





動画生成AIの研究「Open Sora」から派生した「MagicTime」の技術で生成した桜の開花の動画の一部(筆者作成)
2024年1月にOpenAIが発表した動画生成AI「Sora」はインパクトがありましたが、DeepMindが開発したフレームごとの動画をブロック状にデータとして出す方式「時空間パッチ(Space-Time Patch)」という方式を使ったのではないかと推測されていました(「動画生成AIの常識を破壊した OpenAI「Sora」の衝撃」参照)。発表された技術レポートの情報を合わせて、推測する方式をまねれば、同様のことができるのではないかということで、新しい動画生成AIの研究が進んでいます。
OpenAI「Sora」まねた研究が続々
その代表例が、3月リリースされた「Open Sora」というプロジェクト。中心として進めているのは、中国系のAIスタートアップのHPC-AI Techという企業などの中国系の研究者たちです。Soraのメソッドで推測できる部分から、再現していこうというプロジェクトで、「すべての人への効率的な映像制作の民主化」というコンセプトを掲げています。
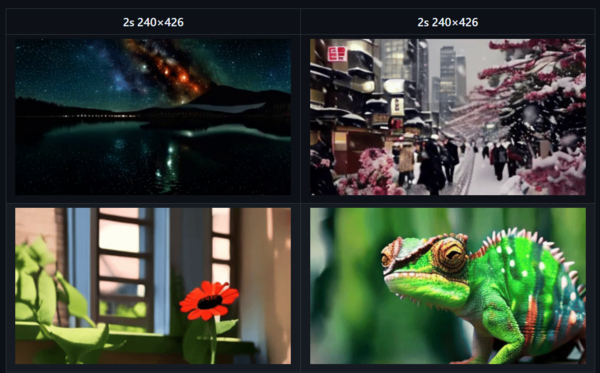
Open Soraで生成された動画。2秒と限定的だが一貫した動画が作れている(GitHubより)
適切なデータセットを揃えられれば、似た動画を生成できる可能性があるため、Soraを既存技術で再現しようとしているのです。16フレームで学習しているため、最長2秒で、解像度も240x426ピクセルと小さなサイズですが、Soraをまねた空間的な特徴を学習することができる手法を使うことで、一貫性を維持した動画の生成に成功していました。最初のバージョンの1.0では3日間のトレーニングで実現できたと述べています。

Open Sora Planで生成された動画。2秒ながら複雑な自然の風景の描写に成功している(同上)
そして、このモデルを土台とした派生研究が登場しています。
そのひとつが4月に発表された「Open Sora Plan」という派生モデル。北京大学信の袁粒(リー・ユアン)准教授の研究室が開発したモデルです。やはり最長2秒という限界がありますが、基本の画像サイズが512x512ピクセルとなり、クオリティが上がっています。約4万本のパブリックドメインの動画を元に学習したそうです。そのうち60%が風景映像ということで、海の波が打ち寄せる様子や、海中の風景、たき火が燃える様子など、自然物の動画描写を実現しています。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第149回
AI
AIと8回話しただけで“性格が変わる” 研究が警告する「おべっかAI」の影響 -
第148回
AI
AIが15万字の小説を1週間で執筆──「Claude Opus 4.6」が示した創作の未来 -
第147回
AI
ゲーム開発開始から3年、AIは“必須”になった──Steam新作「Exelio」の舞台裏 -
第146回
AI
ローカル音楽生成AIの新定番? ACE-Step 1.5はSuno連携で化ける -
第145回
AI
ComfyUI、画像生成AI「Anima」共同開発 アニメ系モデルで“SDXL超え”狙う -
第144回
AI
わずか4秒の音声からクローン完成 音声生成AIの実力が想像以上だった -
第143回
AI
AIエージェントが書いた“異世界転生”、人間が書いた小説と見分けるのが難しいレベルに -
第142回
AI
数枚の画像とAI動画で“VTuber”ができる!? 「MotionPNG Tuber」という新発想 -
第141回
AI
AIエージェントにお金を払えば、誰でもゲームを作れてしまうという衝撃の事実 開発者の仕事はどうなる? -
第140回
AI
3Dモデル生成AIのレベルが上がった 画像→3Dキャラ→動画化が現実的に -
第139回
AI
AIフェイクはここまで来た 自分の顔で試して分かった“違和感”と恐怖 - この連載の一覧へ



















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















