

本記事はFIXERが提供する「cloud.config Tech Blog」に掲載された「【実践編】SQL Server にて Index を作成する」を再編集したものです。
SQL Server にてIndexを作成しようとしたところ、元のクエリを参考にしてIndexを作成するような記事がすぐに見つからなかったので、備忘録として記事にしてみようと思います。
Indexを貼るクエリを調整する
Indexを貼るクエリを決める
・事前にSSMSで該当のDBへアクセスしておきます。(Azure Data Studioでも代用できる認識です。)
・該当のDBに対して重いクエリを特定するクエリを実行します。(既にクエリを特定している場合はスキップでOKです。)
SELECT TOP 100
total_elapsed_time / execution_count / 1000.0 AS [平均実行時間(ミリ秒)]
, total_worker_time / execution_count / 1000.0 AS [平均 CPU 時間(ミリ秒)]
, SUBSTRING(text, (statement_start_offset / 2) + 1,
((CASE statement_end_offset
WHEN -1 THEN DATALENGTH(text)
ELSE statement_end_offset
END - statement_start_offset) / 2) + 1) AS sqltext
, Execution_count AS [実行回数],
last_execution_time AS [最終実行開始日時],
last_elapsed_time / 1000.0 AS [最終実行時の実行時間(ミリ秒)],
creation_time,
total_worker_time * 100.0 / (total_elapsed_time * 80.0) AS [1回あたりのCPU使用率]
FROM
sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle)
WHERE last_execution_time >= CONVERT(datetime, /11/30 01:15:45') and last_execution_time <= CONVERT(datetime, /12/01 01:17:00')
ORDER BY last_execution_time DESC

・確認してほしい点は3つです。これら3つを総合的に評価して、Indexを貼るクエリを特定します。
・実行時間が他と比べて長くないか
・実行回数が多くないか
・CPU使用率が重くないか
クエリを理解する
・今回はこんな感じのクエリを想定しています。シナリオは「とあるゲームの魔法使いプロフィール」です。
-- クエリ本文
SELECT [t0].[UserId], [t0].[UserName], [t0].[JobName], [t1].[AvailableMagic], [t1].[Consumption], [t2].[GuildName], [t3].[TitleName], [t4].[CountryCode], [s].[StateCode],
FROM (
SELECT [u].[UserId], [u].[UserName], [t].[JobName],
FROM [Users] AS [u]
INNER JOIN {
SELECT [j].[JobCode], [j].[JobName]
FROM [Jobs] AS [j]
WHERE ([j].[Delete] = CAST(0 AS bit)) AND ([j].[JobCode] = @__job_code_0)
} AS [t] ON ([u].[JobCode] = [t].[Code])
WHERE (([u].[Original] IS NOT NULL)) AND ([u].[Delete] = CAST(0 AS bit))
ORDER BY [u].[CreateDate], [u].[Original]
OFFSET @__p_1 ROWS FETCH NEXT @__p_2 ROWS ONLY
) AS [t0]
INNER JOIN (
SELECT [m].[WizardId], [m].[AvailableMagic], [m].[Consumption], [m].[WizardGuildCode], [m].[RewardTitleCode], [m].[WizardCountryCode]
FROM [Magics] AS [m]
WHERE [m].[Delete] = CAST(0 AS bit)
) AS [t1] ON [t0].[Id] = [t1].[WizardId]
LEFT JOIN (
SELECT [g].[GuildCode], [g].[GuildName]
FROM [Guild] AS [g]
WHERE [g].[Delete] = CAST(0 AS bit)
) AS [t2] ON [t1].[WizardGuildCode] = [t2].[GuildCode]
LEFT JOIN (
SELECT [r].[TitleCode], [r].[TitleName]
FROM [RewardTitles] AS [r]
WHERE [r].[Delete] = CAST(0 AS bit)
) AS [t3] ON [t1].[RewardTitleCode] = [t3].[TitleCode]
LEFT JOIN (
SELECT [c].[CountryCode], [c].[CountryName], [c].[StateCode]
FROM [Countries] AS [c]
) AS [t4] ON [t1].[WizardCountryCode] = [t4].[CountryCode]
LEFT JOIN [States] AS [s] ON [t4].[StateCode] = [s].[Code]
ORDER BY [t0].[CreateDate], [t0].[Original]
・まず利用者テーブルに役職をJOINして、その後順に魔法使いテーブル、所属ギルドテーブル、称号テーブル、所在地テーブルをJOINした後、作成日付とOriginalという元々のIdが入るカラムでORDER BYしている感じです。この中で@__○○というものがあるのに気づきます。これはBackend側で値を入れる変数で、このまま流してもSQL Serverでは動いてくれません。なので、DECLAREで変数を定義してあげます。
-- 関数定義
DECLARE
@__job_code_0 int = 3,
@__p_1 int = 0,
@__p_2 int = 1000
・上から順に、役職のコード、最初のレコード、最後のレコードといった感じです。クエリによって登場する変数が違うので注意してください。@__job_code_0には3、 @__p_1, @__p_2は0~1,000行とします。
・これ以外の場合は該当のテーブルの型を確認して仮の値を設定するといいです。こんな感じで調べられます。
exec sp_columns @table_name = [Users]
・最新のクエリ文はこんな感じです。
-- 関数定義
DECLARE
@__job_code_0 int = 3,
@__p_1 int = 0,
@__p_2 int = 1000
-- クエリ本文
SELECT [t0].[UserId], [t0].[UserName], [t0].[JobName], [t1].[AvailableMagic], [t1].[Consumption], [t2].[GuildName], [t3].[TitleName], [t4].[CountryCode], [s].[StateCode],
FROM (
SELECT [u].[UserId], [u].[UserName], [t].[JobName],
FROM [Users] AS [u]
INNER JOIN {
SELECT [j].[JobCode], [j].[JobName]
FROM [Jobs] AS [j]
WHERE ([j].[Delete] = CAST(0 AS bit)) AND ([j].[JobCode] = @__job_code_0)
} AS [t] ON ([u].[JobCode] = [t].[Code])
WHERE (([u].[Original] IS NOT NULL)) AND ([u].[Delete] = CAST(0 AS bit))
ORDER BY [u].[CreateDate], [u].[Original]
OFFSET @__p_1 ROWS FETCH NEXT @__p_2 ROWS ONLY
) AS [t0]
INNER JOIN (
SELECT [m].[WizardId], [m].[AvailableMagic], [m].[Consumption], [m].[WizardGuildCode], [m].[RewardTitleCode], [m].[WizardCountryCode]
FROM [Magics] AS [m]
WHERE [m].[Delete] = CAST(0 AS bit)
) AS [t1] ON [t0].[Id] = [t1].[WizardId]
LEFT JOIN (
SELECT [g].[GuildCode], [g].[GuildName]
FROM [Guild] AS [g]
WHERE [g].[Delete] = CAST(0 AS bit)
) AS [t2] ON [t1].[WizardGuildCode] = [t2].[GuildCode]
LEFT JOIN (
SELECT [r].[TitleCode], [r].[TitleName]
FROM [RewardTitles] AS [r]
WHERE [r].[Delete] = CAST(0 AS bit)
) AS [t3] ON [t1].[RewardTitleCode] = [t3].[TitleCode]
LEFT JOIN (
SELECT [c].[CountryCode], [c].[CountryName], [c].[StateCode]
FROM [Countries] AS [c]
) AS [t4] ON [t1].[WizardCountryCode] = [t4].[CountryCode]
LEFT JOIN [States] AS [s] ON [t4].[StateCode] = [s].[Code]
ORDER BY [t0].[CreateDate], [t0].[Original]
実際にDBへクエリを流す場合
・このフェーズで使用しているスクリーンショットはダミーデータなので、雰囲気だけ掴めればOKです。
・実行する前に、プラン表示をONにしておいてください。

・該当のDBを右クリックするか、↑のスクショの左側にある項目から「新しいクエリ」を選択し、クエリを貼り付けて「実行」を選択します。
・この時点で結果にレコードが表示されない場合、DECLAREを間違えている可能性があるので注意してください。実行プランを確認してみます。ここに不足しているIndexが表示されている場合、それは基本的にそのまま貼ってもいいものなので、貼って検証してみてください。SQLプランで右クリックすることで、不足しているIndexを追加する項目を表示できます。

・今回は、仮にコストの49%を占めるリーフノード(SQLプランの端)がIndex Scanになっていたとします。これがIndex Seek(Non Clustered)になっていない場合、基本的にはチューニングの余地があると言えます。ここにIndexを貼っていきましょう。

Indexを作成する
・まっさらな状態のIndexはこんな感じですよね。
CREATE NONCLUSTERED INDEX [IDX_Name] ON [dbo].[Table] (
[Column1] ASC,
[Column2] ASC,
[Column3] DESC
) INCLUDE(
[Column4],
[Column5],
[Column6]
) WITH (
STATISTICS_NORECOMPUTE = OFF,
DROP_EXISTING = OFF,
ONLINE = OFF,
OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF
) ON [PRIMARY]
GO
・まずはIndexを貼るテーブルを選定します。今回は一番最初にSELECTが来ているUsersのテーブルに貼っていきます。
CREATE NONCLUSTERED INDEX [IDX_Name] ON [dbo].[Users] (
・次にON句を選定していきます。ON句の時に追加したいものは↓のようなカラムです
・貼るテーブルのSELECTのWHERE句や最終的なORDER BY句に書かれているもの(今回で言うとDelete、Original、CreateDate)
・他テーブルのJOINで使われているもの(今回で言うとUserId)
・ASC, DESC(昇順、降順)をどちらにするかというと、少ないほうが先にくるようにする(Deleteがbool型の0, 1(true, false)だとして、0が1千万行、1が5千万行だとすると、0の方が少ないのでASC)
・DECLAREしてる変数に関連するものであっても、変わらずON句に含める(今回の場合はJobCodeだが、違うテーブルなのでスキップ)
CREATE NONCLUSTERED INDEX [IDX_Name] ON [dbo].[Users] (
[Delete] ASC,
[Original] ASC,
[CreateDate] ASC,
[UserId] ASC
) INCLUDE(
・最後に、INCLUDE句を選定していきます。INCLUDE句に追加したいものは↓のようなカラムです
・貼るテーブルの最終的なクエリ結果で出力される(SELECTに書いてある)カラム(今回で言うとUserId, UserNameだが、UserIdはON句で使ってるので除外)
CREATE NONCLUSTERED INDEX [IDX_Name] ON [dbo].[Users] (
[Delete] ASC,
[Original] ASC,
[CreateDate] ASC,
[UserId] ASC
) INCLUDE(
[UserName]
) WITH (
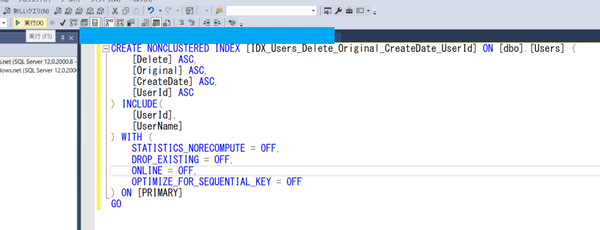
・最新のIndexはこんな感じです。命名規則としては、[IDX_<テーブル名>_<ON句のカラム>]
CREATE NONCLUSTERED INDEX [IDX_Users_Delete_Original_CreateDate_UserId] ON [dbo].[Users] (
[Delete] ASC,
[Original] ASC,
[CreateDate] ASC,
[UserId] ASC
) INCLUDE(
[UserName]
) WITH (
STATISTICS_NORECOMPUTE = OFF,
DROP_EXISTING = OFF,
ONLINE = OFF,
OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF
) ON [PRIMARY]
GO
・Indexを貼る場合は、該当のDBを右クリックするか、SSMS上部の左側にある「新しいクエリ」を選択して、クエリを貼り付けて実行すればOKです。
貼った後の実行プランを見比べる
・スクリーンショットはダミーデータなので、あくまで「こんな感じに削減されていればいいな~」という目安として考えておいてください。
・コストを比べてみます。元々の内容はこんな感じでした。
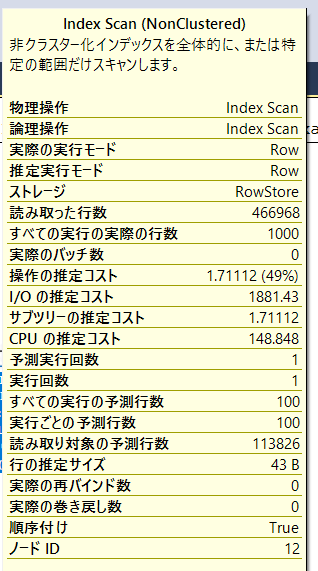
・貼った後はこんな感じです。

・分かりにくいですが、操作の推定コストが49%から36%に減少していること(1.7から1.0くらいに)、読み取り行数が11万行から9万5千行に減少しています。
・この結果でいくと実行時間もある程度高速化していると予測できます。残念ながらIndex Seek(Non Clustered)にはなってくれませんでしたが、上記のような結果だとすると効果はあるといえるはずです。
終わりに
今回は実際のクエリ文にIndexを作成してみました。Indexの作成にはDBに貼られているIndexやカラム型、レコード数など様々な要素が関わってくるかと思われますので、あくまで指標の一つとして考えていただければと思います。SSMSのUIやsqlプランの詳しい見方を深堀りできなかったので、気が向いたらまた記事を書こうと思います。ドラクエXII(12)とIX(9)のリメイクを心待ちにしている藤野でした。うおおおおおぉぉぉっっっ!!!
藤野 元規/FIXER
(ふじの もとき)
2022年度からFIXERに入社しました。好きな言語はTypeScriptのComposition APIです。フルスタックエンジニアを目指して、日々精進していきたいです(願望)
本記事はアフィリエイトプログラムによる収益を得ている場合があります