




HBM2を使う通常のGPUと比較すると
処理性能は2.1倍、消費電力は71%削減
さてそのPCUの処理であるが、命令はわずかに9個。うち演算命令は4個のみである。データ型はFP16に限られており、加算・乗算・乗加算・積和演算のみである。あとはデータのロードや「セーブで、対象はDRAMセルか、他のレジスターでしかない。
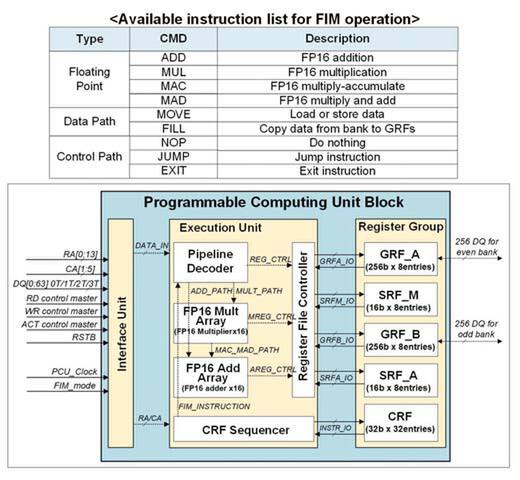
PCUの命令はわずかに9個。どうもJUMPというのは無条件ジャンプではなく条件分岐の模様だ
畳み込みニューラルネットワークであれば畳み込みの処理「だけ」しかできないので、プーリングやアクティベーションなどはホストに戻して処理する必要がある。ただ逆に言えば、畳み込みに関してはなにしろデータを(CPUに)ロードする必要がない。
例えば最初はノーマルモードとし、奇数バンク(Bank 1/3/5/7/9/11/13/15)には共通の重みデータを格納し、偶数バンクには入力の画像データをロードしておき(ここまではHBMとして動作)、そこからFIMモードに切り替えて1GB分の入力データの畳み込み処理を行ない、その結果をDRAMセルに書き戻す。
その後再びノーマルモードに戻して、畳み込みの結果をまとめてロードすればいい。CPUで順次演算するよりも圧倒的に高速であり、しかも省電力である。
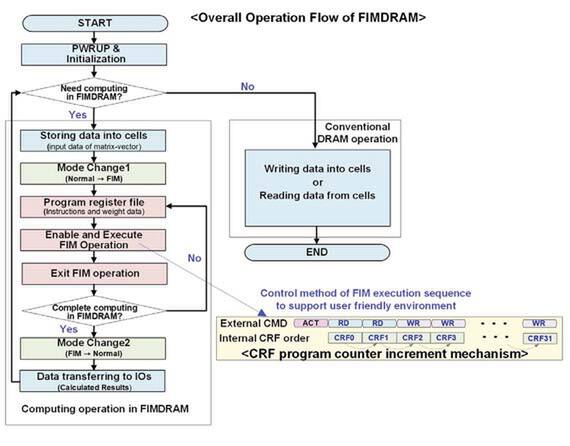
動作の流れ。条件分岐だが、どうやって条件を与えるのかは不明。プログラムそのものは上の画像のCRF(Command-Register File)に最大32命令まで蓄積できるので、それほど複雑なプログラムは実行できない(その必要もないだろう)
ちなみにこのCRF経由で与える命令はCMD Bus経由でロードする形になるので、仮に32命令を超えて複雑なことをしたいと思ったら、まずFIMモードに入って最初の命令群を実行させ、それが終わったらもう一回FIMモードに入って次の命令群をロードして続きをやらせることになる。
論文を読む限りは、すべてのPCUには共通の命令が与えられることになり、一斉に処理する格好になる。なお、前述のHBM構成の画像にあるのは、HBM2の1chあたりの図であるが、実際にはHBM2のダイは2ch構成なので、これが倍になる。
各々のPCUはFP16の乗算×16とFP16の加算×16という2つのSIMDエンジンがつながっている格好なので、実際には1ダイあたり32個のPCUが搭載される。ということは、ダイあたり512wideのSIMDエンジンが2つで300TFlopsという計算になる。実際のHBM-PIMは8スタックであり、その内訳は以下の通り。
- 容量8GbitでPCUを持たないダイ×4スタック
- 容量4GbitでPCUを搭載するダイ×4スタック
トータルとしての容量は6GBで、1.2TFlopsの処理性能を持つメモリーチップの出来上がりである。
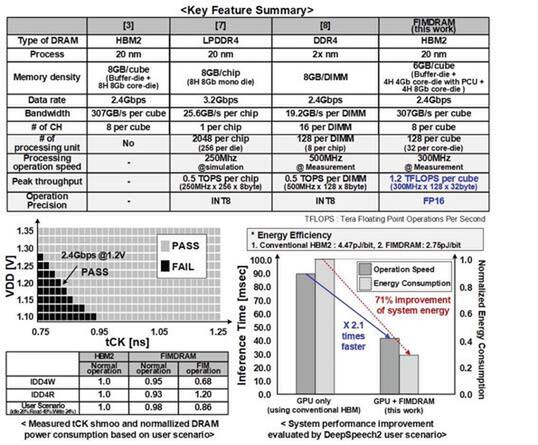
1.2V駆動であれば問題なく2.4Gbps(=PCUは300MHz駆動)が可能とのことだ
HBM2を使う通常のGPUで処理した場合と比較し、この畳み込みをPCUで行なった場合には、処理性能が2.1倍になり、それでいてシステム全体の消費電力は71%削減できたとしている。
なにしろ計算処理で一番多いのが畳み込みだから、ここの性能を改善&消費電力削減できれば、全体への貢献は大きいことになる。製造プロセスそのものは20nmだそうで、2GB分のメモリーの代償としての1.2TFlopsの演算性能は、バーターとしては悪いものではないように思う。
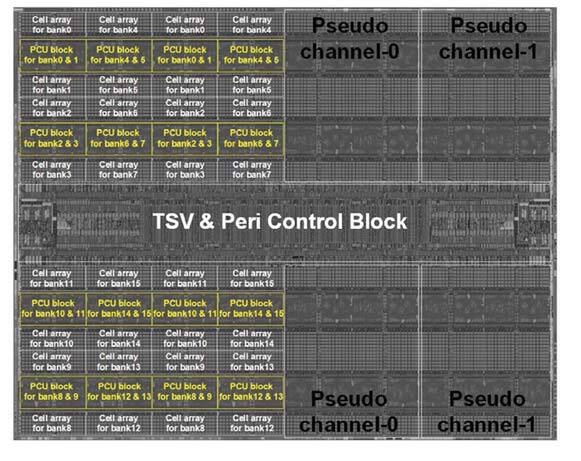
これはPCUありのダイの構成。左がChannel 0、右がChannel 1である
今回のものはあくまでも研究レベルの話で、今すぐこれで製品を実用化できるものではない。研究レベルであれば問題ないが、実際にこれを利用するためには開発環境と稼働環境について、OSレベルから手を入れる必要がある(少なくとも今のLinuxのままでは動作しない)。
ただ、AIプロセッサーの方向性の1つとして、こうしたものは今後も出てくるとは思うが、その極端な例と考えてもらえれば間違いないだろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ














の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



















