ロードマップでわかる!当世プロセッサー事情 第766回
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ
2024年04月08日 12時00分更新

AMDのInstinct MI300に関しては連載701回や連載726回、連載751回などで説明してきたが、今年のISSCCでAMD自身によるDeep Diveの説明があったので、この内容を解説しよう。といっても性能に関しては言及がなく、焦点は3D構造の実装になる。
複雑なMI300A/Xの内部構造
IODは共通で、XCDとCCDのどちらも搭載できる
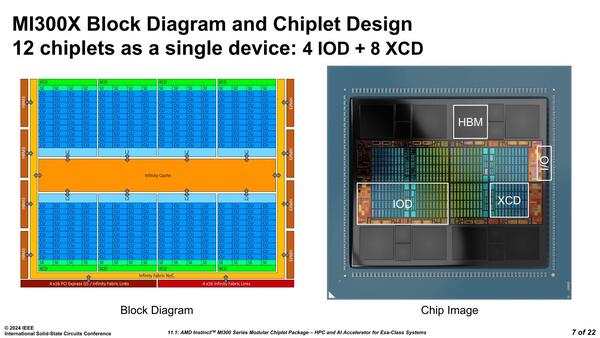
まずおさらいであるが、MI300A/Xともに複数のGPU(XCD)と、MI300AはさらにCPU(CCD)を、インフィニティ・キャッシュを搭載したI/O Die(IOD)の上に搭載、さらにこのIOD同士を2.5Dで接続し、外付けに8スタックのHBM3を接続する構造になっている。

MI300Aの構造。MI300XではCCDがなく、代わりにXCDが×8になる
ちなみにIODの説明だが、128chのHBM3チャンネルや256MBのインフィニティ・キャッシュは4つのIODの合計の数字であり、IOD1つあたりで言えばインフィニティ・キャッシュは64MB、HBM3は32ch(HBM3は1スタックあたり16chのI/Fを持つ)という計算になる。
インフィニティ・ファブリック・リンクの数とPCIeの数が割り切れないのは、おそらくおのおののIODには64ch分のPCIe/インフィニティ・ファブリック共用のPHYが用意されており、インフィニティ・ファブリックは32ch分で1リンクとなるのだろう。したがって4つのIODで合計256chのPHYがあり、このうち224chは7本のインフィニティ・ファブリック・リンクに割り当てられ、残りの32chが2×PCIe Gen5x16に割り当てられるという構造と考えられる。
下の画像が内部構造図なのだが、これはややわかりにくい。左側はあえて簡略化しているのだろうが、XCDには40個のCUが搭載されており、うち2つが無効化され実際に利用されるのは38CUである。これが8つでトータル304CUというわけだ。
ほかに1つのXCDには4つのACE(Asynchronous Compute Engines)が搭載されており、SEはこのACE(と、その下におのおの8つのHQD:Hardware Queue Descriptors)を指しているものと思われる
2次キャッシュは4MBであるが、メモリー階層構造を見る限り、この2次キャッシュは1つのXCD内のCUで共有という形であり、異なるXCD同士の2次キャッシュは上位のクロスバー(つまりインフィニティ・キャッシュ)経由での接続になるので、グローバル・キャッシュというよりはローカル・キャッシュとみなすべきなのだろう。
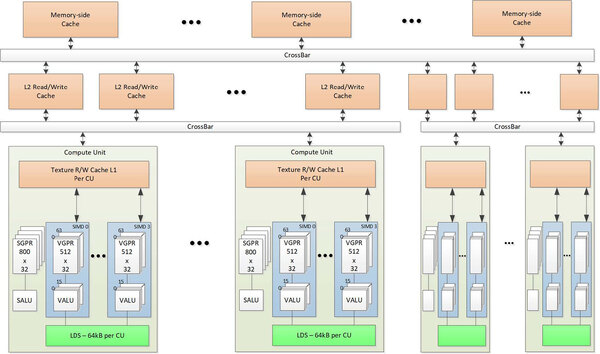
メモリー階層構造。一番下段の箱がCUである。画像を扱うわけではないのに"Texture R/W Cache"というのも変な気がする
"AMD Instinct MI300 Instruction Set Architecture Reference Guide"より抜粋
まず実装方法である。先に書いたように、XCD/CCDはIODの上に載っているが、XCDおよびCCDはどちらも一種類で、これをそのまま載せるか、180度回転させて載せるかであるが、IODに関してはやはりミラー構造を採用することになった。

これはMI300Aの場合で、MI300Xの場合は右上のIODの上にCCDではなくXCDが載るわけだ
このミラーというのは、要するに鏡対称のことだ。これ、Sapphire Rapidsの構造の議論のところでも出てきた話だが、上の画像で言えば左上のIODと左下IODは、回転させてもいろいろつじつまが合わないことになる。
左上と左下は、ちょうど真ん中で相互接続する必要があるし、左端にはPCIe/インフィニティ・キャッシュのI/Fを集約する必要がある。また上下にHBMのI/Fも設けなければならない。これを満たそうとすると、どうやっても鏡対称となる2種類のダイを作らなければ解決しないことになる。
実際Sapphire Rapidsでも4タイル構成のXCC SKUは鏡対称となる2種類のダイが用意されていることが確認されており、AMDもこれにならったわけだ。
このことはそれほど驚きではないのだが、ここではっきり"Four unique tape-outs:two IODs, one XCD and one CCD"とあるのは驚きだった。上の画像の右上にあたるIODは、Instinct MI300AとInstinct MI300Xで共通になるからだ。要するにIODは、XCDとCCDのどちらも搭載できるように設計されているわけだ。てっきり筆者は、XCD用とCCD用で異なるIODを用意していると考えていたからだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ













