




Foveros Directの第2世代は
Bump Pitchが9μmになる
次が(4)のFoveros Directについて。連載第682回では「9μmピッチかどうかは将来公開する」という話だったが、今回ついにこれが9μmであることが明示された。
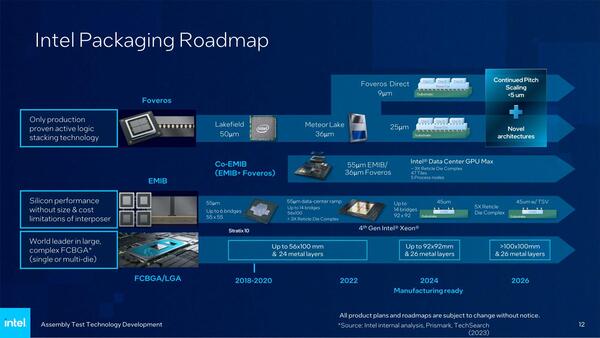
1ページ目2枚目の写真には“<10μm”とあるBump Pitchだが、こちらのスライドではついに9μmと明示された
ちなみにこの先に関して言えば、Foverosは微妙だがFoveros Directは5μm未満のBump Pitchを目指していることも今回示された格好だ。
ガラスベースのSubstrateと
Co-Package Opticsが提供予定
最後が(5)の次世代インターコネクト向け。これは要するに、より高速な信号を通すための仕組みである。現在ではPCIeやUCIeでもだいたい32Gbpsあたりが信号速度のピークであり、GDDRも20Gbpsくらいであるが、すでにイーサネットの世界ではレーンあたり100Gbps(56G PAM-4)を超えて200Gbps(112G PAM-4)に対応したチップがサンプル出荷を開始しており、さらにこの先の400Gbps(224G PAM-4)も視野に入り始めた。
ちなみにこれは1レーンあたりの速度である。PCIeもPCIe 6.0ではレーンあたり64Gbps(32G PAM-4)、PCIe 7.0は128Gbps(64G PAM-4)になることが決まっており、より高速な信号をハンドリングする必要がある。
こうした高速な電気信号を扱うのに、従来の基板材料では損失が大きすぎて到達距離が稼げないということで、ガラスベースの基板は従来からいろいろ検討されてきているのだが、ここにきてインテルがパッケージオプションでガラス基板に言及し始めた、というのはもう他に方法がないということもあるが、ガラス基板にまつわる問題(温度変化に起因する歪がLSIチップと異なることによる問題や強度、製造方式など)にある程度目途が立った、ということかもしれない。
これに絡んでくるのがCo-Package Opticsである。イーサネットそのもので言えば、現状標準化されている銅配線ベースの最大速度は100Gbps(ただしド太い同軸ケーブルを複数使い、配線距離も数m)、CAT-8を使う配線では40Gbps(40GBASE-T)が一番最高速であり、それ以上高速なイーサネットはすべて光ファイバーを使う形になる。この場合のトランシーバーの構造が図3である。
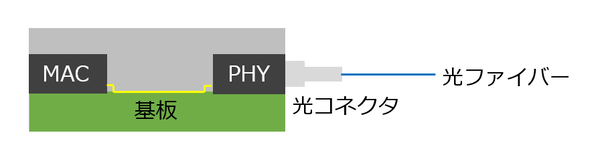
図3
MACはデジタル電気信号の形でイーサネットの入出力を行ない、これをアナログに変換した上で光信号の形で入出力するのがPHYである。この2つは基板上でつながることになるので、ここの信号の高速化のためにガラス基板を使おう、という話である。
実際大規模なスイッチなどでは、こうした構造になる可能性が非常に高い。ただここで図4のようにMACとPHYを同一パッケージ内に押し込めれば、もっと効率が良くなる。
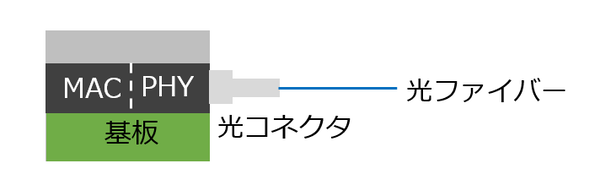
図4
ただMACまでは通常のCMOSプロセスで製造されており、一方PHYの方にはレーザーLEDやフォトディテクターなど通常のCMOSプロセスでは製造できないコンポーネントが含まれる。したがってPHYをCMOSプロセスと親和性のある方法で製造する必要がある。
Silicon Opticsと呼ばれるこの新技術をインテルはもうかれこれ20年くらい手掛けており、連載699回でも触れたように、2022年のIEDMの基調講演の中で2025年までにPluggable Opticsのソリューションを提供する予定であることが公表されている。

2025年までにPluggable Opticsのソリューションを提供する
今回のCo-Package OpticsはこのPluggable Opticsのソリューションのためのものである。上の図に戻ると、PHY/MACが一体化したチップに光コネクターが接続されているが、現在業界には標準的な「LSIに直接接続するための」光コネクター/レセプタクルというものが存在しない。
これは精度(なにしろ光ファイバーが細いので、きちんとLED/フォトディテクターと位置合わせができないと効率が急激に落ちて通信不能になる)など強度の点で難易度が高く、けっこうがっちりした金属製のコネクター/レセプタクルが利用されているためであり、LSIチップの10倍くらいの厚みがあったりするからまるで適さない。
今回インテルが発表したのは、やや厚みのあるLSIに直接接続できるようなコネクター/レセプタクルである。こちらのサンプルは今年後半に詳細が明らかにされるようだ。
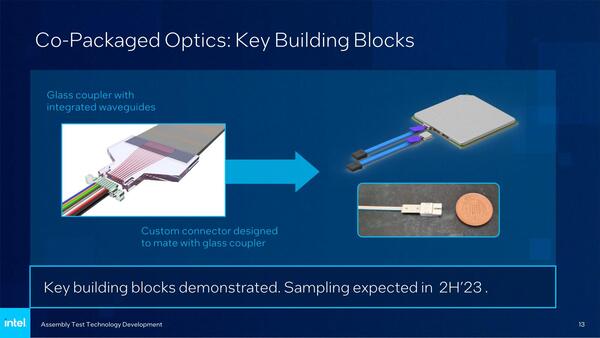
大きさ的にはUSB Type-Cコネクターとほぼ同じ程度、という話だった。ここに8列×2段で16本の光ファイバーを通せるらしい
ということで、インテルのパッケージ技術は相変わらず進歩を続けており、今後のプロセスの進化にも対応できるようになっている、という話であってそのことそのものは良いのだが、問題はなぜこの時期にこんな話を突然したのか? である。これがなにかの目くらまし、という話でなければいいのだが……。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ















の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















