
9月30日より、Ryzen 7000シリーズの店頭発売が開始された。いきなりAMDマニアの林先生がTSUKUMOeX.の店頭に並んでいてさすがと思った、という話は置いておいて……。
すでにKTU氏による性能ベンチマークが公開されているので、その性能と消費電力の評価結果は記事をお読みいただければと思う。大雑把にまとめると、「性能も上がったが消費電力も上がった」というあたりである。
消費電力の方は、1つにはチップセット(X670Eの場合、2チップ構成になっている)が理由でもあるが、基本的には5nmプロセスを省電力化に振るのではなく、動作周波数向上の方に振ったのが最大の要因であろう。
一方の性能の方だが、これが以前説明したよりも、もう少し踏み込んだ情報が説明されたので、このあたりを今回説明しよう。まずZen~Zen 4の変遷をまとめたのが下の画像だ。

Zen世代のIPC向上率はExcavatorからのもの。とりあえずZen世代を基準にしても、Zen 4ではおおよそ54.6%ものIPC向上が実現したこと(Excavator比なら135.1%もの向上)になる
Zen 4では13%のIPC向上、と説明されているが、その内訳はこれまで明らかにされてこなかった。さてその内訳であるが、Zen 4のマイクロアーキテクチャーが下の画像だ。
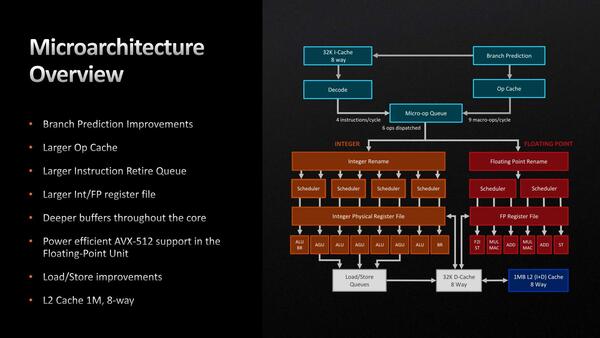
左にもう少しいろいろ書いてあるが、それは後述する
ちなみにZen 3のマイクロアーキテクチャーが下の画像である。見比べてみると、実は実行ユニットの数などはまったく同じで、デコード段は4命令/cycleの速度でx86命令を解釈するのも、Dispatch Unitからは最大6命令/サイクルで発行されるのも同じである。
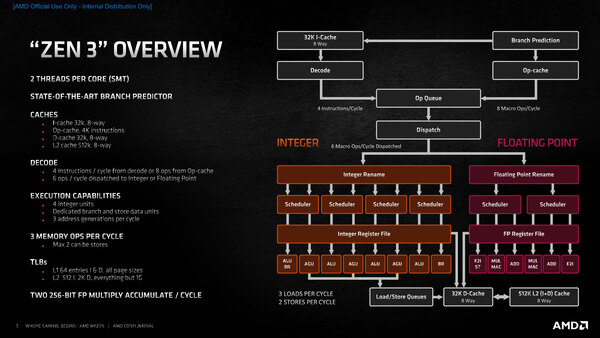
Zen 3のマイクロアーキテクチャー
スケジューラーの入り方もZen 3とZen 4はまったく同じである。ただ実はここにも少し書いてあるが、Op CacheからMicro-op Queueへの帯域が、Zen 3の8 MacroOps/サイクルからZen 4では9 MacroOps/サイクルに増強されている。
要するに8 MacroOps/サイクルの命令供給では、依存関係を解消しての6命令同時発行を十分に生かし切れておらず、この効率向上を目的としたものと考えられる。
もう少し細かく見てみよう。まずフロントエンドだが、基本的な構成は変わらないものの以下のような変更点がある。
- Op Cacheが4K Opsから6.75K Opsと大幅に増量され、かつOp CacheからMicro-op Queueへの帯域が8 Ops/cycle→9 Ops/cycleに拡大された。
- 分岐予測に利用するBTB(Branch Target Buffer)が、L1が2×1K Entry→2×1.5K Entryに、L2が2×6.5K Entry→2×7K Entryにそれぞれ大型化された。
BTBが2×なのは、Zenでは同時に2スレッドを実行できるから、それぞれのスレッド用に別々のBTBが用意されるためである。BTBに限らずキャッシュ類は一般に、大型化するとそれだけHit率が上がる(=BTBなら正しく飛び先を認識しやすい)一方で、大型化の弊害としてレイテンシーが増えやすい(大きくなると、それだけテーブルを全件検索するのに時間がかかる)という弊害もあるが、おそらくこの程度では目立って遅くはならないだろう。
ただBTBも構造的にはキャッシュやRegister Fileと同じくSRAMで構成されるから、大型化するとそれだけエリアサイズを喰ってしまう。このあたりはZen 3→Zen 4でプロセスを微細化したことで、多少ゆとりができたことで実現したと考えられる。といったあたりだ。ちなみに“Predict 2 taken branches per cycle”そのものはZen 3の時点ですでに実現されている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ













