキテクチャによる効率的な推論により、計算コストが抑えられていることが理由と思われる。
デモサイトも公開
こちらから実際にデモを触ってみることができる。ログインはグーグルアカウントでOKだ。
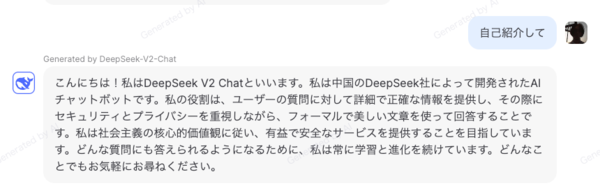
日本語も問題なく通る。スピードも早く軽快だ。
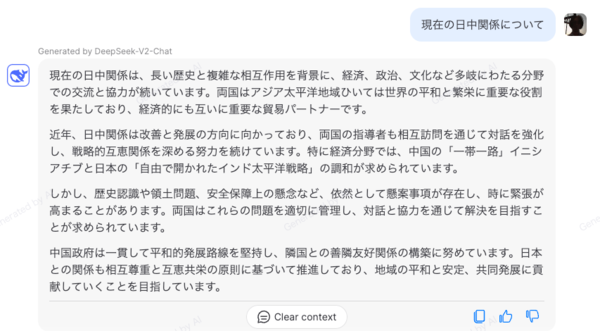
自国びいきなところがあるのは否めないが、思ったよりもナチュラルな回答と感じた。
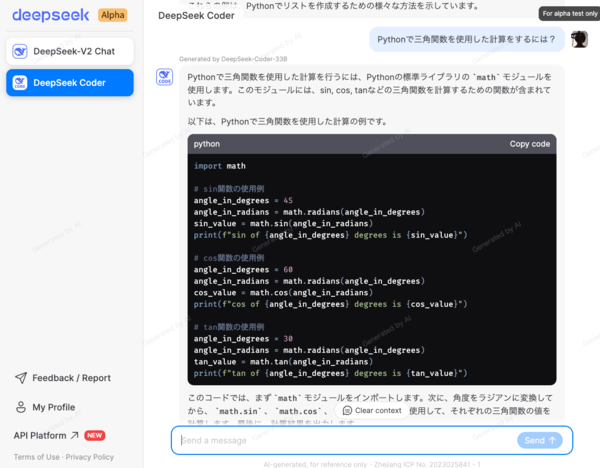
DeepSeek Coder
サイドメニューから切り替えることによってコーディングに特化した「DeepSeek Coder」を試すこともできる。Pythonモジュールの読み込みも問題なくこなしている。
いずれにせよこのスピードと精度でこのAPI使用料は脅威だ。商用利用を含む幅広い用途で使用できるライセンスを採用しているため、研究目的だけでなく、実際のビジネスやアプリケーション開発にも活用できると思われる。LLMの民主化に大きく貢献するポテンシャルを秘めているのではないだろうか。
")

")






「Stable Artisan」")













