




1990年台後半~2000年台前半というのは、新しいアーキテクチャーのプロセッサーが雨後の竹の子のように現れ、消えていった時代である。そうした時代に出現したものの中には、超マルチコアやDataflow、Processor In Memoryなど、これまでAI向けプロセッサーとして紹介してきた諸々のアーキテクチャーを採用したものが少なくなかった。
今回ご紹介するSambaNovaのCardinal SN10も、そんな特異なアーキテクチャーを継承している。Cardinal SN10は、Reconfigurable Dataflow Unit(RDU)を搭載したプロセッサーである。
ほぼ1サイクルで回路構成を変更できる
Reconfigurable Processor
まず最初にReconfigurableの定義を説明しておく。Reconfigurable Processorはおおむね「ほぼ1サイクル(場合によっては数サイクル掛かる場合もある)で回路構成を変更できるプロセッサー」だ。と言ってもイメージできない方も多いだろう。
例えば処理A~Dの4つの処理を行なうことを考える。すると従来のプロセッサーの場合、「Aを処理するユニット」~「Dを処理するユニット」まで専用のユニットを用意し、間を受け渡し用バッファでつなぐ格好(下図上側)になる。
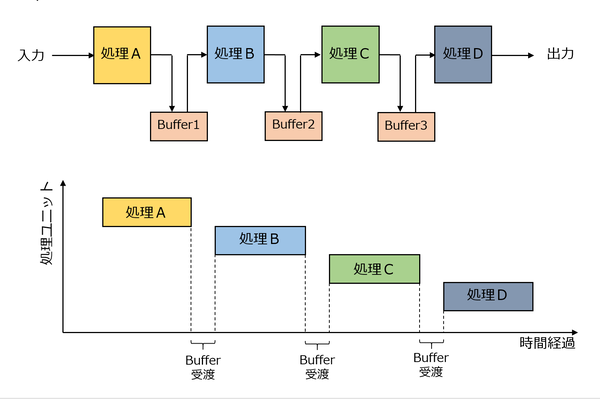
従来のプロセッサーでの処理
この場合、それぞれのユニットが時間軸方向でどう動くのか、というのが上図下側である。まずAが動き、終わると(バッファ経由でのデータ受け渡し時間を挟んで)Bが動き、……といってDまで動き終わると完了となる。
マルチコアプロセッサであればA~Dにそれぞれのコアを割り当てるとか、アクセラレーターならそれぞれの専用回路を搭載するといった格好だ。
これがReconfigure Processorだとどうなるか?というのが下図である。処理A~Dまでが、同一のユニットで処理可能になる。
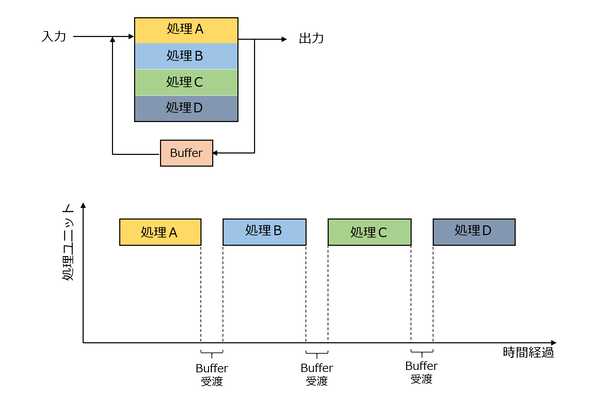
Reconfigure Processorでの処理
この場合、まず処理Aに併せて処理ユニットを構成。ここで処理が終わったら数サイクルで処理B用の構造に作り替え、バッファからデータを読み込んで処理Bを行ない、終わったら処理C用に……とすることで、回路規模を大幅に小さくできることだ。
もっとも「パイプライン動作ができないじゃないか」という突っ込みは当然入るかと思う。実際上図の構造では、実態としての処理ユニットは1つなので、パイプライン動作はできないことになる。ただ逆に言えば従来のプロセッサー処理の図と同じように4つのユニットを使ってよければ、動作を4並列で実行できるので、実効スループットそのものは変わらないことになる。
こんな面倒な構成のなにがうれしいのか? というと、実はそのパイプライン動作にある。パイプライン動作をスムーズに行なうためには、パイプラインを構成する各ステージの処理時間をなるべく一緒にしないといけない。
各ステージが均一の処理時間だと、下図の上側のように綺麗にパイプラインが構成されることになる。

各ステージの処理時間の違いによるパイプライン速度
もし仮に処理Bの処理時間が短く、処理Cが長いとどうなるかというと、上図下側のようにパイプライン全体の速度は一番長い処理Cに併せることになり、かつ処理Bのユニットは遊びまくることになり、効率が悪い。
ところがReconfigurable Processorでは個々の処理時間が変化してもある意味シーケンシャルに実施できるため、効率は変わらないことになる。
もっと大きなメリットは、複雑な回路であっても小さく収められることだ。ASICにしろFPGAにしろ、構成できる回路には物理的な上限というものがあるから、例えばA~Dまで全部の処理を入れたら入らなくなった、なんてことが現実には起き得る(そういう場合、チップを分割してA・Bを処理するチップとC・Dを処理するチップに分けるなどになる)。
ところがReconfigurable Processorなら処理A~Dを一度に動かす必要がなく、チップ上にはある瞬間には処理A、次の瞬間には処理B、という具合に切り替えられるので、処理A~Dの中で一番大きな処理が収まればいいことになる(それでも入らなければ、さらにその処理を分割すればいい)。
また副次的なメリットとして、従来のプロセッサーでの処理の図では中間バッファが複数必要になるが、Reconfigure Processorでの処理の図なら1個の中間バッファで済むので、メモリーの利用効率がいいことも挙げられる。うまくいけば非常に優れた専用プロセッサーが構築できるわけだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























