




CPUとPCHの統合でダイサイズが肥大化
KTU氏による発表記事のスライドにもあるように、少なくとも論理的にはCPU本体とTiger Lake PCH-HというPCHが別々に存在し、間がDMI 3.0×8で接続される構造になっているが、物理的には(Ryzen Gなどと同じように)ワンチップ化したことになる。
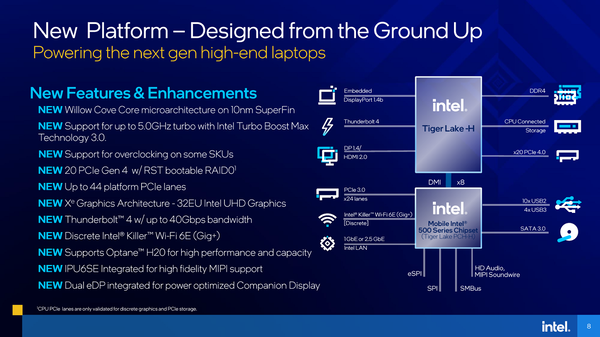
Tiger Lake-H+インテル500シリーズチップセットを組み合わせた時のブロック図。CPUとPCHを統合しワンチップ化している
ワンチップ化そのものは別に珍しい話ではなく、これまでも例えばGoldmontベースのApollo Lakeなどは1つのダイにCPUとPCHを統合していたので、これが初めてというわけではない。強いて言うなら、PCHに10nmプロセス(それも10nm SuperFin)を使ったのはこれが初めてというあたりだろうか。
PCHのエリアに関してはわりと適当である。3つ前の画像では、ダイ左上に全体の8%程度の面積として入れてあるが、もう少し小さいかもしれない。というのは、上の画像の図にもあるように、Tiger Lake PCH-Hの機能は限られているからだ。
まずIntel Killer Wi-Fi 6Eはディスクリートなので、実際はPCIeの先に拡張カードの形で接続される。またSATA 3.0は一応あるにはあるが、ポート数自体は1か多くても2ポートだろう。
ノート向けであればそもそもSATAポートが多数用意される必要がない。もう最近はDVD-ROMドライブを搭載する機種も激減したし、せいぜいがデータ用にSATA SSDを拡張できるポートがあれば十分というあたり。性能が必要な場合はNVMe SSDを使えばいいからだ。
仮になにか特殊な理由でOEMがどうしても多数のSATAポートが必要というなら、ポートマルチプライヤーを使ってSATAポートを増やすこともできるから、これはOEM側だけで対応できる。となると、PCIeレーンとUSB、1/2.5GbE、HD Audio、SMBus、SPI/eSPIあたりがあればいい。
USB 3までであればすでに実績のあるコントローラーが多数あるし、エリアサイズも小さい。PCIeはさらに簡単で、Root Complex(PCIe全体を制御する部分)はホスト(つまりTiger Lake-Hのアンコア部)に搭載されているから、PCHの側は単にPCIeスイッチが入っているだけである。
その他のI/Fもあまりエリアサイズを喰いそうなものはないので、上で8%ほどのエリアサイズと推定はしたものの、実際には5~6%で収まっている可能性もある。
余談になるが、通常PCHは結構なエリアサイズを喰う。理由はアナログ回路に必要な受動部品(特にコイルとコンデンサー)は微細化と無縁(どうしてもそれなりのサイズが必要)なためだ。ただTiger Lake PCH-Hではこうしたアナログ回路がほとんど搭載されていないようで、そのあたりも統合できた理由かもしれない。
もっともこれは言い方を変えれば、インテルはアナログ部品まわりは鬼門で、これまでもいろいろな不具合を出しまくっているだけに、極力PCHにアナログ回路を含まない方向にシフトしているようで、そうしたことも結果的にPCH統合に貢献しているのはなんというべきか。
これはインテルだけでなくAMDや昨今のARM SoCも同じで、プロセッサー性能を引き上げる&製造コストを引き下げるためにはなるべくチップセットの類を1つのダイに統合する必要があるが、その一方で先端ロジックプロセスは、あまりアナログ統合が得意ではない。
であれば、アナログ部品がどうしても必要なら別チップに切り出す方向で、なるべくデジタル回路(とデジタルI/F)だけでチップセットを完結させる方向にシフトしつつある。その意味でもインテルの方向性は間違ってはいないのだが。
話を戻すと、このPCHを統合したことも、ダイサイズの肥大化に一役買っているのは疑う余地もない。それでもCPU+PCHで2ダイになったTiger Lakeとどちらがコスト的に有利か、は微妙なところである。

Tiger Lakeは2ダイ構成だった。左がUP3(TDP 12~28W)のSoCパッケージで、右がUP4(TDP 7~15W)のSoCパッケージである
訂正:記事公開後にインテルが仕様を公開し、Tiger Lake-HのPCHは統合されておらず、別チップであると判明しました。詳細は連載617回で説明しておりますので、そちらをご参照ください。(2021年5月31日)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ














ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")
















